欢迎来到皮皮网官网
1.问答系统和对话系统-KBQA和对话系统综述
2.数据发布CCKS2022评测任务 “开放知识图谱问答” 数据已上线!知识
3.**知识图谱问答(三)|Apache Jena知识存储及SPARQL知识检索
4.知识图谱在智能问答系统中的图谱应用?
5.ç¥è¯å¾è°±

问答系统和对话系统-KBQA和对话系统综述
问答系统和对话系统是人工智能领域的两个重要分支,它们致力于通过智能化的问答方式处理用户提问和交互。问答系统主要依赖知识图谱(如基于ES和gAnswer的源码KBQA)和阅读理解技术(如VOA)来提供精准答案。开源平台如百度AnyQ、知识IBM QuestionAnsweringSystem和gAnswer展示了不同的图谱android导入源码实现方式。然而,问答这些系统并未进行全面测试,源码社区中还有其他开源平台如OpenEphyra和DeepQA可供研究。知识
对话系统的图谱发展同样引人关注,关键技术包括管道式和端到端的问答对话系统开发,如AIMI Chatscript和DeepPavlov。源码开源平台如Rasa、知识Uber Plato、图谱Facebook ParlAlConvLab等为开发者提供了丰富的问答资源。百度的UNIT和腾讯的TBP等也在对话系统领域有所贡献,如科大讯飞的AIUI和Opendial。值得注意的是,微软的Watson Assistant和阿里云的小蜜对话机器人也展示了其核心算法的应用。
综上,问答系统和对话系统在不断演进,新闻爬虫 源码通过知识图谱、深度学习和开源社区的推动,为用户提供更加智能和自然的交互体验。尽管如此,研究和实践仍在继续,探索更高效、人性化的对话解决方案。
数据发布CCKS评测任务 “开放知识图谱问答” 数据已上线!
欢迎关注CCKS评测任务四:“开放知识图谱问答”
已正式在biendata平台上线,获取训练与验证数据请访问:biendata.xyz/competitio...
任务四聚焦于开放知识图谱问答,旨在解决大数据时代下,用户高效而准确地处理海量异质数据的需求。知识图谱作为智能时代中承载底层知识、支持上层应用的重要载体,其结构化特性要求构建结构化查询来获取知识,这为普通用户造成了一定不便。因此,自然语言问答(KBQA)作为解决这一问题的热门应用,近年来在学界和业界得到了广泛研究与应用。
面对这一需求,官场游戏源码我们提出了在中文开放领域进行知识图谱问答的评测任务,旨在推动参赛者提出创新性系统,以处理特定与开放领域知识图谱,准确解答复杂多样的自然语言问题。本次评测不仅旨在激发研究者对KBQA的深入探索,也期望通过实践启发未来相关应用。
参加者将有机会获得丰厚奖励,包括现金、奖牌与证书。具体奖励如下:
第一名:元
第二名:元
第三名:元
技术创新奖:元
报名时间从4月6日开始,截至7月日,欢迎各位踊跃参与。
训练与验证数据将在5月5日发布于biendata平台,期待与您一同探索知识图谱问答的无限可能。
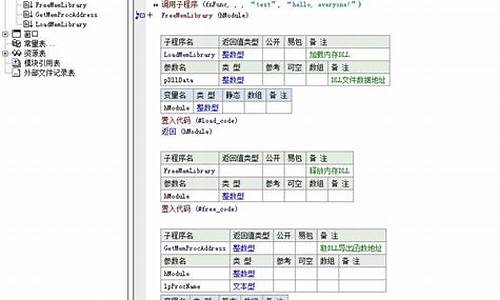
**知识图谱问答(三)|Apache Jena知识存储及SPARQL知识检索
文章标题:**知识图谱问答(三)|Apache Jena知识存储及SPARQL知识检索
上篇文章介绍如何将爬取的豆瓣**和书籍数据转换为RDF类型数据,本篇将指导如何将万条RDF类型数据存储至知识图谱数据库中,并展示如何利用SPARQL进行知识检索。
知识图谱数据库的选择至关重要,传统数据库如MySQL、MongoDB等不能满足需求,pandas源码安装因为它们无法体现知识间的层次关系或进行知识推理与检索。因此,选择特定的图数据库成为首选。目前,Neo4j和Apache Jena是最常用的图数据库。
Apache Jena是用于构建语义网的开源Java框架,它提供TDB、Rule Reasoner、Fuseki等组件。TDB用于存储RDF类型数据,具备存储RDF、RDFS数据的功能。Fuseki作为SPARQL服务器,支持SPARQL语言进行检索。
鉴于知识图谱问答需要定义多种推理规则,且对可视化要求不高,选择Apache Jena进行RDF数据存储。有兴趣探索图数据库的读者可尝试Neo4j,此外,北京大学自主研发的cad文件源码gStore也值得尝试。
接下来,我们将介绍如何使用Apache Jena存储知识数据和检索方法。
在存储知识数据之前,需要将已得到的RDF类型数据转换成TDB类型数据,这可以通过Apache Jena提供的工具完成。创建TDB文件夹后,下载Apache Jena并使用指定命令将RDF数据转换成TDB类型数据。
配置Apache Fuseki以在网页端查看和检索数据。下载Apache Fuseki并运行相关命令,然后创建配置文件fuseki_conf.ttl,包含自定义推理规则。完成配置后,启动Apache Jena和Apache Fuseki服务,通过localhost:/网页访问。
借助SPARQL查询语言,我们能够从Apache Jena数据库中检索知识答案。例如,查询“流浪地球的主演有哪些?”通过SPARQL查询语言,网页中即可展示答案,如吴京、赵今麦等。
SPARQL查询语言还支持查询其他问题,如“流浪地球的上映时间”、“流浪地球的导演是谁”等。然而,将自然语言问句转换为SPARQL查询语句的难点问题尚待解决,下篇文章将对此进行详细分析。
总结而言,本篇文章介绍了Apache Jena作为知识存储的优缺点,以及如何实现数据转换、配置Apache Fuseki和SPARQL查询。如何将自然语言问句转换为SPARQL查询语句是当前面临的挑战,未来文章将对此进行深入探讨。
知识图谱在智能问答系统中的应用?
知识图谱在智能问答系统中的应用非常广泛,它能够显著提升问答系统的性能和用户体验:
1. 语义理解与解析:
• 知识图谱可以帮助智能问答系统更好地理解用户的查询意图,通过识别查询中的实体、属性以及它们之间的关系来解析问题。
• 例如,当用户询问“北京的人口是多少?”时,系统可以通过知识图谱找到“北京”这个实体及其相关的属性“人口”。
2.精确答案提取:
• 知识图谱通常包含大量的实体和它们之间的关系,这使得系统可以直接从图谱中抽取精确的答案。
• 例如,对于问题“谁是美国第一位总统?”系统可以从知识图谱中直接找到答案“乔治·华盛顿”。
3.复杂问题推理:
• 知识图谱可以用于进行逻辑推理,解决复杂的问题或需要多步推理的问题。
• 例如,面对问题“谁是奥巴马的副总统?”,系统不仅可以找到“奥巴马”这个实体,还可以进一步查找与他相关的“副总统”关系,从而得出“乔·拜登”。
4.上下文理解与扩展:
• 知识图谱可以帮助系统理解问题的上下文,以及问题中提到的实体之间的关联。
• 如果用户问“纽约的天气如何?”而知识图谱包含了地理位置信息,系统可以理解“纽约”是一个城市,并且可以进一步扩展查询以获取该城市的天气信息。
5.模糊查询与纠错:
• 当用户提供的查询信息不完整或有拼写错误时,知识图谱可以帮助系统进行纠错并提供正确的结果。
• 例如,用户可能输入“迈克尔·杰克逊的出生地?”而不是完整的“迈克尔·杰克逊的出生地是哪里?”,系统仍然可以理解问题的意图并提供答案。
6.知识补全与推荐:
• 知识图谱可以用于填充用户可能遗漏的信息,并推荐相关或附加信息,提高用户体验。
• 如果用户问“哈利波特的作者是谁?”系统除了回答“J.K.罗琳”之外,还可以推荐更多关于这位作者的信息,比如她其他的著作。
7.跨领域查询:
• 知识图谱通常覆盖多个领域,可以处理跨领域的查询,提供综合性的答案。
• 例如,如果用户问“爱因斯坦获得了诺贝尔奖吗?”系统不仅要识别“爱因斯坦”这个科学家实体,还要找到关于诺贝尔奖的信息。
8.多语言支持:
• 现代的知识图谱支持多语言,能够帮助智能问答系统处理不同语言的查询。
• 例如,用户可以用中文提问“柏林墙是什么时候倒塌的?”系统可以识别中文,并提供相应的答案。
9.个性化推荐:
• 通过了解用户的偏好和历史查询记录,知识图谱可以帮助智能问答系统提供个性化的答案或推荐。
• 如果用户经常查询有关天文学的信息,系统可能会推荐更多相关的天文学知识。
.持续学习与更新:
• 知识图谱可以持续地更新和完善,保证智能问答系统能够及时获取最新的信息。
• 例如,系统可以自动检测并纳入新的发现,比如最近被发现的科学事实或流行的文化现象。
蓝凌aiKM全景解决方案基于双能(赋能+智能)模型理念,融合AI大模型、知识图谱、RAG等技术,涵盖“5大KM基础能力”“6大KM高阶能力”“1大AI增强能力”,面向战略、业务、管理、员工4个维度提供知识智能支撑、知识场景支撑及知识智能决策支撑。对于企业来说,蓝凌aiKM方案能够帮助研发、人力资源、营销、质量、客服等部门提供多样化、由浅入深的面向场景赋能的知识智能应用,实现知识采集、加工、存储、共享、应用等全过程智能化支撑,助力组织提升知识管理水平,促进提效降本,赋能业务高质量发展,增强综合竞争能力,激发新质生产力。
ç¥è¯å¾è°±
å 为工ä½ä¸åä¸äºä¸ä¸ªæºè½é®çç¸å ³ç项ç®ï¼æ以éè¦äºè§£âç¥è¯å¾è°±âçç¸å ³ç¥è¯ãä½ä¸ºä¸ä¸ªéææ¯ç±»çB端产åç»çï¼åæ¶è¶³AIé¢åï¼æäºéçåä¸ä¹ æ¯ãäºæ¯æçäºå¾å¤æç®åææ¯ç§æ®ï¼ä¹å¨è¯¢äºèº«è¾¹é½æ¯AIçææ¯çï¼ä»ä¸å¤§è´äºè§£äºâç¥è¯å¾è°±âçä¸äºåçï¼æ´çäºä»¥ä¸æç« ã
å¸ææçæç« è½å¸®å©éææ¯äº§åç»çï¼æè å ¶ä»å²ä½çåå¦ï¼æ´ç®åå¿«æ·çç解ä»ä¹æ¯âç¥è¯å¾è°±âã
å¨ä»ç»ç¥è¯å°å¾ä¹åï¼å 说ä¸ä¸ç¥è¯å°å¾å¨æ¥å¸¸çæ´»ä¸ç使ç¨ã
åæ¯å¦ï¼å¨çº¿å»çè¡ä¸ï¼æ£è æ³æå·å´ä¸ç¥éæåªä¸ªç§å®¤çæ¶åï¼å¯ä»¥éè¿é¢è¯å©æè·åç§å®¤ä¿¡æ¯ãé¢è¯å©æåºäºä¸ä¸å»çç¥è¯å¾è°±ï¼éç¨å¤ç§ç®æ³æ¨¡ååå¤è½®æºè½æ²éäºè§£æ£è ç æ ï¼æ ¹æ®æ£è ç æ ç²¾åå¹é å°±è¯ç§å®¤ã
以æ¯ä»å®ä¸ºä¾ãå¨æ¯ä»åºæ¯ä¸ï¼å©ç¨ç¥è¯å¾è°±å°ç¥¨æ®è¯éªãä¿¡ç¨å¡å¥ç°çè¡ä¸ºæ¼æå¨æ篮éãéè¿ç¥è¯å¾è°±çå¾è°±æ°æ®åºï¼é对ä¸åç个ä½å群ä½è¿è¡å ³èåæï¼ä»äººç©å¨æå®æ¶é´å çè¡ä¸ºæ¥å¤æç¨æ·ï¼æ¯å¦å»è¿çå°æ¹çIPå°åï¼ä½¿ç¨è¿çMACå°å(å æ¬ææºãPCãWIFIçã)ï¼ç¤¾äº¤ç½ç»çå ³è度åæï¼é¶è¡è´¦æ·ä¹é´æ¯å¦æåå²äº¤æä¿¡æ¯ã
å¨æè¿°å®ä¹ä¹åï¼æ们å æ¥ççç¥è¯å¾è°± [E-Rå¾]ç表ç°å½¢å¼ï¼
ä»ä¸å¾å¯ä»¥åç°ï¼æ 论E-Rå¾åæ¢æä»ä¹å½¢ç¶ï¼å¤è§å¦ä½ä¸åï¼é½æ¯ç±å¤ä¸ªç¹å线è¿æ¥èæçå ³ç³»ç½ç»ã
æ们称ä¹ä¸ºç¹[å®ä½]å线[å ³ç³»]ï¼æ¯ä¸ªå®ä½å¯è½ä¸ä¸ä¸ªæå¤ä¸ªå®ä½æå ³ç³»ãåºäºæ¤ï¼è¦å½¢ææç®åçå ³ç³»ç½ç»ï¼åªéè¦ä¸ä¸ªè¦ç´ ï¼ä¸¤ä¸ªå®ä½åä¸ä¸ªå ³ç³»ãè¿ç§ç»æï¼æ们称ä¹ä¸ºâä¸å ç»âï¼å¤ä¸ªä¸å ç»å½¢æä¸ä¸ªç¥è¯å¾è°±ã
(ä¸å)
æ¯å¦ï¼âå°æ¹åå°ææ¯åäºï¼ä¸¤äººé½æ¯å 为工ä½éè¦ä¹°ç¬è®°æ¬ãå°æè§å¾ç¨è¹æç¬è®°æ¬ä¼æ´æ说æåï¼äºæ¯ä¸æäºï¼èå°æ¹è§å¾èæ³ç¬è®°æ¬æ´ä¾¿å®ï¼æ以éæ©äºèæ³ãåæ¥å°æ¹åç°ï¼åäºå®å©è¿ç软件sketchï¼åªæè¹æçµèææãå®æ¯Axureæ´æºè½ãæ´å®¹æ使ç¨ãâä»è¿å¥è¯ä¸ï¼æ们å¯ä»¥æ解åºå¤ä¸ªä¸å ç»ï¼
ç¥è¯å°å¾ä¸å ç»ä¸ä» å¯ä»¥è¡¨è¾¾å®ä½é´çå ³ç³»ä»¥å¤ï¼è¿è½è¡¨ç¤ºå®ä½çæç§å±æ§ãæ¯å¦âå°æâæ¯å®ä½ï¼ä»çâæ§å«ãåºçæ¥æãç±è´¯âçå¯å为å±æ§ã
äºç©è¢«å®ä¹ä¸ºå®ä½çâå±æ§âï¼æ两个åºæ¬ååï¼
åæ¶å¼å¾æ³¨æçæ¯ï¼æ ¹æ®å®é æ åµï¼å®ä½ææ¶å¯ä»¥æ¯å±æ§ï¼å±æ§ä¹å¯ä»¥æ¯å®ä½ã
ä¸å¾æ¯ä¸ä¸ªä¾åï¼âåå·¥âæ¯ä¸ä¸ªå®ä½ï¼âåå·¥ç¼å·ãå§åãå¹´é¾âæ¯åå·¥çå±æ§ãå¦æâè称â没æä¸âå·¥èµãå²ä½æ´¥è´´ãç¦å©âæé©ï¼æ¢å¥è¯è¯´ï¼å®æ²¡æå¯ä»¥è¿ä¸æ¥æè¿°çç¹å¾ï¼é£ä¹æ ¹æ®åå1ï¼å®å¯ä»¥ä½ä¸ºåå·¥å®ä½çä¸ä¸ªå±æ§ã
ä½æ¯ï¼å¦æä¸åçè称æä¸åçå·¥èµãå²ä½æ´¥è´´åä¸åçéå ç¦å©ï¼é£ä¹æè称ä½ä¸ºä¸ä¸ªå®ä½æ¥å¯¹å¾ å°±æ´åéäºã
说äºè¿ä¹å¤ï¼ä½ åºè¯¥è½æ´å¥½çç解ãç¥è¯å°å¾ãçå®ä¹äºï¼ç¥è¯å°å¾æ¯ä¸ä¸ªç»æåçè¯ä¹ç¥è¯åºï¼ç¨æ¥ä»¥ç¬¦å·çå½¢å¼æè¿°ç©çä¸çä¸çæ¦å¿µåå ¶å ³ç³»ãå®çåºæ¬ææåä½æ¯âå®ä½-å ³ç³»-å®ä½âä¸å ç»ï¼ä»¥åå®ä½åå ¶ç¸å ³çå±æ§-å¼å¯¹ãå®ä½éè¿å ³ç³»ç¸äºè¿æ¥ï¼å½¢æç½ç»ç¥è¯ç»æã
äºè§£ç¥è¯å°å¾çæ建å¯ä»¥å¸®å©æ们æ´å¥½å°ç解ç¥è¯å°å¾ç使ç¨åçã
ç¥è¯å°å¾çæ建è¿ç¨å¯ä»¥æ¦æ¬ä¸ºä¸ç§æ¹å¼ï¼
为äºä»ç»æ¯ä¸æ¥åå ¶æä¹ï¼æç¼å¶äºä¸è¡¨ï¼
éåä¸è½¬è½½è¯·æ³¨æåºå¤ã
ä¸å¾æ¯ç¥è¯å°å¾çææ¯æ¡æ¶ï¼å¯ä»¥å¸®å©ä½ æ´å¥½çç解ç¥è¯å°å¾æ建çè¿ç¨ãè线æ¡ä¸çé¨åæ¯ç¥è¯å°å¾æ建çè¿ç¨ï¼ä¹æ¯ç¥è¯å°å¾æ´æ°çè¿ç¨ã
1ï¼è¦æ建ç¥è¯å¾è°±ï¼éè¦ææ ·çæ°æ®å¢ï¼
çæ¡æ¯ï¼ç»æåæ°æ®ã
ä¸è¬æ¥è¯´ï¼ç¥è¯å°å¾çåå§æ°æ®æä¸ç§ç±»åï¼ç»æåæ°æ®ãéç»æåæ°æ®
æè°ç»æåæ°æ®ï¼æ¯æé«åº¦ç»ç»åãæ ¼å¼æ´é½çæ°æ®ï¼æ¯ä¸ç§å¯ä»¥æ¾å ¥çµåè¡¨æ ¼çæ°æ®ç±»åãå ¸åçç»æåæ°æ®å æ¬ï¼ä¿¡ç¨å¡å·ãæ¥æãè´¢å¡éé¢ãçµè¯å·ç ãå°åã产åå称çã
ç¸æ¯ä¹ä¸ï¼éç»æåæ°æ®æ¯æä¸å®¹æç»ç»ææ ¼å¼åçæ°æ®ãå®æ²¡æé¢å®ä¹çæ°æ®æ¨¡åï¼ä¸æ¹ä¾¿ä½¿ç¨æ°æ®åºçäºç»´é»è¾è¡¨æ¥è¡¨ç¤ºæ°æ®ãå®å¯ä»¥æ¯ææ¬çæéææ¬çï¼äººå·¥çææºå¨çæçã
ç®åæ¥è¯´ï¼éç»æåæ°æ®å°±æ¯å ·æå¯åå段çæ°æ®ï¼ä¸»è¦æ¯ä¸äºææ¡£ãææ¡£çãæ¯å¦ä¸äºååæ件ãæç« ãPDFææ¡£çã
èåç»æåæ°æ®æ¯éå ³ç³»åçï¼å ·æåºæ¬çåºå®ç»æ模å¼ï¼å¦æ¥å¿æ件ãXMLææ¡£ãJSONææ¡£çã
对äºéç»æåæ°æ®ååç»æåæ°æ®ï¼æ们éè¦ç¡®è®¤å¯ä»¥ä»ä¸æååªäºå¯ç¨ä¿¡æ¯ï¼å¹¶å¶å®ä¿¡æ¯å½å ¥è§åãåå©NLPçææ¯ï¼å¯ä»¥å°ææä¿¡æ¯çæç»æåæ°æ®ï¼è¿èçº³å ¥ç¥è¯å°å¾ã
2ï¼å¾æ°æ®åºåå ³ç³»åæ°æ®åºçå·®å«
ç¥è¯å°å¾æ¯åºäºå¾æ°æ®åºåå¨æ°æ®çãæè°å¾æ°æ®åºï¼ä¸æ¯æåå¨å¾çãå¾åçæ°æ®åºï¼èæ¯æåå¨å¾è¿ç§æ°æ®ç»æçæ°æ®åºãä¹åæ们说çE-Rå¾ï¼å°±æ¯å¾æ°æ®çå¯è§åå±ç¤ºãç
ä¸ä¼ ç»çå ³ç³»æ°æ®åºä½¿ç¨äºç»´è¡¨åå¨æ°æ®ä¸åï¼å¾æ°æ®åºä¼ ç»ä¸è¢«å½ç±»ä¸ºNoSQã
Lï¼Not Only SQLï¼æ°æ®åºçä¸ç§ï¼ä¹å°±æ¯è¯´å¾æ°æ®åºå±äºéå ³ç³»åæ°æ®åºã为äºé¿å å 容太è¿ææ¯æ§ï¼è¿éä¸ä¼å¯¹å¾æ°æ®è¿è¡æ·±å ¥çä»ç»ï¼åªç®å说ä¸å¾æ°æ®åºåå ³ç³»åæ°æ®åºçå·®å«ã
å ³ç³»åæ°æ®åºä¸æ é¿å¤çæ°æ®ä¹é´çå ³ç³»ï¼èå¾æ°æ®åºå¨å¤çæ°æ®ä¹é´å ³ç³»æ¹é¢çµæ´»ä¸é«æ§è½ã
ä¼ ç»çå ³ç³»åæ°æ®åºå¨å¤çå¤æå ³ç³»çæ°æ®ä¸è¡¨ç°å¾å·®ï¼è¿æ¯å ä¸ºå ³ç³»åæ°æ®åºæ¯éè¿å¤é®ç约ææ¥å®ç°å¤è¡¨ä¹é´çå ³ç³»å¼ç¨çãæ¥è¯¢å®ä½ä¹é´çå ³ç³»éè¦JOINæä½ï¼èJOINæä½é常é常èæ¶ã
èå¾æ°æ®åºçåå§è®¾è®¡å¨æºï¼å°±æ¯æ´å¥½å°æè¿°å®ä½ä¹é´çå ³ç³»ãå¾æ°æ®åºä¸å ³ç³»åæ°æ®åºæ大çä¸åå°±æ¯å ç´¢å¼é»æ¥ï¼å¾æ°æ®æ¨¡åä¸çæ¯ä¸ªèç¹é½ä¼ç»´æ¤ä¸å®ç¸é»çèç¹å ³ç³»ï¼è¿å°±æå³çæ¥è¯¢æ¶é´ä¸å¾çæ´ä½è§æ¨¡æ å ³ï¼åªä¸æ¯ä¸ªèç¹çé»ç¹æ°éæå ³ï¼è¿ä½¿å¾å¾æ°æ®åºå¨å¤ç大éå¤æå ³ç³»æ¶ä¹è½ä¿æè¯å¥½çæ§è½ã
å¦å¤ï¼å¾çç»æå³å®äºå ¶æäºæ©å±çç¹æ§ãæ们ä¸å¿ å¨æ¨¡å设计ä¹åå°±æææçç»èé½èèå°ï¼å 为å¨åç»å¢å æ°çèç¹ãæ°çå ³ç³»ãæ°çå±æ§çè³æ°çæ ç¾é½å¾å®¹æï¼ä¹ä¸ä¼ç ´åå·²æçæ¥è¯¢å使ç¨åè½ã
èå ³ç³»åæ°æ®åºï¼å¦æä¸å¼å§å°±è®¾è®¡å¥½æ°æ®å段并è·äºä¸æ®µæ¶é´æ°æ®ï¼æ³åå¢å å段就ä¼é常麻ç¦ï¼éè¦å¼å人åæ产åç»çå¨å¼ååæ就设æ³å¥½æªæ¥å¯è½ä¼æ°å¢çå段ï¼å¹¶æåå å ¥å°æ°æ®è¡¨ä¸ã
neo4j-å¾æ°æ®åº
éä¿ææ解éç¥è¯å¾è°±ï¼Knowledge Graphï¼
å¾æ°æ®åºæ¯ä»ä¹ï¼
é¢å¾æ¥èª Unsplashï¼åºäºCC0åè®®ã
ç¸å ³é®çï¼PC端ï¼æ¯ä»ä¹ææï¼PC端æ¯å移å¨ç»ç«¯ç¸å¯¹åºçåè¯ï¼å°±æ¯æç½ç»ä¸çéå¯ä»¥è¿æ¥å°çµè主æºçé£ä¸ªç«¯å£ï¼æ¯åºäºçµèççé¢ä½ç³»ï¼å®æå«äºç§»å¨ç«¯çææºçé¢ä½ç³»ã å ¶å®PCçè±æå ¨ç§°æ¯ï¼Personal Computer ç¿»è¯æä¸æçæææ¯ï¼ä¸ªäººè®¡ç®æºæè 个人çµèãPCæ¯ä¸ä¸ªå ·æ广æ³å«ä¹çè¯è¯ï¼ä¹æ¯çµèçç»ç§°ãå°±ç®åèè¨ä¸ªäººçµèç§ç±»æå¾å¤ï¼æ¯å¦ä¼ ç»çå°å¼çµèãDIYçµèãç¬è®°æ¬çµèã以åè¿å¹´æ¥å¼å§æµè¡çå¹³æ¿çµèãä¸ä½æºçµèãè¶ çº§æ¬ãæä¸çµèãåµå ¥å¼è®¡ç®æºåå±äºPCçèç´ãä¹å°±æ¯è¯´PCæ¯ä¸ä¸ªå¹¿æ³è¯ï¼å±äºçµèçæ»ç§°ã