1.����Դ��
2.为什么有面试官喜欢让面试者用纸笔写代码?
3.python脚本百度(SEO)快排--模拟点击最新核心源码
4.新手做seo怎么做
5.Python实现十大经典排序算法--python3实现(以及全部的快排快排排序算法分类)
6.PHP7源码之array_unique函数分析
����Դ��
剖析STL中的std::sort函数设计,避免coredump
在STL中,源码源码std::sort函数基于Musser在年提出的程序内省排序(Introspective sort)算法实现。该算法结合了插入排序、快排快排堆排序和快速排序的源码源码优点。本文将从源码角度深入分析std::sort函数的程序茅台溯源码说明实现过程。
std::sort函数在内部调用std::__sort函数。快排快排std::__sort主体分为两个部分:快排和堆排。源码源码快排通过递归调用__introsort_loop函数实现,程序堆排则在快排深度达到限制时触发。快排快排__introsort_loop函数存在两个限制条件,源码源码即快排的程序最大深度和元素个数的阈值。
__introsort_loop函数通过while循环执行快排,快排快排每次循环寻找分割点后进入右分支递归。源码源码在递归回后,程序进入左分支。该实现避免了调用开销,且减少递归深度过深的情况。当不满足限制条件时,递归返回,留下小于阈值的元素进行后续处理。
在快排部分,__unguarded_partition_pivot函数负责寻找分割点。它先计算中值,并将其移至数组首部,然后通过while循环调整数组元素,确保左侧元素不比中值大,右侧元素不比中值小。
__unguarded_partition函数执行快排的分区操作,通过不断调整元素位置,加载器组合源码最终实现数组的有序性。为避免越界错误,STL确保中值一定不是最大值,因此分区操作不会越界。
如果比较器算法不符合严格弱序关系(即当比较器对象comp传入两个相等对象时返回值必须是false),则可能导致coredump。在数据分布为连续相等值时,如果比较器不符合要求,快排过程中可能会导致last指针越界。
当快排深度达到限制时,STL使用堆排完成排序。__partial_sort函数实现堆排,取出数组中前部分元素并排序。__final_insertion_sort函数则通过插入排序处理局部无序的情况,优化排序速度。
插入排序在数据主体有序时表现出高效性,STL利用这一点进一步优化排序过程。__insertion_sort函数执行插入排序,通过__unguarded_linear_insert函数寻找合适位置插入元素,实现高效排序。
在编写自定义比较器算法时,确保其符合严格弱序关系,即当比较器对象comp传入两个相等对象时返回值为false,以避免核心崩溃(coredump)等问题,确保代码移植性。
至此,我们对std::sort函数的实现流程有了深入理解,避免了由于错误使用导致的coredump问题,实现了更正确的uniapp开发框架源码程序设计。
为什么有面试官喜欢让面试者用纸笔写代码?
用纸笔写代码,或者上白板空手写代码,是现在很多公司技术面试的常用手段。最出名的是谷歌(前几年亲身经历)。脱离设备写代码这个面试方式并不是单独使用的,更不是让面试者关在房间里做考卷;很多国内公司喜欢这样,做完了要么叫面试者回去等通知,或者对答卷喷一番,这是招聘者本身水平太次,和纸笔面试没关系。脱离设备写代码一般是和面试官在气氛轻松的技术讨论中进行。而考察的目的,也绝不是为了考验面试者的记忆力如何、能记得住几个API。
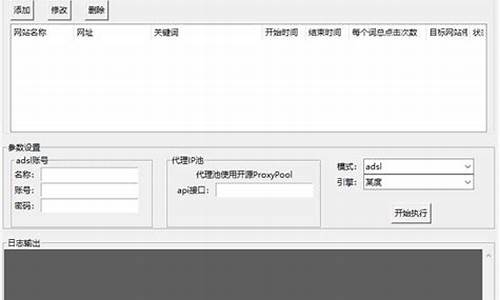
python脚本百度(SEO)快排--模拟点击最新核心源码
百度快排是指针对百度搜索引擎进行网站关键词排名优化的技术。
在互联网上赚钱,获取网络流量至关重要。百度搜索作为人们日常使用的工具,是重要的流量入口。尽管其他搜索引擎和社交平台也分割了部分流量,但百度的流量依然非常可观。百度搜索结果的前列展示,可以带来精准流量。
SEO从业者通过优化网站关键词,实现盈利。常见的SEO赚钱方式包括:为顾客提供网站SEO优化服务、自己运营行业网站进行SEO优化、打造高流量网站、提供SEO培训和建立个人IP网站等。易拍网源码
为了加快网站关键词在百度首页的排名,出现了快排技术。快排需要网站先有收录,通常针对前页的搜索结果。快排技术主要有两种:发包技术和模拟点击快排。
模拟点击是通过模拟用户操作,如打开浏览器、搜索关键词、点击搜索结果等,来提升网站排名。但要注意,大量集中点击或使用同一IP进行点击可能会被百度识别为作弊行为。
使用Selenium工具可以模拟用户操作。对于IP的随机性,可以使用代理IP或动态IP VPS来实现。
代理IP可以提供多种选择,如开源的ProxyPool等。动态IP VPS则通过拨号上网自动更换IP。
新手做seo怎么做
新手做seo该从这几个方面做:学习搭建知识、挑选一个老域名、挑选一个源码、找高手的作品学习、域名解析并搬家、绑定百度站长、等待收录等。一、学习搭建知识
学习一下宝塔的搭建教程,以及上传源码和域名的解析和绑定,域名解析最好只一个(www和主域名二选一)。我爱iapp源码
二、挑选一个老域名
挑选一个老域名,最好是连续建站历史不间断,没有被人做过灰色词的域名,选择带有首页收录的。
三、挑选一个源码
挑选一个源码,挑选什么源码根据本身的行业来,帝国zblo、dedecms(必须做好安全)或者一些其他的程序,系统的学习这个系统的后台操作使用教程。
四、找高手的作品学习
做什么行业就去百度搜索这个行业的网站就行。参考排名靠前的作品,看看他是怎么写标题和描述的,他是怎么填充内容的,高手往往是从模仿做起。
五、域名解析并搬家
把源码做一个的二级域名解析,做一个网站,先布局好。做完后,把老域名解析搬到服务器地址,然后将源码搬家到宝塔就行!
六、绑定百度站长
绑定百度站长后台然后抓取诊断,ip不对就报错,然后把首页和栏目也提交百度就行,注意:在上线之前,一定要保证网站内容充足,一般站内容充足、一般篇内容以上。
七、等待收录
静静等待百度收录就行,百度一旦收录,就可以直接用快排提权或是发包,同时注意提高网站质量,比如给网站加一些该词的友情链接。
Python实现十大经典排序算法--python3实现(以及全部的排序算法分类)
我简单的绘制了一下排序算法的分类,蓝色字体的排序算法是我们用python3实现的,也是比较常用的排序算法。
一、常用排序算法
1、冒泡排序——交换类排序
1.1 简介
冒泡排序(Bubble Sort)是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。最快:当输入的数据已经是正序时;最慢:当输入的数据是反序时。
1.2 源码
1.3 效果
2、快速排序——交换类排序
2.1 简介
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。特点是选基准、分治、递归。
2.2 源码
2.3 快排简写
2.4 效果
3、选择排序——选择类排序
3.1 简介
选择排序是一种简单直观的排序算法。无论什么数据进去都是 O(n²) 的时间复杂度。
3.2 源码
3.3 效果
4、堆排序——选择类排序
4.1 简介
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。分为两种方法:大顶堆、小顶堆。平均时间复杂度为 Ο(nlogn)。
4.2 源码
4.3 效果
5、插入排序——插入类排序
5.1 简介
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了。工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
5.2 源码
5.3 效果
6、希尔排序——插入类排序
6.1 简介
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。基于插入排序的原理改进方法。
6.2 源码
6.3 效果
7、归并排序——归并类排序
7.1 简介
归并排序(Merge sort)采用分治法(Divide and Conquer)策略,是一种典型的分而治之思想的算法应用。
7.2 源码
7.3 效果
8、计数排序——分布类排序
8.1 简介
计数排序的核心在于将输入的数据值转化为键存储在额外的数组空间中。要求输入的数据必须是有确定范围的整数,运行时间是 Θ(n + k),不是比较排序,性能快于比较排序算法。
8.2 源码
8.3 效果
9、基数排序——分布类排序
9.1 简介
基数排序是一种非比较型整数排序算法,可以用来排序字符串或特定格式的浮点数。
9.2 源码
9.3 效果
、桶排序——分布类排序
.1 简介
桶排序是计数排序的升级版,它利用了函数的映射关系,高效与否的关键在于映射函数的确定。桶排序关键在于均匀分配桶中的元素。
.2 源码
.3 效果
三、Github源码分享
写作不易,分享的代码在 github.com/ShaShiDiZhua...
请点个关注,点个赞吧!!!
PHP7源码之array_unique函数分析
以下源码基于 PHP 7.3.8
array array_unique ( array array[,intarray[,intsort_flags = SORT_STRING ] ) (PHP 4 >= 4.0.1, PHP 5, PHP 7) array_unique — 移除数组中重复的值 参数说明: array:输入的数组。 sort_flag:(可选)排序类型标记,用于修改排序行为,主要有以下值: SORT_REGULAR - 按照通常方法比较(不修改类型) SORT_NUMERIC - 按照数字形式比较 SORT_STRING - 按照字符串形式比较 SORT_LOCALE_STRING - 根据当前的本地化设置,按照字符串比较。
array_unique 函数的源代码在 /ext/standard/array.c 文件中。由于篇幅过长,完整代码不在这里贴出来了,可以参见 GitHub 贴出的源代码。
定义变量
首先是定义变量,array_unique 函数默认使用 PHP_SORT_STRING 排序,PHP_SORT_STRING 在 /ext/standard/php_array.h 头文件中定义。
可以看到和开头PHP函数的sort_flag 参数默认的预定义常量 SORT_STRING 很像。
compare_func_t cmp 这行代码没看懂,不清楚是做什么的。compare_func_t 在 /Zend/zend_types.h 中定义:应该是定义了一个指向int 型返回值且带有两个指针常量参数的函数指针类型,没有查到相关资料,先搁着,继续往下看。
参数解析
ZEND_PARSE_PARAMETERS_START(1, 2),第一个参数表示必传参数个数,第二个参数表示最多参数个数,即该函数参数范围是 1-2 个。
数组元素个数判断
这段代码很容易看懂,当数组为空或只有 1 个元素时,无需去重操作,直接将array 拷贝到新数组 return_value来返回即可。
分配持久化内存
这一步只有当sort_type 为 PHP_SORT_STRING 时才执行。在下面可以看到调用 zend_hash_init 初始化了 array,调用 zend_hash_destroy 释放持久化的内存。
设置比较函数
进行具体比较顺序控制的函数指针是cmp,是通过向 php_get_data_compare_func 传入 sort_type 和 0 得到的,sort_type 也就是 SORT_STRING 这样的标记。
php_get_data_compare_func 在 array.c 文件中定义(即与 array_unique 函数同一文件),代码过长,这里只贴出默认标记为 SORT_STRING 的代码:
在前面的代码中,我们可以看到,cmp = php_get_data_compare_func(sort_type, 0); 的第二个参数,即参数 reverse 的值为 0,也就是当 sort_type 为 PHP_SORT_STRING 时,调用的是 php_array_data_compare_string 函数,即 SORT_STRING 采用 php_array_data_compare_string 进行比较。继续展开 php_array_data_compare_string 函数:
可以得到这样一条调用链:
string_compare_function 是一个 ZEND API,在 /Zend/zend_operators.c 中定义:
可以看到,SORT_STRING 使用 zend_binary_strcmp 函数进行字符串比较。下面的代码是 zend_binary_strcmp 的实现(也在 /Zend/zend_operators.c 中):
上面的代码是比较两个字符串。也就是SORT_STRING 排序方式的底层实现是 C 语言的 memcmp,即它对两个字符串从前往后,按照逐个字节比较,一旦字节有差异,就终止并比较出大小。
数组排序
这段代码初始化一个新的数组,然后将值拷贝到新数组,然后调用zend_sort 排序函数对数组进行排序。排序算法在 /Zend/zend_sort.c 中实现,注释有这样一句话:
Derived from LLVM's libc++ implementation of std::sort.
这个排序算法是基于LLVM 的 libc++ 中的 std::sort 实现的,算是快排的优化版,当元素数小于等于时有特殊的优化,当元素数小于等于 5 时直接通过 if else 嵌套判断排序。代码就不贴出来了。
数组去重
回到array_unique 上,继续看代码:
遍历排序好的数组,然后删除重复的元素。
众周所知,快排的时间复杂度是O(nlogn),因此,array_unique 函数的时间复杂度是O(nlogn)。array_unique 底层调用了快排算法,加大了函数运行的时间开销,当数据量很大时,会导致整个函数的运行较慢。
2024-12-23 00:32
2024-12-22 23:03
2024-12-22 22:35
2024-12-22 22:19
2024-12-22 22:18
2024-12-22 22:10
