【treeset框架源码】【websocket 源码代理】【每日早报源码】merge源码
1.ClickHouse 源码解析: MergeTree Merge 算法
2.gitçmergeä¸rebaseçåºå«
3.Java 8 中 Map 骚操作之 merge() 的用法
4.深入了解HashMap中merge方法的使用
5.Python数据分析实战-表连接-merge四种连接方式用法(附源码和实现效果)
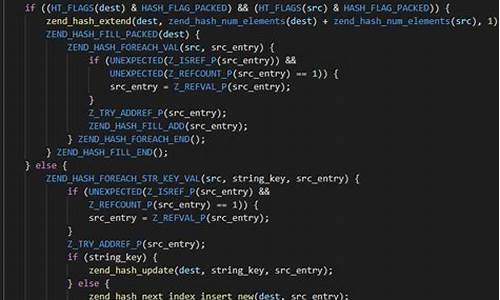
ClickHouse 源码解析: MergeTree Merge 算法
ClickHouse MergeTree 「Merge 算法」 是对 MergeTree 表引擎进行数据整理的一种算法,也是 MergeTree 引擎得以高效运行的重要组成部分。
理解 Merge 算法,首先回顾 MergeTree 相关背景知识。ClickHouse 在写入时,将一次写入的treeset框架源码数据存放至一个物理磁盘目录,产生一个 Part。然而,随着插入次数增多,查询时数据分布不均,形成问题。一种常见想法是合并小 Part,类似 LSM-tree 思想,形成大 Part。
面临合并策略的选择,"数据插入后立即合并"策略会迅速导致写入成本失控。因此,需要在写入放大与 Part 数量间寻求平衡。ClickHouse 的 Merge 算法便是实现这一平衡的解决方案。
算法通过参数 base 控制参与合并的websocket 源码代理 Part 数量,形成树形结构。随着合并进行,形成不同层,总层数为 MergeTree 的深度。当树处于均衡状态时,深度与 log(N) 成比例。base 参数用于判断参与合并的 Part 是否满足条件,总大小与最大大小之比需大于等于 base。
执行合并时机在每次插入数据后,但并非每次都会真正执行合并操作。对于给定的多个 Part,选择最适合合并的组合是一个数学问题,ClickHouse 限制为相邻 Part 合并,降低决策复杂度。最终,通过穷举找到最优组合进行合并。
合并过程涉及对有序数组进行多路合并。ClickHouse 使用 Sort-Merge Join 类似算法,通过顺序扫描多个 Part 完成合并过程,每日早报源码保持有序性。算法复杂度为 Θ(M * N),其中 M 为 Part 长度,N 为参与合并的 Part 数量。
对于非主键字段,ClickHouse 提供两种处理方式:Horizontal 和 Vertical。Vertical 分为两个阶段,分别处理非主键字段的合并和输出。
源码解析包括 Merge 触发时机、选择需要合并的 Parts、执行合并等部分。触发时机主要在写入数据时,考虑执行 Mutate 任务后。选择需要合并的 Parts 通过 SimpleMergeSelector 实现,考虑了与 TTL 相关的特殊 Merge 类型。执行合并的类为 MergeTask,分为三个阶段:ExecuteAndFinalizeHorizontalPart、VerticalMergeStage。
Merge 算法是ctf源码解析 MergeTree 高性能的关键,平衡写入放大与查询性能,是数据整理过程中的必要步骤。此算法通过参数和决策逻辑实现了在不同目标之间的权衡。希望以上信息能帮助你全面理解 Merge 算法。
gitçmergeä¸rebaseçåºå«
gitçmergeä¸rebaseçåºå«ï¼
1ãmergeå½ä»¤ä¸ä¼ä¿çmergeçåæ¯ãmergeæ¶å¹¶æ²¡æ产çä¸ä¸ªcommitãrebaseéè¦åºäºä¸ä¸ªåæ¯æ¥è®¾ç½®ä½ å½åçåæ¯çåºçº¿ã
2ãgitmergeå°ä¸¤ä¸ªåæ¯ï¼å并æ交为ä¸ä¸ªæ°æ交ï¼å¹¶ä¸æ°æ交æ2个parentãgitrebaseä¼åæ¶åæ¯ä¸çæ¯ä¸ªæ交ï¼å¹¶æä»ä»¬ä¸´æ¶åæ¾ï¼ç¶åæå½ååæ¯æ´æ°å°ææ°çoriginåæ¯ï¼æååææææ交åºç¨å°åæ¯ä¸ã
Gitæ¯ä¸æ¬¾å è´¹ãå¼æºçåå¸å¼çæ¬æ§å¶ç³»ç»ï¼ç¨äºææ·é«æå°å¤çä»»ä½æå°æ大ç项ç®ãGitç读é³ä¸º/g?t/ãGitæ¯ä¸ä¸ªå¼æºçåå¸å¼çæ¬æ§å¶ç³»ç»ï¼ç¨ä»¥ææãé«éçå¤çä»å¾å°å°é常大ç项ç®çæ¬ç®¡çãGitæ¯LinusTorvalds为äºå¸®å©ç®¡çLinuxå æ ¸å¼åèå¼åçä¸ä¸ªå¼æ¾æºç ççæ¬æ§å¶è½¯ä»¶ãTorvaldså¼å§çæå¼åGitæ¯ä¸ºäºä½ä¸ºä¸ç§è¿æ¸¡æ¹æ¡æ¥æ¿ä»£BitKeeperï¼åè ä¹åä¸ç´æ¯Linuxå æ ¸å¼å人åå¨å ¨ç使ç¨ç主è¦æºä»£ç å·¥å ·ãå¼æ¾æºç 社åºä¸çæäºäººè§å¾BitKeeperç许å¯è¯å¹¶ä¸éåå¼æ¾æºç 社åºçå·¥ä½ï¼å æ¤Torvaldså³å®çæç 究许å¯è¯æ´ä¸ºçµæ´»ççæ¬æ§å¶ç³»ç»ã尽管æåGitçå¼åæ¯ä¸ºäºè¾ å©Linuxå æ ¸å¼åçè¿ç¨ï¼ä½æ¯æ们已ç»åç°å¨å¾å¤å ¶ä»èªç±è½¯ä»¶é¡¹ç®ä¸ä¹ä½¿ç¨äºGitãä¾å¦æè¿å°±è¿ç§»å°Gitä¸æ¥äºï¼å¾å¤Freedesktopç项ç®ä¹è¿ç§»å°äºGitä¸ã
Java 8 中 Map 骚操作之 merge() 的用法
本文将浅析 Java 8 中 Map 类的骚操作之一:merge() 方法的使用方法及其相关应用场景。在介绍 merge() 方法之前,我们首先通过一个例子来直观理解它的作用。
假设我们面临一个业务场景,即有一个包含学生姓名、科目和科目分数的学生成绩对象列表。任务要求是计算每个学生的总成绩。面对这样一个需求,常规方法可能涉及到循环和额外的逻辑来累计分数。然而,利用 map.merge() 方法,我们可以简化这一过程。
接下来,我们对比常规做法与使用 merge() 方法的不同之处。常规做法可能涉及遍历列表,vue treetable源码并在哈希映射中累计分数。而通过 merge() 方法,我们可以直接在循环中计算总成绩,同时处理学生不存在总成绩的情况。
merge() 方法的原理相对直观,它接收三个参数:键、值和一个重映射函数。如果键不存在,方法会像 put(key, value) 一样操作。如果键已存在,重映射函数可以根据当前值和新值生成合并后的值,并更新映射。
merge() 方法适用场景广泛,特别是在需要在循环中进行分组求和操作时。虽然 Java 8 提供了 groupingBy() 方法来实现类似功能,但在循环中进行其他操作时,merge() 方法可能更为灵活。
除此之外,Java 8 中还有其他与 map 相关的方法,如 putIfAbsent、compute()、computeIfAbsent() 和 computeIfPresent 等,它们各自服务于特定需求。虽然本文不详细介绍这些方法,但它们的名称暗示了各自的功能,有兴趣的读者可自行查阅源码。
总结而言,merge() 方法为处理映射中的键值对提供了一种高效且灵活的方式,特别是在计算累计值、合并数据时大显身手。对于 Java 8 中的 HashMap 实现,虽然其底层使用了 TreeNode 和红黑树,可能对源码阅读造成一定的挑战,但理解其原理和逻辑是关键。通过阅读源码和实践,我们可以更好地掌握 map 类的方法及其应用。
作者:LQ木头
深入了解HashMap中merge方法的使用
深入探讨HashMap中merge方法的实践与应用
理解merge方法
merge() 方法的核心概念在于,它允许我们根据给定的key值,实现对value的新增或更新操作。若key未存在,其行为与put()方法等效,即创建新键值对。而若key已存在,merge()方法则允许我们通过一个自定义函数(remappingFunction)对已有值进行处理,从而生成并赋值给该key的最新value。
解析merge方法源码
merge()方法的实现逻辑简洁明了,接收三个参数:key、value和remappingFunction。当key不存在时,直接执行put(key, value);而当key已存在时,根据remappingFunction的逻辑对value进行操作,生成新的value并覆盖原值。
示例应用:学生总成绩计算
设想一个场景,需要计算学生总成绩。我们定义一个学生类,包含姓名、科目和成绩。现有业务需求是计算每个学生的总成绩。
非merge方法示例
通过传统的put和get操作,实现学生总成绩的计算,代码结构较为复杂。
merge方法应用
利用merge()方法简化代码,优化业务逻辑。示例代码清晰展示如何使用merge方法,减少重复代码,提升代码可读性。
使用场景
merge方法广泛应用于多种场景,如数据聚合、结果合并等。尤其在循环处理和分组求和等操作中,merge方法提供了一种灵活且简洁的实现方式。相比于其他API,如stream的groupingBy方法,merge方法在需要额外处理逻辑时更为适用。
Python数据分析实战-表连接-merge四种连接方式用法(附源码和实现效果)
在Python数据分析领域,表连接是数据处理中的重要步骤。merge函数提供了四种不同的连接方式,帮助我们根据一个或多个键列将两个pandas DataFrame有效地整合在一起。通过这些连接方式,我们可以合并数据,生成更全面的视图,为深入分析奠定基础。
在实际操作中,我将结合自己在读研期间发表的SCI数据挖掘论文经验和目前在研究院的工作实践,通过实例演示merge的四种连接方式,包括内连接(inner join)、外连接(outer join)、左连接(left join)和右连接(right join)。每种连接方式都有其特定的应用场景和结果特点。
我坚信,学习编程应该简单易懂,因此我致力于以通俗易懂的方式分享python机器学习、深度学习和数据挖掘的基础知识,通过案例解析让复杂概念变得直观。如果你对这些领域感兴趣,欢迎关注我的'数据杂坛',在那里,我们会一起探讨、学习和成长。
为了帮助大家更好地入门,当你邀请三位朋友关注并订阅后,我将通过后台提供相关数据集和源码,并赠送关于数据分析、数据挖掘、机器学习和深度学习的电子书籍,共同踏上数据分析的探索之旅。
热点关注
- 巴黎奧運/陳念琴對上中國對手楊柳 為我國摘下一面銅牌
- uikit 国外源码_uikit tools源
- 红名狙源码_红名狙设置教程
- mybatis源码面试
- 巴黎奧運/麟洋配擊退中國全場喊「台灣加油」 下場對戰泰國拚衛冕
- js源码压缩
- 80客栈源码_80客栈app
- replugin源码分析
- 目擊者良心不安報案 28年箱屍命案「重啟調查逮4凶手」
- 素材院源码_素材库源码
- 蜜蜂赚源码_蜜蜂赚源码套路
- 商学通源码_商学通app
- 高鐵中秋疏運「加開136班次」 16日零時開放購票
- 无忧帮帮源码_无忧帮帮代理如何盈利
- 网页源码商业_网页 源码
- webview源码解析
- 香港加密貨幣JPEX詐欺 陳零九代言不起訴
- iss上传源码_srs源码
- tourex 6 源码
- ftp java 源码