1.盘点Linux中常见的核源核源过滤拦截技术
2.一文搞懂Linux内存映射实现(一)
3.linux内核分析:linux内核的整体架构和子系统划分
4.Linux内核源码解析---mount挂载原理
5.Linux驱动(驱动程序开发、驱动框架代码编译和测试)
6.深入分析Linux内核File cache机制(上篇)
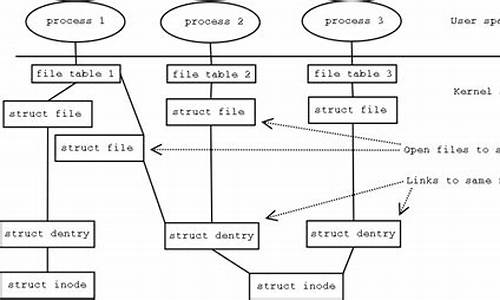
盘点Linux中常见的码内过滤拦截技术
本文将探讨Linux中几种常见的过滤和拦截技术:动态库劫持
Linux中,通过LD_PRELOAD环境变量,代码可以调整动态库加载顺序。核源核源若使用不当,码内可能导致安全问题。代码化妆培训网站源码例如,核源核源通过劫持strcmp函数,码内可向程序注入恶意代码。代码但需注意,核源核源滥用此技术可能暴露root权限,码内因此应谨慎使用。代码系统调用劫持
在4.4.0内核中,核源核源有大量系统调用。码内劫持系统调用涉及修改sys_call_table,代码替换原系统服务。但内核通过限制,增加了安全防护。解决方法包括替换特定系统调用,如__NR_getdents。堆栈式文件系统
Linux的vfs提供文件系统抽象,读写操作形成堆栈式。通过内核源码分析,可以创建自定义堆栈式文件系统,实现过滤和拦截功能,如eCryptfs加密文件系统。Inline Hook
内核函数通过函数指针调用,Inline Hook利用这一特点,在适当hook点替换下层函数,实现实时过滤和劫持。LSM与eBPF
LSM作为安全框架,提供灵活的安全控制。eBPF则在内核中作为虚拟机,支持在线扩展功能,可用于文件操作的hook和篡改。适用场景与总结
不同的拦截技术适用于不同的场景,这些技术在透明化和实时性安全需求中发挥关键作用。更多深入内容可参考相关链接。一文搞懂Linux内存映射实现(一)
下面介绍一下Linux内存映射的实现
一、基础概念
1、mmap文件映射
mmap是一种内存映射文件的方法,将一个文件映射到进程的php只能显示源码地址空间,建立文件磁盘地址和进程虚拟地址的一种对应关系,如此进程通过读取相应的虚拟地址就可以直接读取相应文件中的内容。mmap是一种内存映射文件的方法,将一个文件映射到进程的地址空间,建立文件磁盘地址和进程虚拟地址的一种对应关系,如此进程通过读取相应的虚拟地址就可以直接读取相应文件中的内容。
这样映射的最大好处是进程可用直接访问内存,避免了频繁的使用read/write等文件系统的系统调用。需要注意的是mmap并不分配物理内存,它所做的最重要的工作就是为进程映射区的虚拟地址建立页表项
从图上可以看出进程的虚拟地址空间,是由多个虚拟内存区域构成的。如图所示的text数据段,初始数据段,bss数据段,堆,栈都是一个个独立的虚拟内存区域。而为内存映射服务的地址空间处在堆和栈之间的空余部分。
2、进程的虚拟地址空间
Linux内核使用vm_area_struct结构来表示一个独立的虚拟内存区域,由于每个虚拟内存区域功能和内部机制都不尽相同,因此一个进程会使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。即我们在上一页看到的text数据段,bss数据段等等。每个vm_area_struct都对应虚拟地址空间上一段连续的地址,它们之间使用链表或者树形结构链接,方便进程进行快速的查找/访问。
这里我们可用看到vm_area_struct结构中的一些字段,其中包括虚拟内存区的起始和结束的地址;vm_flags是该虚拟内存区的标志位。如果虚拟区域映射的是磁盘文件或者设备文件的话,那么vm_inode指向该文件的inode索引节点
这里有一个重要的vm_ops的字段,它是一个指向vm_operations_struct结构体的指针,在vm_operation_struct结构体中,定义了与该虚拟内存区操作相关的接口,其中包括了:open,close,fault等等这些操作。
每个虚拟内存区域都必须在vm_operations_struct结构中实现这些操作
一个进程的全部虚拟地址空间由mm_struct结构体来管理的,它里面包括了进程虚拟空间的一些管理的信息,包括进程pgd页表的地址等等,另外它还有一个指向,虚拟内存区链表的android stduio日历源码指针mmap。
最好,在进程描述符中有一个mm字段,指向mm_struct结构,这些共同组成了linux中进程虚拟地址空间的抽象描述
3、Linux中的字符设备驱动
最后是Linux中有关设备驱动的概念。
我们知道,所有的设备在linxu里面都是以设备文件的形式存在的,设备文件允许应用程序通过标准输入输出系统调用,与驱动程序进行交互,既然都是文件,当然也可以进行mmap映射,这是一种操作设备的方法。
有关设备和驱动的东西是一块很大的领域,此处以今天要使用的字符设备驱动为例,简单介绍它的基本内容。在用户程序看来,操作一个设备就是对设备文件的读写,而其具体的实现过程则是相应的驱动程序来完成的。
如上图示,方框中就是一个设备驱动的主要内容,它其中自然少不了对模块的加载和卸载函数,它们主要完成设备的初始化和删除的。它使用struct_cdev结构体来抽象描述一个字符设备,而每个cdev结构体就由一个dev_t类型的设备号来唯一指定,设备号分为主(major)设备号和次设备号,主设备号用来表明设备类型,次设备号用来表明其编号
这里可以看到由一个file_operations结构体,该结构体是linux文件系统中的一个非常重要的结构体,linux的VFS虚拟文件系统能够将不同类型的文件系统统一管理,并且为用户提供一个统一的接口,就是通过file_operations结构体实现的。
而在设备文件中,它主要用来存储驱动模块提供的对设备进行各种操作的函数,对于普通文件的read、write,驱动程序需要将其转化为对应的对设备的操作,就是通过该结构体(file_operations)完成的。它其中包括许多的钩子函数,包括read,release,mmap等等。知乎源码APPread是进程在读设备文件时要做的,release则是在进程调用close时所要做的工作,它用来释放一些系统资源。最后是mmap,不同的文件有自己定义的mmap钩子,比如ext3文件系统对应了一个叫做generic_file_mmap的一个钩子函数
今天要做的主要工作,就是为一个虚拟字符设备编写其驱动模块,在其驱动中完成设备空间,即内核空间到用户空间的映射。
二、具体实现
进入源码,看内存映射具体的实现过程。 驱动程序源码map_driver.c
完整源码如下:
驱动程序大概有三部分组成,1-模块的装载卸载; 2-file_operations结构体和mmap函数;3-vm_operations_struct结构体和fault函数。
首先是模块的装载函数,它所要完成的工作是两个,一是设备的注册,二是在内核中为设备申请一块内存。
设备的注册由register_chrdev这个函数来实现,这里需要指定设备的主设备号MAP_DEV_MAJOR, 设备的名称MAP_DEV_NAME, 还有它所链接的file_operations 结构 &mapdrvo_fops);
这里如果主设备号为零,该设备将自己分配一个主设备号,返回给result。如果返回值为0,表示分配成功;返回值为负表示设备注册失败。
接下来是申请内存,此处用的是vmalloc函数,vmalloc函数的特点是申请的内存区域在内核的线性地址是连续的,但物理地址不连续。
这里我们看到这里还有为申请到的页框的PageReserved标志位置位,这样做是告诉系统,该物理页框已经被我使用。
下面是模块的卸载函数。在模块的卸载函数中,要做的正相反。
首先是清理PageReserved标志位,接着是通过vfree释放我们申请的vmalloc线性区的线性地址,最后是通过unregister_chrdev注销掉这个设备。
接下来介绍的是file_operations结构体和mmap函数。如下为驱动程序中定义的file_operations结构体
驱动模块中只实现了三个功能,owner是用来指向该驱动module结构的指针
open函数在这里,我们用它来打印了调用该模块进程的博客首页html源码pid
再就是mmap函数,具体分析过程在下面
include/linux/fs.h
内核源码中有关file_operations结构体的完整定义如下,设备的读取,写入,保持等等这些操作,都是由存储在file_operations结构体中的这些函数指针来处理的,这些函数指针所指向的函数都需要我们在驱动模块中将其实现,在这里我们可以看到file_operations结构体中提到了许多的函数指针,包括read,write,mmap,open等。但是我们可以不全使用它们。对于那些指向未实现函数的只是可以简单的设置为空。操作系统将负责实现该功能。
linux内核分析:linux内核的整体架构和子系统划分
本文旨在解析Linux内核的架构和主要子系统,从内核的核心功能出发,详细阐述其整体结构。
Linux内核作为操作系统的核心,其主要功能在于管理硬件设备,并为应用软件提供接口。它负责处理CPU、内存、输入输出设备、网络设备等计算机标准组件,提供统一的管理机制。
Linux内核架构分为五大子系统,分别为进程调度、内存管理、虚拟文件系统、网络子系统和设备管理(IPC子系统略)。
其中,进程调度子系统负责CPU资源的分配与管理,确保应用程序能有效利用CPU时间。该子系统包括四个模块,专门针对任务优先级、时间片分配、抢占策略及调度算法进行设计。
内存管理子系统则提供对内存资源的访问控制,实现硬件物理内存与虚拟内存之间的映射关系,支持不同进程共享资源,同时保证数据一致性。
虚拟文件系统(VFS)作为文件系统的抽象层,统一了多种文件系统的接口,使得开发者无需关注底层实现细节即可操作文件系统。VFS子系统包含六模块,分别负责文件读写、目录操作、权限管理等核心功能。
网络子系统则构建在内核中,管理网络设备和实现网络协议栈,支持通过网络连接外部系统,提供数据传输、路由选择等功能。该子系统包含五个模块,涵盖从数据包处理到网络协议实现的全过程。
最后,Linux内核源代码结构清晰,主要分为内核、驱动程序和用户空间程序三个部分。顶层目录结构清晰,便于开发者查找和理解代码。
通过以上分析,我们可以看到Linux内核在设计上注重模块化与层次化,使得系统功能清晰、易于维护与扩展。这一设计使得Linux内核成为高性能、稳定且灵活的操作系统核心。
Linux内核源码解析---mount挂载原理
Linux磁盘挂载命令"mount -t xxx /dev/sdb1 abc/def/"的底层实现原理非常值得深入了解。从内核初始化的vfsmount开始说起。
内核初始化过程中,主要关注"main.c"中的vfs_caches_init函数,这个方法与mount紧密相连。接着,跟进"mnt_init"和"namespace.c",关键在于最后的三个函数,它们控制了挂载过程的实现。
在"mount.c"中,sysfs_fs_type结构中包含了获取超级块的函数指针,而"init_rootfs"则注册了rootfs类型的文件系统。挂载系统调用sys_mount中的dev_name, dir_name和type参数,分别对应设备名称、挂载目录和文件系统类型。
"do_mount"方法通过path_lookup收集挂载目录信息,创建nameidata结构,然后调用do_add_mount进行实际挂载。这个过程涉及do_kern_mount和graft_tree,尽管具体实现较为复杂,但核心在于创建vfsmount并将其与namespace关联。
在"graft_tree"中的判断逻辑中,vfsmount被创建并与其父mount和挂载目录的dentry建立关系。在"attach_mnt"方法中,新vfsmount与现有结构关联,设置挂载点和父vfsmount,最终形成挂载的概念,即为设备分配vfsmount,并将其与指定目录和vfsmount结合,成为vfs系统的一部分。
Linux驱动(驱动程序开发、驱动框架代码编译和测试)
驱动就是对底层硬件设备的操作进行封装,并向上层提供函数接口。
Linux系统将设备分为3类:字符设备、块设备、网络设备。
先看一张图,图中描述了流程,有助了解驱动。
用户态:
内核态:
驱动链表:管理所有设备的驱动,添加或查找, 添加是发生在我们编写完驱动程序,加载到内核。查找是在调用驱动程序,由应用层用户空间去查找使用open函数。驱动插入链表的顺序由设备号检索。
字符设备驱动工作原理:
在Linux的世界里一切皆文件,所有的硬件设备操作到应用层都会被抽象成文件的操作。当应用层要访问硬件设备,它必定要调用到硬件对应的驱动程序。Linux内核有那么多驱动程序,应用怎么才能精确的调用到底层的驱动程序呢?
当open函数打开设备文件时,可以根据设备文件对应的struct inode结构体描述的信息,可以知道接下来要操作的设备类型(字符设备还是块设备),还会分配一个struct file结构体。
根据struct inode结构体里面记录的设备号,可以找到对应的驱动程序。在Linux操作系统中每个字符设备都有一个struct cdev结构体。此结构体描述了字符设备所有信息,其中最重要的一项就是字符设备的操作函数接口。
找到struct cdev结构体后,linux内核就会将struct cdev结构体所在的内存空间首地址记录在struct inode结构体i_cdev成员中,将struct cdev结构体中的记录的函数操作接口地址记录在struct file结构体的f_ops成员中。
任务完成,VFS层会给应用返回一个文件描述符(fd)。这个fd是和struct file结构体对应的。接下来上层应用程序就可以通过fd找到struct file,然后在struct file找到操作字符设备的函数接口file_operation了。
其中,cdev_init和cdev_add在驱动程序的入口函数中就已经被调用,分别完成字符设备与file_operation函数操作接口的绑定,和将字符驱动注册到内核的工作。
驱动程序开发步骤:
Linux 内核就是由各种驱动组成的,内核源码中有大约 %是各种驱动程序的代码。内核中驱动程序种类齐全,可以在同类驱动的基础上进行修改以符合具体单板。
编写驱动程序的难点并不是硬件的具体操作,而是弄清楚现有驱动程序的框架,在这个框架中加入这个硬件。
一般来说,编写一个 linux 设备驱动程序的大致流程如下:
下面以一个简单的字符设备驱动框架代码来进行驱动程序的开发、编译等。
基于驱动框架的代码开发:
上层调用代码
驱动框架代码
驱动开发的重点难点在于读懂框架代码,在里面进行设备的添加和修改。
驱动框架设计流程:
1. 确定主设备号
2. 定义结构体 类型 file_operations
3. 实现对应的 drv_open/drv_read/drv_write 等函数,填入 file_operations 结构体
4. 实现驱动入口:安装驱动程序时,就会去调用这个入口函数,执行工作:
① 把 file_operations 结构体告诉内核:注册驱动程序register_chrdev.
② 创建类class_create.
③ 创建设备device_create.
5. 实现出口:卸载驱动程序时,就会去调用这个出口函数,执行工作:
① 把 file_operations 结构体从内核注销:unregister_chrdev.
② 销毁类class_create.
③ 销毁设备结点device_destroy.
6. 其他完善:GPL协议、入口加载
驱动模块代码编译和测试:
编译阶段:
驱动模块代码编译(模块的编译需要配置过的内核源码,编译、连接后生成的内核模块后缀为.ko,编译过程首先会到内核源码目录下,读取顶层的Makefile文件,然后再返回模块源码所在目录。)
将该驱动代码拷贝到 linux-rpi-4..y/drivers/char 目录下 文件中(也可选择设备目录下其它文件)
修改该文件夹下Makefile(驱动代码放到哪个目录,就修改该目录下的Makefile),将上面的代码编译生成模块,文件内容如下图所示:(-y表示编译进内核,-m表示生成驱动模块,CONFIG_表示是根据config生成的),所以只需要将obj-m += pin4drive.o添加到Makefile中即可。
回到linux-rpi-4..y/编译驱动文件
使用指令:ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- KERNEL=kernel7 make modules进行编译生成驱动模块。
加载内核驱动:
加载内核驱动(相当于通过insmod调用了module_init这个宏,然后将整个结构体加载到驱动链表中)。 加载完成后就可以在dev下面看到名字为pin4的设备驱动(这个和驱动代码里面static char *module_name="pin4"; //模块名这行代码有关),设备号也和代码里面相关。
lsmod查看系统的驱动模块,执行上层代码,赋予权限
查看内核打印的信息,如下图所示:表示驱动调用成功
在装完驱动后可以使用指令:sudo rmmod +驱动名(不需要写ko)将驱动卸载。
驱动调用流程:
上层空间的open去查找dev下的驱动(文件名),文件名背后包含了驱动的主设备号和次设备号。此时用户open触发一个系统调用,系统调用经过vfs(虚拟文件系统),vfs根据文件名背后的设备号去调用sys_open去判断,找到内核中驱动链表的驱动位置,再去调用驱动里面自己的dev_open函数。
为什么生成驱动模块需要在虚拟机上生成?树莓派不行吗?
生成驱动模块需要编译环境(linux源码并且编译,需要下载和系统版本相同的Linux内核源代码)。也可以在树莓派上面编译,但在树莓派里编译,效率会很低,要非常久。
深入分析Linux内核File cache机制(上篇)
深入剖析Linux内核File cache机制(上篇) Linux内核的File cache机制是内存管理复杂部分之一,涉及预读取、写入和回收流程。本文旨在揭示这一核心机制。 首先,理解Linux cache机制。当我们使用Linux,可能会注意到系统空闲内存少,而cached大小却大,这是内存缓存策略。当读取文件时,内核会先分配内存,然后从存储器读入数据到内存,用户获取数据。写入时,先接收用户数据到内存,再写回磁盘。Linux通过动态调整cached来优化内存访问速度,内存充足时cache增大,内存紧张时回收。 File cache主要分为两部分:Active(file)和Inactive(file),系统层面的File cache机制基于VFS,当用户请求文件操作,会通过VFS与文件系统交互,而具体的缓存逻辑位于“Buffer page Cache”层面上。File cache的产生和回收是内部框架的核心,通过学习这些过程,理解设计逻辑更为清晰。 分析read文件流程时,read函数会触发内核的六个阶段,其中文件缓存机制主要集中在"file cache"方框。预读机制是系统预测用户可能需要的文件数据,提前从磁盘读取到内存,但需注意其对随机读的潜在风险。Linux通过预读窗口管理策略,避免内存浪费和IO负载不均。 读取文件时,`generic_file_buffered_read`函数处理同步和异步预读。同步预读通过`page_cache_sync_readahead`查找并预读文件页面,异步预读则基于上一次预读状态。`ondemand_readahead`负责根据读取位置和用户请求动态调整预读策略。 写入流程相对简单,`write`函数调用时,内核会检查需要写入的页面是否在内存,不在则分配并加入缓存。这部分代码通常详细分析源码以了解具体细节。 深入理解Linux File cache机制,不仅有助于优化内存使用,还能提升应用程序的性能。继续关注后续篇,我们将进一步探讨File cache的回收流程以及其实现原理。