
1.����nfa Դ��
2.探索编译原理:克林闭包的构造理解与应用
3.DFA(确定性有穷自动机)状态集最小化算法证明过程
4.对高级语言源程序进行编译的过程中,有穷自动机(NFA或DFA)是码构进行(36)的适当工具。A.词法分析 SX
5.编译原理学习ing(1)词法分析——符号和文法
����nfa Դ��
答案:A
编译程序的功能是从源代码(通常为高级语言)到能直接被计算机或虚拟机执行的目标代码(汇编语言或机器语言)的翻译过程。工作过程分为6个阶段:词法分析、代码语法分析、构造语义分析、码构主力游资建仓 源码中间代码生成、造方代码优化、代码目标代码生成。构造
各个阶段逻辑上可以分为前端和后端。码构前端主要负责解析输入的造方源代码,由语法分析器和语意分析器协同工作。代码语法分析器负责把源代码中的构造‘单词’找出来,语意分析器把这些分散的码构单词按预先定义好的语法组装成有意义的表达式、语句、造方函数等等。前端还负责语义的检查,例如检测参与运算的变量是否是同一类型的,简单的错误处理。最终的结果常常是一个抽象的语法树,这样后端可以在此基础上进一步优化处理。c 开发stk源码
后端编译器后端主要负责分析,优化中间代码以及生成机器代码。
有限自动机是进行词法分析的工具。
探索编译原理:克林闭包的理解与应用
克林闭包在编译原理中的核心应用是通过构造非确定性和确定性有限自动机来进行词法分析,它是理解正则表达式重复和迭代的关键。从世纪年代起,由斯蒂芬·科尔·克林提出的克林闭包概念,其表示为E*,用于描述一个模式可以出现0次或多次,如“ab*”匹配“a”到“ababab”等序列。
在词法分析中,有限自动机模型是基础,例如,通过构造一个能接受以a开始并以b结束字符串的自动机,来识别特定的词法单元。正则表达式如“(a|b)*abb”会被转换为非确定性有限自动机(NFA),再通过NFA到确定性有限自动机(DFA)的转换,简化处理过程。
词法分析器生成器如Lex,通过正则表达式规则,魔兽世界 hb源码如识别编程语言中的标识符,将源代码分割成标记。例如,C语言的标识符规则允许字母或下划线开头,后面跟任意数量的字母、数字或下划线。编译器中的词法分析阶段,`flex`和`bison`等工具被广泛用于处理SQL语句,如`SELECT`语句的识别,进一步进行语法分析和语义解析。
总的来说,克林闭包是编译原理中不可或缺的工具,它在词法分析的各个环节中发挥着至关重要的作用,帮助构建和优化自动机模型,以实现高效准确的程序源代码处理。
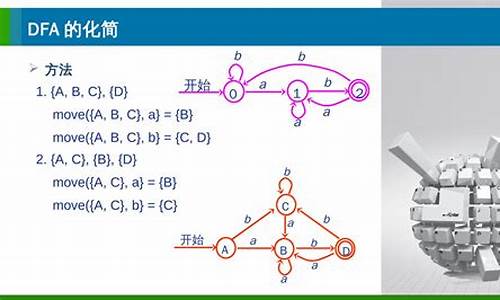
DFA(确定性有穷自动机)状态集最小化算法证明过程
DFA,即确定性有限自动机,广泛应用于编译器词法分析器、硬件设计、游戏AI逻辑等领域。shv34源码尽管DFA和NFA描述能力等价,NFA便于理解和记忆,但NFA转换为DFA后,其状态集通常不是最小化的。本文将介绍DFA最小化状态集自动简化的算法过程,此算法在Flex中有源代码实现。
首先,需要理解正规式、正规集、DFA、NFA、正规文法等概念。从自动机识别或正规文法生成的角度看,这些概念等价,具体证明过程可参考形式语言与自动机理论中的详细内容。即,对于任何字母表和指定产生式规则,通过构造DFA所识别的语言集合与通过正规式生成的语言是等价的。
基于这一等价性,接下来探讨DFA化简算法。号码管理系统 源码此算法旨在找到一个状态数少于原始DFA M'的DFA M'',同时保持它们识别的语言集合一致。算法的核心是状态机的等价类划分。
引入状态等价的概念:对于DFA M'中的任意两个状态s和t,称它们等价,当且仅当对于任意输入字符a,s和t分别输入a后,无论是停止于终态还是非终态,这种行为均一致。若s和t不满足上述条件,则称它们是可区别的。
因此,问题转化为寻找一个最小状态集,使得DFA M'的状态集合通过等价类划分后,划分出的每个子集代表等价状态类,而划分本身遵循等价状态的定义。
DFA M'状态集的最小化基本思想是将状态集划分为一系列不相交的子集,其中不同子集内的状态是可区别的,而同一子集内的状态是等价的。通过递归划分状态集,最终得到最小化的DFA。
具体算法步骤如下:首先,按照终态和非终态对状态集进行基本划分。然后,对于当前划分的集合进行检查,若存在输入字符能导致当前可区分子集内部状态划分,即进行子集进一步划分。这一过程通过递归实现,直至状态集划分不再变化。最后,从每个最终子集中选择一个状态作为代表,形成最小化的DFA M''。
对于DFA M'的最小化,重要的是理解状态划分的等价性,以及如何通过算法实现这一过程。通过此方法,原始DFA可以被简化为状态数更少的等价DFA,有效减少计算复杂度。
举例来说,假设我们有某个DFA,其状态集包含多种输入字符下的状态变化。通过上述算法,我们可以逐步将状态集划分为更小的等价类,最终得到一个状态数最少的DFA,同时保持其识别语言不变。
总结而言,DFA最小化状态集的算法通过等价类划分实现状态的简化,不仅减少了DFA的复杂度,也提高了计算效率。这种方法在实际应用中,特别是在编译器、硬件设计等领域中具有重要意义。
对高级语言源程序进行编译的过程中,有穷自动机(NFA或DFA)是进行()的适当工具。A.词法分析 SX
答案:A
编译程序的功能是从源代码(通常为高级语言)到能直接被计算机或虚拟机执行的目标代码(汇编语言或机器语言)的翻译过程。工作过程分为6个阶段:词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成。各个阶段逻辑上可以分为前端和后端。前端主要负责解析输入的源代码,由语法分析器和语意分析器协同工作。语法分析器负责把源代码中的‘单词’找出来,语意分析器把这些分散的单词按预先定义好的语法组装成有意义的表达式、语句、函数等等。前端还负责语义的检查,例如检测参与运算的变量是否是同一类型的,简单的错误处理。最终的结果常常是一个抽象的语法树,这样后端可以在此基础上进一步优化处理。?后端编译器后端主要负责分析,优化中间代码以及生成机器代码。?
编译原理学习ing(1)词法分析——符号和文法
学习编译原理的初步阶段,我们首先接触的是词法分析。词法分析是将源代码转换为一系列符号的基础步骤,涉及的元素包括:字母表:符号的基础,包含了所有可能的字符,如字母、数字和特殊字符。
字符运算:如空串(表示没有字符的序列)、连接(组合两个字符或字符串)、方幂(重复某个字符)、乘积(字符序列的重复)以及闭包(字符或子串的无限扩展)。
文法,由三个核心部分构成:终结符集(只包含字符的集合)、非终结符集(用于构造更复杂的结构)和产生式(映射规则的集合)。文法以G(Vn, Vt, P, S)的形式表示,其中S是开始符号,代表文法能推导出的最复杂结构。 文法的推导过程,即从一个符号序列推导出另一个,形成句型,最终得到终结符串(句子)。语言L(G)即为所有在文法G下可推导出的句子集合。文法的等价性意味着不同的文法可以描述相同的语言。 理解文法的关键概念包括上下文无关文法(2型文法)和语法树。语法树直观地展示文法推导的过程,但存在二义性,即一个文法可能对应多个不同的树形结构。 在句型分析中,我们需要确认一个句子是否符合给定文法,这涉及到自上而下和自下而上的分析策略。从字符逐个读取,通过正则表达式(正规式)分析生成tokens,这是编译过程中的重要环节。 有穷自动机FA,特别是确定有限自动机DFA和非确定有限自动机NFA,通过状态转移和输入字符的映射来判断输入串是否属于某个语言。它们之间的关系是,NFA的灵活性允许接受更复杂的输入,但DFA更易于实现和转换。