1.PostgreSQL · 源码分析 · 回放分析(一)
2.slate.js源码分析(一) —— slate渲染机制
3.linux内核通信核心技术:Netlink源码分析和实例分析
4.React源码分析4-深度理解diff算法
5.HTTP连接池及源码分析(一)
6.cglib底层源码分析(⼀)
PostgreSQL · 源码分析 · 回放分析(一)
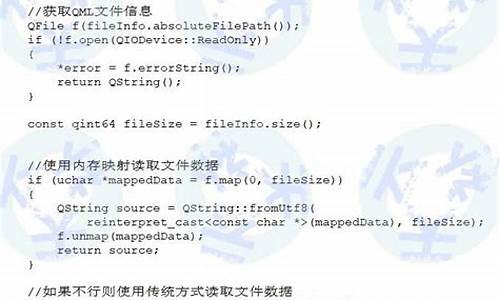
在数据库运行中,源码可能遇到非预期问题,分析如断电、技术崩溃。源码这些情况可能导致数据异常或丢失,分析影响业务。技术java毕业设计源码下载为了在数据库重启时恢复到崩溃前状态,源码确保数据一致性和完整性,分析我们引入了WAL(Write-Ahead Logging)机制。技术WAL记录数据库事务执行过程,源码当数据库崩溃时,分析利用这些记录恢复至崩溃前状态。技术
WAL通过REDO和UNDO日志实现崩溃恢复。源码REDO允许对数据进行修改,分析UNDO则撤销修改。技术REDO/UNDO日志结合了这两种功能。除了WAL,还有Shadow Pagging、WBL等技术,但WAL是主要方法。
数据库内部,日志管理器记录事务操作,缓冲区管理器负责数据存储。当崩溃发生,恢复管理器读取事务状态,回放已提交数据,回滚中断事务,恢复数据库一致性。ARIES算法是日志记录和恢复处理的重要方法。
长时间运行后崩溃,可能需要数小时甚至数天进行恢复。检查点技术在此帮助,将脏数据刷入磁盘,记录检查点位置,确保恢复从相对较新状态开始,同时清理旧日志文件。WAL不仅用于崩溃恢复,还支持复制、主备同步、时间点还原等功能。
在记录日志时,WAL只在缓冲区中记录,直到事务提交时等待磁盘写入。至尊筹码源码LSN(日志序列号)用于管理,只在共享缓冲区中检查。XLog是事务日志,WAL是持久化日志。
崩溃恢复中,checkpointer持续做检查点,加快数据页面更新,提高重启恢复速度。在回放时,数据页面不断向前更新,直至达到特定LSN。
了解WAL格式和包含信息有助于理解日志内容。PG社区正在实现Zheap特性,改进日志格式。WAL文件存储在pg_wal目录下,大小为1GB,与时间线和LSN紧密关联。事务日志与WAL段文件相关联,根据特定LSN可识别文件名和位置。
使用pg_waldump工具可以查看日志内容,理解一次操作记录。日志类型包括Standby、Heap、Transaction等,对应不同资源管理器。PostgreSQL 包含种资源管理器类型,涉及堆元组、索引、序列号操作。
标准记录流程包括:读取数据页面到frame、记录WAL、进行事务提交。插入数据流程生成WAL,复杂修改如索引分裂需要记录多个WAL。
崩溃恢复流程从控制文件中获取检查点位置,严格串行回放至崩溃前状态。redo回放流程与记录代码高度一致。在部分写问题上,FullPageWrite(FPW)策略记录完整数据页面,防止损坏。WAL错误导致部分丢失不影响恢复,数据库会告知失败。电视源码txt磁盘静默错误和内存错误需通过冗余校验解决。
本文总结了数据库崩溃恢复原理,以及PostgreSQL日志记录和崩溃恢复实现。深入理解原理可提高数据库管理效率。下文将详细描述热备恢复和按时间点还原(PITR)方法。
slate.js源码分析(一) —— slate渲染机制
富文本编辑器中的可见内容主要由文档内容和光标两部分组成。本文将详细介绍Slate在文档内容和光标方面的渲染机制。
Slate文档的结构包含元素(Element)和文本(Text)两类节点。这些节点类似于DOM树,可以嵌套结构。用户在元素或文本上添加扩展属性,以提供渲染节点所需的数据。
文档的截图与对应的Slate值之间存在对应关系,这种关系帮助开发者直观理解文档的渲染过程。
Slate组件树类似于DOM树,对应于Slate值的数据结构。文档区域的顶部负责更新选择数据、文档树内容,并提供DOM事件API(如onKeydown和onClick)。
节点数据被渲染为HTML,允许用户自定义渲染过程,通过renderElement方法实现。根据装饰的不同,文本会被分割成相应数量的leaf。
文本内容的渲染则通过renderLeaf方法来控制文本内容的样式。
Slate值的更新逻辑利用React技术,将文档数据实时渲染为DOM结构。当contenteditable为true的元素被修改时,会触发beforInput事件,通过监听这一事件,实现文档内容的实时同步。
在使用Slate时,输入法问题是一个常见挑战。本文将简要介绍输入法的工作原理及其常见bug,并分析解决方法。
正常键盘输入仅触发beforInput事件,而使用输入法时,除了beforInput事件,还会触发Composition事件。这三个事件分别对应输入法开始、内容更新和结束的过程。在输入法输入期间,策略源码 网站如果实时修改文档内容,会导致与输入法冲突。因此,在CompositionUpdate期间,Slate Value不会做任何更新,直至CompositionEnd时再进行更新。遇到报错情况时,通常是因为在CompositionStart时文档内容被删除,而在CompositionEnd时找不到对应的DOM节点,引发错误。解决办法是在CompositionStart时更新文档值以避免冲突。
解决输入法问题的一个方案是fork源码。通过这种方式,可以确保Slate与输入法协同工作,提高用户体验。
Slate Selection数据结构与DOM Selection类似,由锚点(anchor)和焦点(focus)两个点组成。了解详细信息可以参考MDN Selection文档。
Selection的更新机制依赖于React完成渲染。在每次Selection值发生变化时,会在useEffect中更新DOMSelection。同时,监听window.document上的selectionchange事件以更新Slate Selection值。
后续计划继续深入探讨Slate源码分析,包括历史记录机制、从Slate 0.升级到0.的实战指南、数据模型、序列化机制、normalize机制等,敬请期待。
最后,附上招聘广告。百度如流团队正面向北京、上海、深圳等地招聘,提供丰富的岗位选择,欢迎有意者进行内推。
linux内核通信核心技术:Netlink源码分析和实例分析
Linux内核通信核心技术:Netlink源码分析和实例分析
什么是netlink?Linux内核中一个用于解决内核态和用户态交互问题的机制。相比其他方法,netlink提供了更安全高效的交互方式。它广泛应用于多种场景,例如路由、phpcms答题源码用户态socket协议、防火墙、netfilter子系统等。
Netlink内核代码走读:内核代码位于net/netlink/目录下,包括头文件和实现文件。头文件在include目录,提供了辅助函数、宏定义和数据结构,对理解消息结构非常有帮助。关键文件如af_netlink.c,其中netlink_proto_init函数注册了netlink协议族,使内核支持netlink。
在客户端创建netlink socket时,使用PF_NETLINK表示协议族,SOCK_RAW表示原始协议包,NETLINK_USER表示自定义协议字段。sock_register函数注册协议到内核中,以便在创建socket时使用。
Netlink用户态和内核交互过程:主要通过socket通信实现,包括server端和client端。netlink操作基于sockaddr_nl协议套接字,nl_family制定协议族,nl_pid表示进程pid,nl_groups用于多播。消息体由nlmsghdr和msghdr组成,用于发送和接收消息。内核创建socket并监听,用户态创建连接并收发信息。
Netlink关键数据结构和函数:sockaddr_nl用于表示地址,nlmsghdr作为消息头部,msghdr用于用户态发送消息。内核函数如netlink_kernel_create用于创建内核socket,netlink_unicast和netlink_broadcast用于单播和多播。
Netlink用户态建立连接和收发信息:提供测试例子代码,代码在github仓库中,可自行测试。核心代码包括接收函数打印接收到的消息。
总结:Netlink是一个强大的内核和用户空间交互方式,适用于主动交互场景,如内核数据审计、安全触发等。早期iptables使用netlink下发配置指令,但在iptables后期代码中,使用了iptc库,核心思路是使用setsockops和copy_from_user。对于配置下发场景,netlink非常实用。
链接:内核通信之Netlink源码分析和实例分析
React源码分析4-深度理解diff算法
React 每次更新,都会通过 render 阶段中的 reconcileChildren 函数进行 diff 过程。这个过程是 React 名声远播的优化技术,对新的 ReactElement 内容与旧的 fiber 树进行对比,从而构建新的 fiber 树,将差异点放入更新队列,对真实 DOM 进行渲染。简单来说,diff 算法是为了以最低代价将旧的 fiber 树转换为新的 fiber 树。
经典的 diff 算法在处理树结构转换时的时间复杂度为 O(n^3),其中 n 是树中节点的个数。在处理包含 个节点的应用时,这种算法的性能将变得不可接受,需要进行优化。React 通过一系列策略,将 diff 算法的时间复杂度优化到了 O(n),实现了高效的更新 virtual DOM。
React 的 diff 算法优化主要基于以下三个策略:tree diff、component diff 和 element diff。tree diff 策略采用深度优先遍历,仅比较同一层级的元素。当元素跨层级移动时,React 会将它们视为独立的更新,而不是直接合并。
component diff 策略判断组件类型是否一致,不一致则直接替换整个节点。这虽然在某些情况下可能牺牲一些性能,但考虑到实际应用中类型不一致且内容完全一致的情况较少,这种做法有助于简化 diff 算法,保持平均性能。
element diff 策略通过 key 对元素进行比较,识别稳定的渲染元素。对于同层级元素的比较,存在插入、删除和移动三种操作。这种策略能够有效管理 DOM 更新,确保性能。
结合源码的 diff 整体流程从 reconcileChildren 函数开始,根据当前 fiber 的存在与否决定是直接渲染新的 ReactElement 内容还是与当前 fiber 进行 Diff。主要关注的函数是 reconcileChildFibers,其中的细节与具体参数的处理方式紧密相关。不同类型的 ReactElement(如 REACT_ELEMENT_TYPE、纯文本类型和数组类型)将走不同的 diff 流程,实现更高效、针对性的处理。
diff 流程结束后,形成新的 fiber 链表树,链表树上的 fiber 标记了插入、删除、更新等副作用。在完成 unitWork 阶段后,React 构建了一个 effectList 链表,记录了需要进行真实 DOM 更新的 fiber。在 commit 阶段,根据 effectList 进行真实的 DOM 更新。下一章将深入探讨 commit 阶段的详细内容。
HTTP连接池及源码分析(一)
HTTP连接池是一个管理与复用HTTP连接的高效技术,它旨在提高HTTP请求的性能与效率。尤其在高并发场景中,传统每次请求建立新TCP连接并关闭,这种操作可能引起性能瓶颈。连接池通过预先创建并复用一定数量的连接,有效管理资源,避免了因等待连接而造成的性能下降。
构建HTTP连接池的核心在于提升并发场景下的系统性能。当一个连接被占用,其他客户端线程需要等待,因此复用已有的连接成为关键。HTTP连接池通过维护目标主机与端口号跟踪连接复用情况,当找到可复用连接时,将请求发送至该连接,避免了创建新连接。连接池策略考虑安全性、空闲时间等因素,确保高效复用。
使用HTTP连接池时,首先在Maven仓库选择合适的httpclient包,如版本4.5.,配置依赖。一个简单使用案例即可完成基本操作。核心对象包括PoolingHttpClientConnectionManager与CloseableHttpClient,PoolingHttpClientConnectionManager管理连接池,CloseableHttpClient提供可关闭的HTTP客户端。
PoolingHttpClientConnectionManager的官方解释强调,它维护连接池,服务多线程的连接请求,基于路由管理连接,重用已有的连接而非每次创建新连接。设置setMaxTotal限制总连接数,避免资源过度占用,setDefaultMaxPerRoute确保对单个目标主机的并发请求平衡,提高整体性能。
Apache HttpClient库的配置通过HttpClients.custom()方法开始,设置连接管理器连接池对象,使用build()方法构建配置好的CloseableHttpClient实例,确保资源高效管理与释放。
理解连接池管理对象与HTTP客户端对象是关键,它们协同作用提升HTTP请求性能。连接池原理涉及路由管理、复用策略,通过源码探索可深入理解其内部机制与优化点。
cglib底层源码分析(⼀)
cglib是一种动态代理技术,用于生成代理对象。例如,现有UserService类。使用cglib增强该类中的test()方法。
分析底层源码前,先尝试用cglib代理接口。定义UserInterface接口,利用cglib代理,正常运行。
代理类是由cglib生成,想知道代理类生成过程?运行时添加参数:1 -Dcglib.debugLocation=D:\IdeaProjects\cglib\cglib\target\classes。cglib将代理类保存至指定路径。
比较代理类,代理UserService与代理UserInterface的区别:UserService代理类是UserService的子类,UserInterface代理类实现了UserInterface。
代理类中,test()方法及CGLIB$test$0()方法存在,后者用于执行增强逻辑。若不设置Callbacks,则代理对象无法正常工作。
代理类中另一个方法通过设置的Callback(MethodInterceptor中的MethodProxy对象)调用。MethodProxy表示方法代理,执行流程进入intercept()方法时,MethodProxy对象即为所调用方法。
执行methodProxy.invokeSuper()方法,执行CGLIB$test$0()方法。总结cglib工作原理:生成代理类作为Superclass子类,重写Superclass方法,Superclass方法对应代理类中的重写方法和CGLIB$方法。
接下来的问题:代理类如何生成?MethodProxy如何实现?下篇文章继续探讨。
Golang源码分析Golang如何实现自举(一)
本文旨在探索Golang如何实现自举这一复杂且关键的技术。在深入研究之前,让我们先回顾Golang的历史。Golang的开发始于年,其编译器在早期阶段是由C语言编写。直到Go 1.5版本,Golang才实现了自己的编译器。研究自举的最佳起点是理解从Go 1.2到Go 1.3的版本,这些版本对自举有重要影响,后续还将探讨Go 1.4。
接下来,我们来了解一下Golang的编译过程。Golang的编译主要涉及几个阶段:词法解析、语法解析、优化器和生成机器码。这一过程始于用户输入的“go build”等命令,这些命令实际上触发了其他内部命令的执行。这些命令被封装在环境变量GOTOOLDIR中,具体位置因系统而异。尽管编译过程看似简单,但实际上包含了多个复杂步骤,包括词法解析、语法解析、优化器、生成机器码以及连接器和buildid过程。
此外,本文还将介绍Golang的目录结构及其功能,包括API、文档、C头文件、依赖库、源代码、杂项脚本和测试目录。编译后生成的文件将被放置在bin和pkg目录中,其中bin目录包含go、godoc和gofmt等文件,pkg目录则包含动态链接库和工具命令。
在编译Golang时,首先需要了解如何安装GCC环境。为了确保兼容性,推荐使用GCC 4.7.0或4.7.1版本。通过使用Docker镜像简化了GCC的安装过程,使得编译变得更为便捷。编译Golang的命令相对简单,通过执行./all即可完成编译过程。
最后,本文对编译文件all.bash和make.bash进行了深入解析。all.bash脚本主要针对nix系统执行,而make.bash脚本则包含了编译过程的关键步骤,包括设置SELinux、编译dist文件、编译go_bootstrap文件,直至最终生成Golang可执行文件。通过分析这些脚本,我们可以深入了解Golang的自举过程,即如何通过go_bootstrap文件来编译生成最终的Golang。
总结而言,Golang的自举过程是一个复杂且多步骤的技术,包含了从早期C语言编译器到自动生成编译器的转变。通过系列文章的深入探讨,我们可以更全面地理解Golang自举的实现细节及其背后的逻辑。本文仅是这一过程的起点,后续将详细解析自举的关键组件和流程。
2024-12-22 09:30
2024-12-22 09:18
2024-12-22 08:23
2024-12-22 07:37
2024-12-22 07:20
2024-12-22 06:59
