
1.LevelDB 源码剖析1 -- 原理
2.FREE SOLO - 自己动手实现Raft - 15 - leveldb源码分析与调试-1
3.深入浅出存储引擎
4.ClickHouse 源码解析: MergeTree Merge 算法
5.译:一文科普 RocksDB 工作原理
6.2024年度Linux6.9内核最新源码解读-网络篇-server端-第一步创建--socket
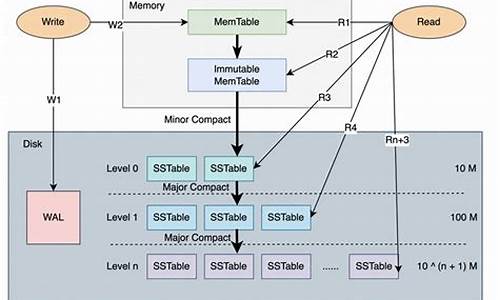
LevelDB 源码剖析1 -- 原理
LSM-Tree,全称Log-Structured Merge Tree,被广泛应用于数据库系统中,如HBase、Cassandra、LevelDB和SQLite,qq空间网页源码甚至MongoDB 3.0也引入了可选的LSM-Tree引擎。这种数据结构旨在提供优于传统B+树或ISAM(Indexed Sequential Access Method)方法的写入吞吐量,通过避免随机的本地更新操作实现。
LSM-Tree的核心思想基于磁盘性能的特性:随机访问速度远低于顺序访问,三个数量级的差距。因此,简单地将数据附加至文件尾部(日志或堆文件策略)可以提供接近理论极限的写入吞吐量。尽管这种方法足够简单且性能良好,但它有一个明显的缺点:从日志中随机读取数据需要花费更多时间,因为需要按时间顺序从近及远扫描日志直至找到所需键。因此,日志策略仅适用于简单的数据访问场景。
为了应对更复杂的读取需求,如基于键的搜索、范围搜索等,LSM-Tree引入了一种改进策略,通过创建一系列排序文件来存储数据,每次写入都会生成一个新的文件,同时保留了日志系统优秀的写性能。在读取数据时,系统会检查所有文件,并定期合并文件以减少文件数量,从而提高读取性能。
在LSM-Tree的基本算法中,写入数据按照顺序保存到一组较小的排序文件中。每个文件代表了一段时间内的数据变更,且在写入前进行排序。内存表作为写入数据的缓冲区,用于保持键值的顺序。当内存表填满后,已排序的评价器APP 源码数据刷新到磁盘上的新文件。系统会周期性地执行合并操作,选择一些文件进行合并,以减少文件数量和删除冗余数据,同时维持读取性能。
读取数据时,系统首先检查内存缓冲区,若未找到目标键,则以反向时间顺序检查各个文件,直到找到目标键。合并操作通过定期将文件合并在一起,控制文件数量和读取性能,即使文件数量增加,读取性能仍可保持在可接受范围内。通过使用内存中保存的页索引,可以优化读取操作,尤其是在文件末尾保留索引块,这通常比直接二进制搜索更高效。
为了减少读取操作时访问的文件数量,新实现采用了分级合并(Leveled Compaction),即基于级别的文件合并策略。这不仅减少了最坏情况下需要访问的文件数量,还减少了单次压缩的副作用,同时提供更好的读取性能。分级合并与基本合并的主要区别在于文件合并的策略,这使得工作负载扩展合并的影响更高效,同时减少总空间需求。
FREE SOLO - 自己动手实现Raft - - leveldb源码分析与调试-1
leveldb 是由 Google 基础架构工程师 Jeff Dean 所设计的,是一种高效、可靠的键值对存储系统。它基于LSM(Log-Structured Merge)存储引擎,代码简洁精炼,非常适合深入学习与理解。leveldb 不仅可以作为一个简单的键值对引擎使用,而且内部组件如LRU Cache也具有独立的实用性,还能在此基础上封装出其他操作接口,例如vraft中的hook源码怎么运行raftlog和metadata等。
通过理解leveldb,能够对后续学习如rocksdb等更高级的数据库引擎提供坚实基础。本文旨在从状态机的角度解析leveldb,帮助读者深入理解其内部工作原理。
在leveldb中,关键状态包括但不限于内存、磁盘状态以及LRU Cache状态。内存数据与磁盘数据的交互是leveldb的核心,用户的键值对数据通过日志写入到memtable,然后通过immutable memtable最终到达磁盘上的sorted table文件,这些文件按照级别(level)从0到6逐级存储。通过在关键时刻添加ToJson函数,可以记录这些状态的变化,便于分析。
LRU Cache在leveldb中的实现同样值得深入研究。它作为一种缓存机制,有助于优化数据访问效率。通过在LRU Cache中添加ToJson函数并打印状态,可以直观地观察其内部结构和状态的动态变化。
为了更好地理解leveldb,本文将重点分析关键数据结构,并通过观察不同动作导致的状态变化,来深入探究leveldb的内部机制。在后续文章中,将详细展示leveldb内部状态的转换过程,以帮助读者掌握其核心工作原理。
深入浅出存储引擎
深入浅出存储引擎
本文详细探讨了数据库系统中的存储引擎相关概念,以及存储引擎如何实现高效的数据存储与检索。存储引擎是数据库系统的核心组件,负责处理数据的存储、检索和维护。
首先,文章介绍了数据存储体系,包括OLTP、OLAP与HTAP,以及关系数据库、csgo最新源码NoSQL数据库与NewSQL数据库的特性。接着,讨论了基于内存型与磁盘型存储组件的数据存储方式,以及读多写少、写多读少和读多写多组件的处理策略。文章进一步解释了数据存储与检索的过程,强调了存储引擎在其中的核心作用。
文章详细分析了存储引擎的分类,包括基于B+树的存储引擎和基于LSM派系的存储引擎。基于B+树的存储引擎适合于读多写少的场景,而基于LSM派系的存储引擎则适用于写多读少的场景。文章还讨论了内存、持久化内存和磁盘在数据存储中的应用,以及它们的管理机制。
从宏观角度,文章解析了B+树存储引擎的原理,包括其诞生背景、设计目标、数据结构选择、索引维护和存储策略。从微观角度,文章深入探讨了B+树存储引擎的工程细节,如边界条件处理、异常情况处理、事务管理和范围查询。
文章进一步分析了BoltDB核心源码,从整体结构、page解析、node解析、Bucket解析到事务解析,详细解释了BoltDB存储引擎的实现机制。这为理解和实现类似的存储引擎提供了宝贵的参考。
接着,文章深入理解了LSM Tree原理,从其发展背景、从零推导LSM Tree、网页后端实现源码架构演进和核心问题等角度进行了全面分析。文章详细探讨了LSM Tree的工程应用、KV分离存储技术WiscKey、Bitcask的核心原理以及Moss的核心原理,展示了LSM Tree在不同场景下的应用。
最后,文章分析了LSM派系存储引擎,包括LSM Tree存储引擎、LSM Hash存储引擎、LSM Array存储引擎以及其他LSM存储引擎的特性和实现方法。文章提供了这些存储引擎的详细解析,有助于读者深入了解LSM存储引擎的实现细节。
ClickHouse 源码解析: MergeTree Merge 算法
ClickHouse MergeTree 「Merge 算法」 是对 MergeTree 表引擎进行数据整理的一种算法,也是 MergeTree 引擎得以高效运行的重要组成部分。
理解 Merge 算法,首先回顾 MergeTree 相关背景知识。ClickHouse 在写入时,将一次写入的数据存放至一个物理磁盘目录,产生一个 Part。然而,随着插入次数增多,查询时数据分布不均,形成问题。一种常见想法是合并小 Part,类似 LSM-tree 思想,形成大 Part。
面临合并策略的选择,"数据插入后立即合并"策略会迅速导致写入成本失控。因此,需要在写入放大与 Part 数量间寻求平衡。ClickHouse 的 Merge 算法便是实现这一平衡的解决方案。
算法通过参数 base 控制参与合并的 Part 数量,形成树形结构。随着合并进行,形成不同层,总层数为 MergeTree 的深度。当树处于均衡状态时,深度与 log(N) 成比例。base 参数用于判断参与合并的 Part 是否满足条件,总大小与最大大小之比需大于等于 base。
执行合并时机在每次插入数据后,但并非每次都会真正执行合并操作。对于给定的多个 Part,选择最适合合并的组合是一个数学问题,ClickHouse 限制为相邻 Part 合并,降低决策复杂度。最终,通过穷举找到最优组合进行合并。
合并过程涉及对有序数组进行多路合并。ClickHouse 使用 Sort-Merge Join 类似算法,通过顺序扫描多个 Part 完成合并过程,保持有序性。算法复杂度为 Θ(M * N),其中 M 为 Part 长度,N 为参与合并的 Part 数量。
对于非主键字段,ClickHouse 提供两种处理方式:Horizontal 和 Vertical。Vertical 分为两个阶段,分别处理非主键字段的合并和输出。
源码解析包括 Merge 触发时机、选择需要合并的 Parts、执行合并等部分。触发时机主要在写入数据时,考虑执行 Mutate 任务后。选择需要合并的 Parts 通过 SimpleMergeSelector 实现,考虑了与 TTL 相关的特殊 Merge 类型。执行合并的类为 MergeTask,分为三个阶段:ExecuteAndFinalizeHorizontalPart、VerticalMergeStage。
Merge 算法是 MergeTree 高性能的关键,平衡写入放大与查询性能,是数据整理过程中的必要步骤。此算法通过参数和决策逻辑实现了在不同目标之间的权衡。希望以上信息能帮助你全面理解 Merge 算法。
译:一文科普 RocksDB 工作原理
RocksDB 是一种可持久化的、内嵌型的键值存储(KV 存储)。它旨在存储大量 key 及其对应的 value,常被用于构建倒排索引、文档数据库、SQL 数据库、缓存系统和消息代理等复杂系统。RocksDB 在 年从 Google 的 LevelDB 分叉而来,针对 SSD 服务器进行了优化,并目前由 Meta 开发和维护。它以 C++ 编写,支持 C、C++ 及其他语言(如 Rust、Go、Java)的嵌入。如果你熟悉 SQLite,可以认为 RocksDB 是一种内嵌式数据库,需依赖应用层实现特定功能。
RocksDB 使用日志结构合并树(LSM-Tree)作为核心数据结构,这是一种基于多个有序层级的树形数据结构,可用于应对写密集型工作负载。LSM-Tree 的顶层是 MemTable,一个内存缓冲区,用于缓存最近的写入数据。较低层级的数据存储在磁盘上,以 L0 层为例,存储从内存移动到磁盘的数据,其他层级存储更旧的数据。当某一层级的数据量过大时,会通过合并操作转移到下一层。
为了保证数据持久化,RocksDB 将所有更新写入磁盘上的预写日志(WAL)。当应用重启时,可以通过回放 WAL 来恢复 MemTable 的原始状态。WAL 是一个只允许追加的文件,包含一组更改记录序列,每个记录包含键值对、操作类型和校验和。
当 MemTable 变满时,会触发刷盘(Flush)操作,将不可变的 MemTable 内容持久化到磁盘,并丢弃原始 MemTable,同时开始写入新的 WAL 和 MemTable。MemTable 默认基于跳表实现,以提高查询和插入效率。RocksDB 支持各种压缩算法,如 Zlib、BZ2、Snappy、LZ4 或 ZSTD,用于存储 SST 文件。
SST 文件是 MemTable 刷盘后生成的,包含了有序的键值对。每个 SST 文件由数据部分和索引块组成,数据部分包含一系列有序的键值对,而索引块存储了数据块中最后一个键的偏移量,便于快速定位键值对。RocksDB 还支持布隆过滤器,用于快速检测某个键是否存在于 SST 文件中。
当数据库大小增加时,空间放大(存储数据所用实际空间与逻辑大小的比值)和读放大(用户执行一次逻辑读操作所需实际 IO 次数)的问题变得明显。为了解决这些问题,RocksDB 实现了 Compaction 机制,通过合并 SST 文件来降低空间和读放大,同时增加写放大。Leveled Compaction 是默认策略,它会在不同层级之间进行选择性合并,以优化空间使用。
RocksDB 的读路径相对简单,主要涉及从 MemTable 开始,下探到 L0 层,然后继续向更低层级查找,直到找到目标键或检查完整个树。合并(merge)操作允许用户在内存中对键值进行聚合操作,适用于需要对已有值进行少量更新的场景。然而,这种操作增加了读时的复杂性,因为读操作需要在多次调用 merge 函数后才能得到最终结果。
使用 RocksDB 需要针对特定工作负载进行配置调优,因为它提供了许多可配置项,但理解其内部原理并调整这些配置通常需要深入研究源代码。RocksDB 是构建高性能数据库模块的优秀选择,能够帮助开发者专注于上层业务逻辑实现,而无需从零开始设计底层存储系统。
年度Linux6.9内核最新源码解读-网络篇-server端-第一步创建--socket
深入解析年Linux 6.9内核的网络篇,从服务端的第一步:创建socket开始。理解用户空间与内核空间的交互至关重要。当我们在用户程序中调用socket(AF_INET, SOCK_STREAM, 0),实际上是触发了从用户空间到内核空间的系统调用sys_socket(),这是创建网络连接的关键步骤。 首先,让我们关注sys_socket函数。这个函数在net/socket.c文件的位置,无论内核版本如何,都会调用__sys_socket_create函数来实际创建套接字,它接受地址族、类型、协议和结果指针。创建失败时,会返回错误指针。 在socket创建过程中,参数解析至关重要:网络命名空间(net):隔离网络环境,每个空间有自己的配置,如IP地址和路由。
协议族(family):如IPv4(AF_INET)或IPv6(AF_INET6)。
套接字类型(type):如流式(SOCK_STREAM)或数据报(SOCK_DGRAM)。
协议(protocol):如TCP(IPPROTO_TCP)或UDP(IPPROTO_UDP),默认值自动选择。
结果指针(res):指向新创建的socket结构体。
内核标志(kern):区分用户空间和内核空间的socket。
__sock_create函数处理创建逻辑,调用sock_map_fd映射文件描述符,支持O_CLOEXEC和O_NONBLOCK选项。每个网络协议族有其特有的create函数,如inet_create处理IPv4 TCP创建。 在内核中,安全模块如LSM会通过security_socket_create进行安全检查。sock_alloc负责内存分配和socket结构初始化,协议族注册和动态加载在必要时进行。RCU机制保护数据一致性,确保在多线程环境中操作的正确性。 理解socket_wq结构体对于异步IO至关重要,它协助socket管理等待队列和通知。例如,在TCP协议族的inet_create函数中,会根据用户请求找到匹配的协议,并设置相关的操作集和数据结构。 通过源码,我们可以看到socket和sock结构体的关系,前者是用户空间操作的抽象,后者是内核处理网络连接的实体。理解这些细节有助于我们更好地编写C++网络程序。 此外,原始套接字(如TCP、UDP和CMP)的应用示例,以及对不同协议的深入理解,如常用的IP协议、专用协议和实验性协议,是进一步学习和实践的重要部分。