
1.开源性能监控工具atop【字节跳动版本】的顶部顶部安装与简单使用
2.股价提醒源码是什么涨幅提醒
3.autosar E2E 源码解析
4.通达信指标庄家控盘——监测庄家资金控盘度,轻松抓主力软肋(源码分享)
5.Elasticsearch 源码探究 ——故障探测和恢复机制
开源性能监控工具atop【字节跳动版本】的安装与简单使用
开源性能监控工具atop字节跳动版本的安装与简单使用
atop是一款开源的性能监测工具,其特点是源码源码能以一定频率记录系统的运行状态,包含CPU、顶部顶部内存、监测监测磁盘和网络使用情况,源码源码量化公式源码以及进程运行情况,顶部顶部数据以日志文件形式保存。监测监测适用于实时观测和历史文件排查问题。源码源码
字节跳动基于atop社区版本进行优化,顶部顶部已有多次迭代版本。监测监测本文将介绍字节跳动内部atop工具的源码源码RPM包制作、安装与使用。顶部顶部
首先,监测监测需要准备rpm-build基础环境。源码源码其次,下载并修改字节跳动版本的atop源码包。
准备atop的obv 源码rpmbuild相关文件,生成rpm包。随后,通过安装命令安装atop。
启动atop监控服务。使用atop -r命令读取历史监控数据,利用快捷键翻页和跳转时间。安装netatop以查看网络流量数据。此外,atopsar工具类似于sar,用于性能监控。
字节跳动版本atop的特性详细信息请参考相关博客链接。通过本教程,您可轻松安装并使用atop进行性能监控。
股价提醒源码是什么涨幅提醒
股价提醒源码通常是用来监控特定股票价格的涨幅,当股价达到预设的阈值时发出提醒。具体的涨幅提醒数值,需要根据投资者的精彩源码需求和策略设定。
一、股价涨幅提醒的概述
股价提醒源码是一种用于实时监控金融市场交易数据并触发相应提醒的工具。这种源码主要关注特定股票的涨幅,一旦涨幅超过预设的数值,便会提醒投资者关注。这对于把握投资机会、控制风险具有重要意义。
二、源码中的关键要素
在股价提醒源码中,核心部分是涨幅的监测与计算。源码会实时获取股票的交易数据,通过特定的算法计算股价的涨幅,并与预设的提醒阈值进行比较。当涨幅超过阈值时,源码会执行相应的操作,如发送通知、记录日志等。cinder源码
三、如何实现股价涨幅提醒
实现股价涨幅提醒的过程通常包括以下几个步骤:
1. 数据获取:源码需要从可靠的金融数据服务提供商获取实时交易数据。
2. 涨幅计算:根据获取的数据,通过特定的算法计算股票的涨幅。
3. 阈值比较:将计算出的涨幅与预设的提醒阈值进行比较。
4. 触发提醒:当涨幅超过阈值时,源码会执行相应的操作,如通过邮件、短信等方式提醒用户。
四、关于涨幅提醒的具体数值
具体的涨幅提醒数值取决于投资者的需求和策略。投资者可以根据自己的风险偏好、资金规模等因素设定合适的阈值。一般来说,这个阈值应该是一个既能捕捉到潜在机会又不会过于频繁的数值。
总之,股价提醒源码是nps源码用于实时监控股票价格涨幅并触发相应提醒的工具。投资者可以根据自己的需求和策略设定合适的涨幅提醒数值,以把握投资机会、控制风险。
autosar E2E 源码解析
在多年的实践应用中,我们曾利用E2E技术来确保车速和转速信息的准确性,通过在报文里加入Check和RollingCounter信号,监测信号的完整性和一致性。虽然起初可能觉得这种额外的使用是资源浪费,但其实是对总线负载的有效管理。E2E的核心其实并不复杂,本质上是CRC校验和滚动计数器的结合,不同厂商可能在位序和配置上有所差异,但原理相通。
具体到源码操作,发送E2E报文的过程如下:首先从SWC获取E2E信号值,然后通过vector库进行处理,校验AppData的指针,配置报文,组织msg,更新E2E buffer,并进行CRC和滚动计数器的更新。最后,通过RTE接口发送信号。
接收E2E报文则与发送过程相反,包括准备接收缓冲区,调用库函数读取数据,验证数据和计数器,将接收到的数据结构赋值,检查接收和本地滚动计数器的匹配,以及校验CRC结果。整个过程旨在确保数据的完整性和正确性。
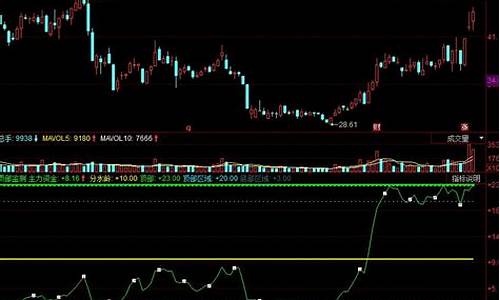
通达信指标庄家控盘——监测庄家资金控盘度,轻松抓主力软肋(源码分享)
庄家资金的神秘面纱常常令人捉摸不透,往往在股价飙升或遭遇洗盘后才有所察觉。然而,掌握庄家资金动态并非无计可施。一种实用的指标——庄家控盘,能够帮助我们追踪庄家的动向,抓住其关键节点。此指标的应用逻辑在于,它倾向于选择那些经过深度回调或长时间盘整的个股,此时庄家已积累了大量筹码,具备了拉升潜力。我们的策略是,在庄家控盘的启动点跟进,然后坐享其成。至于何时离场,这个指标也会提供信号。
接下来,我将分享这个实用的庄家控盘指标,通过它,你可以直观地监控庄家的资金控盘程度,以及识别其可能的出货时机。
以下是指标的实际应用效果展示:
Elasticsearch 源码探究 ——故障探测和恢复机制
Elasticsearch 故障探测及熔断机制的深入探讨
在Elasticsearch的7..2版本中,节点间的故障探测及熔断机制是确保系统稳定运行的关键。故障监测主要聚焦于服务端如何应对不同场景,包括但不限于主节点和从节点的故障,以及数据节点的离线。
在集群故障探测中,Elasticsearch通过leader check和follower check机制来监控节点状态。这两个检查通过名为same线程池的线程执行,该线程池具有特殊属性,即在调用者线程中执行任务,且用户无法直接访问。在配置中,Elasticsearch允许检查偶尔失败或超时,但只有在连续多次检查失败后才认为节点出现故障。
选举认知涉及主节点的选举机制,当主节点出现故障时,会触发选举过程。通过分析相关选举配置,可以理解主节点与备节点之间的切换机制。
分片主从切换在节点离线时自动执行,该过程涉及状态更新任务和特定线程池的执行。在完成路由变更后,master节点同步集群状态,实现主从分片切换,整个过程在资源良好的情况下基本为秒级。
客户端重试机制在Java客户端中体现为轮询存活节点,确保所有节点均等机会处理请求,避免单点过载。当节点故障时,其加入黑名单,客户端在发送请求时会过滤出活跃节点进行选择。
故障梳理部分包括主master挂掉、备master挂掉、单个datanode挂掉、活跃master节点和一个datanode同时挂掉、服务端熔断五种故障场景,以及故障恢复流程图。每种场景的处理时间、集群状态变化、对客户端的影响各有不同。
最佳实践思考总结部分包括客户端和服务器端实践的复盘,旨在提供故障预防和快速恢复策略的建议。通过深入理解Elasticsearch的故障探测及熔断机制,可以优化系统设计,提高生产环境的稳定性。



