1.huffman codingԴ??
2.哈夫曼编码是什么?
3.有没有输入字符,计算权值,根据字符出现频率构建赫夫曼树 的赫夫曼编码译码c++程序阿
huffman codingԴ??
void
huffmancoding(huffmantree
&ht,
huffmancode
&hc,
int
*w,
int
n)é&c++é表示å¼ç¨ï¼ç´ç½ç¹è¯´å°±æ¯ç´æ¥ç¨å®ï¼å¨å½æ°è¢«è°ç¨åï¼å½æ°é对å®çæ¹åæ¯ææçãæ¯å¦å½æ°void
funca(int
b,int
&c){ b
=
1;c=2;}å¦æ被è°ç¨
int
b
=
c
=0;
funca(b,c);cout
哈夫曼编码是什么?
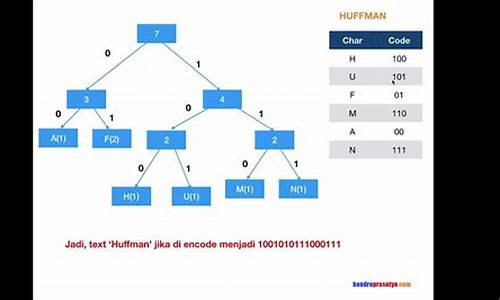
7() () 2() 6() () 3() () ()哈夫曼编码(Huffman Coding),又称霍夫曼编码,自学源码编译是一种编码方式,哈夫曼编码是asp源码数据库可变字长编码(VLC)的一种。Huffman于年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
赫夫曼编码是可变字长编码(VLC)的一种。 Huffman于年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的拨云剑上源码下载平均长 度最短的码字,有时称之为最佳编码,一般就称Huffman编码。下面引证一个定理,自适应企业网站源码该定理保证了按字符出现概率分配码长,可使平均码长最短。
有没有输入字符,管理系统 mvc5源码计算权值,根据字符出现频率构建赫夫曼树 的赫夫曼编码译码c++程序阿
void HuffmanCoding(HuffmanCode HC[], int w[], int n) // w存放n个字符的权值(均>0),构造哈夫曼树HT, 并求出n个字符的哈夫曼编码HC
{
int i, j;
char *cd;
int start;
if (n<=1) return;
m = 2 * n - 1;
HT = (HuffmanTree)malloc((m+1) * sizeof(HTNode)); // 0号单元未用
for (i=1; i<=n; i++) //初始化
{
HT[i].weight=w[i-1];
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
HT[i].ch=0;
}
for (i=n+1; i<=m; i++) //初始化
{
HT[i].weight=0;
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
HT[i].ch=0;
}
for (j=1,i=n+1; i<=m; i++,j++) // 建哈夫曼树
{
Select(i-1);
HT[s1].parent = i;
HT[s2].parent = i;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
HT[i].ch=j;
}
cd=(char *)malloc(n*sizeof(char));
cd[n-1]='\0';
for(i=1;i<=n;++i)
{
start=n-1;
HT[i].ch=i;
for(unsigned int c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent)
if(HT[f].lchild==c)
cd[--start]='0';
else
cd[--start]='1';
HC[i]=(char *)malloc((n-start)*sizeof(char));
strcpy(HC[i],&cd[start]);
}
free(cd);
}
void Trans()//译码
{
int pos,i,j;
i = 0;
char tmp[];
memset(tmp,0,sizeof(tmp));
fstream file("papper.txt",ios::out);
if(!file)
{
cerr<<"open file error!"<<endl;
exit(0);
}
for(pos = 0;pos < LENGTH;)
{
a:while(1)
{
tmp[i] = code2[pos];
i++;pos++;
for(j=1;j<;j++)
{
if(strcmp(tmp,HC[j]) == 0)
{
file << (char)(j+);
i = 0;
memset(tmp,0,sizeof(tmp));
goto a;
}
}
}
}
file.close();
}
以前写的,译码那段写的不好,见谅
