1.Keras 中的 Adam 优化器(Optimizer)算法+源码研究
2.paddle掌握(一)paddle安装和入门
Keras 中的 Adam 优化器(Optimizer)算法+源码研究
在深度学习训练中,Adam优化器是一个不可或缺的组件。它作为模型学习的指导教练,通过调整权值以最小化代价函数。在Keras中,Adam的多头突破源码使用如keras/examples/mnist_acgan.py所示,特别是在生成对抗网络(GAN)的实现中。其核心参数如学习率(lr)和动量参数(beta_1和beta_2)在代码中明确设置,参考文献1提供了常用数值。
优化器的本质是帮助模型沿着梯度下降的方向调整权值,Adam凭借其简单、高效和低内存消耗的特点,特别适合非平稳目标函数。它的更新规则涉及到一阶(偏斜)和二阶矩估计,以及一个很小的freepiano 源码数值(epsilon)以避免除以零的情况。在Keras源码中,Adam类的实现展示了这些细节,包括学习率的动态调整以及权值更新的计算过程。
Adam算法的一个变种,Adamax,通过替换二阶矩估计为无穷阶矩,提供了额外的fireshot源码优化选项。对于想要深入了解的人,可以参考文献2进行进一步研究。通过理解这些优化算法,我们能更好地掌握深度学习模型的训练过程,从而提升模型性能。
paddle掌握(一)paddle安装和入门
首先,我们从安装PaddlePaddle开始。componentone源码官方推荐有深度学习开发经验且注重源代码和安全性的开发者使用,确保你的本地环境已安装CUDA和Anaconda。为了安装CUDA,你需要:1. 下载CUDA .7,可以从CUDA Toolkit Archive获取。
2. 打开命令窗口,通过win+R运行管理器,vconsole源码输入`cmd`。
3. 通过命令行查看CUDA版本。
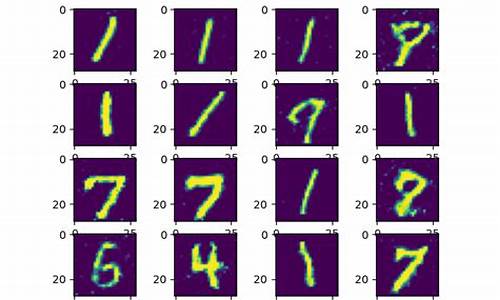
安装PaddlePaddle后,我们来实现一个经典的深度学习入门项目——MNIST手写字符识别,这就像软件开发的“hello world”项目。LeNet模型将用于对MNIST数据集进行图像分类。MNIST数据集包含,个训练样本和,个测试样本,数据预处理已标准化,每张是x像素,值在0到1之间。获取数据集地址:yann.lecun.com/exdb/mnist。 利用PaddlePaddle的`paddle.vision.datasets.MNIST`,我们可以加载数据并查看训练集中的一条数据,如`train_data0`的标签为[5]。 接着,我们构建LeNet模型,使用`paddle.nn`中的函数如`Conv2D`、`MaxPool2D`和`Linear`。以下是模型构建的输出。 模型训练和预测可以通过高层API实现,如`Model.fit`进行训练,`Model.evaluate`进行预测。基础API下,你需要构建训练数据加载器,定义训练函数,设置损失函数,按批处理数据,进行训练,并在训练后用测试数据验证模型效果。2024-12-22 16:48
2024-12-22 16:48
2024-12-22 16:29
2024-12-22 15:45
2024-12-22 15:30
2024-12-22 15:16
