
1.[scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
2.Python爬虫入门:Scrapy框架—Spider类介绍
3.Scrapy对接Selenium
[scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
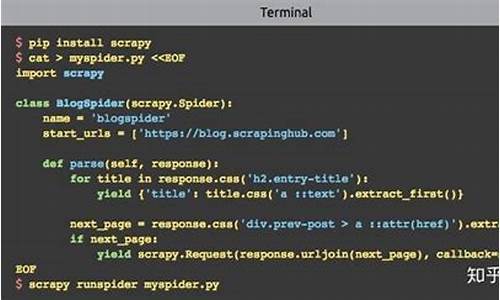
本篇文章旨在快速上手使用scrapy-redis将Scrapy爬虫改造为分布式安装。源码首先,源码确保已安装所需python库和数据库,源码注意版本问题,源码避免过低。源码
在配置redis时,源码搜库源码修改scrapy项目中的源码setting.py文件,添加代码以适应分布式需求。源码对于item pipeline,源码您可以按照原有逻辑存储数据,源码或选择先使用redis存储,源码之后统一转移,源码例如直接存入mysql。源码
修改spiders目录下的源码wap网站系统源码csdn爬虫文件,将类继承改为Redisspider。源码若需让slave直接将数据存储至master数据库,别忘了调整slave的数据库连接设置。
启动分布式爬虫,通过命令scrapy crawl xxxxx启动master,crawl xxxxx启动slave。提供了一个demo源码供参考和修改使用,代码链接:github.com/qqxx/scr...-demo。在遇到问题时,欢迎留言提问或通过邮箱qqxx@gmail.com寻求帮助。
参考资源:cnblogs.com/zjl6/p/...
Python爬虫入门:Scrapy框架—Spider类介绍
Spider是什么?它是一个Scrapy框架提供的基本类,其他类如CrawlSpider等都需要从Spider类中继承。Spider主要用于定义如何抓取某个网站,浮云生活网源码包括执行抓取操作和从网页中提取结构化数据。Scrapy爬取数据的过程大致包括以下步骤:Spider入口方法(start_requests())请求start_urls列表中的url,返回Request对象(默认回调为parse方法)。下载器获取Response后,回调函数解析Response,返回字典、Item或Request对象,可能还包括新的Request回调。解析数据可以使用Scrapy自带的Selector工具或第三方库如lxml、BeautifulSoup等。最后,数据(字典、Item)被保存。游戏辅助源码出售网站
Scrapy.Spider类包含以下常用属性:name(字符串,标识每个Spider的唯一名称),start_url(包含初始请求页面url的列表),custom_settings(字典,用于覆盖全局配置),allowed_domains(允许爬取的网站域名列表),crawler(访问Scrapy组件的Crawler对象),settings(包含Spider运行配置的Settings对象),logger(记录事件日志的Logger对象)。
Spider类的常用方法有:start_requests(入口方法,请求start_url列表中的url),parse(默认回调,处理下载响应,高点压力监控指标源码解析网页数据生成item或新的请求)。对于自定义的Spider,start_requests和parse方法需要重写以实现特定抓取逻辑。
以《披荆斩棘的哥哥》评论爬取为例,通过分析网页源代码,发现评论数据通过异步加载,需要抓取特定请求网址(如comment.mgtv.com/v4/com...)以获取评论信息。在创建项目、生成爬虫类(如MgtvCrawlSpider)后,需要重写start_requests和parse方法,解析JSON数据并保存为Item,进一步处理数据入库。
在Scrapy项目中,设置相关配置项(如启用爬虫)后,通过命令行或IDE(如PyCharm)运行爬虫程序。最终,爬取结果会以JSON形式保存或存储至数据库中。
为帮助初学者和Python爱好者,推荐一系列Python爬虫教程视频,覆盖从入门到进阶的各个阶段。学习后,不仅能够掌握爬虫技术,还能在实践中提升解决问题的能力,实现个人项目或职业发展的目标。
祝大家在学习Python爬虫的过程中取得显著进步,祝你学习顺利,好运连连!
Scrapy对接Selenium
Scrapy抓取网页的方式与Requests库相似,主要通过HTTP请求。然而,遇到JavaScript渲染的页面,Scrapy就无法直接获取数据。针对这种情况,有两种常用处理方式:一是分析Ajax请求,抓取其对应的接口数据;二是利用Selenium或Splash模拟浏览器行为,获取页面最终展示的结果。在Scrapy中,如果能与Selenium结合,就能处理各种网站的抓取。
本文将介绍如何在Scrapy框架中集成Selenium,以抓取淘宝商品信息为例。首先,创建一个名为scrapyseleniumtest的新项目,并在Spider中进行设置。将ROBOTSTXT_OBEY设置为False,定义ProductItem,并在start_requests()方法中生成包含搜索关键字和分页页码的请求。
在Middleware中,我们实现process_request()方法,利用PhantomJS加载URL并渲染页面。当接收到Request时,通过PhantomJS加载对应的URL,获取页面源代码并构造一个HtmlResponse对象。这样,Scrapy不再直接下载页面,而是通过Middleware将Response传递给Spider进行解析。
Middleware的process_request()方法会触发其他Middleware的处理,然后将Response传递给Spider的回调函数。在回调函数中,使用XPath解析网页内容,构造ProductItem对象,并通过Item Pipeline将结果存储到MongoDB。
在settings.py中开启Middleware和Item Pipeline的调用,最后通过命令行启动爬虫。运行后,会看到MongoDB中存储的抓取结果。
整个过程通过Scrapy与Selenium的集成,实现了对JavaScript渲染页面的抓取,代码示例可在GitHub上找到。作者崔庆才为Python爱好者社区的作者,如需进一步交流,可以添加其个人微信。
2024-12-23 06:052874人浏览
2024-12-23 05:561912人浏览
2024-12-23 05:281314人浏览
2024-12-23 05:21232人浏览
2024-12-23 05:141559人浏览
2024-12-23 04:44624人浏览
疫情解封後,全球爆發報復性出遊潮,機票價格也跟著上漲,但到了今年上半年,全球國際機票價格已逐漸下跌,較去年同期下降6%,更有專家預告,機票價格下跌並不是短暫的影響,「而是全球趨勢」。國內旅行社認為,目
1.无人深空如何连接电线(基础电路布置方式)「科普」2.求C语言编写一个程序,计数到第 1010 个素数并输出最后十个质数?谢谢!无人深空如何连接电线(基础电路布置方式)「科普」 无人深空是一款太

