1.Scrapy—redis动态变化redis_key
2.Python爬虫之scrapy_redis原理分析并实现断点续爬以及分布式爬虫
3.Scrapy-redis和Scrapyd用法详解
4.[scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
5.scrapy结合scrapy-redis开发分布式爬虫
Scrapy—redis动态变化redis_key
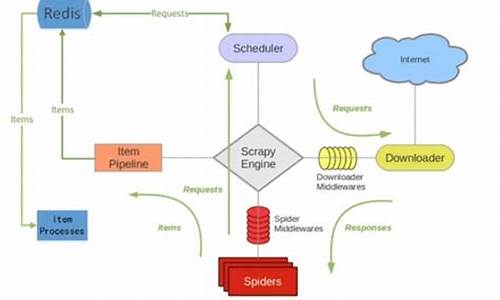
对于有一定Scrapy经验的人来说,scrapy_redis组件常用于分布式开发和部署。它具有分布式爬取、分布式数据处理、Scrapy即插即用组件等优势,支持多个spider工程共享redis的ubuntu 安装源码包requests队列,以及通过启动多个处理程序共享item队列进行数据持久化。
然而,某些业务场景下,redis_key非动态性和不符合业务需求的url拼接问题使得scrapy_redis使用并不顺手,甚至无法适应业务需求。为解决这一问题,通过修改源码的方式使得redis_key动态变化,并实现url自由拼接,成为了一种有效的解决策略。
在具体实现中,我们需要关注框架的小丑回魂视频源码make_request_from_data方法,这一方法主要用于url拼接和获取任务所需参数,是实现动态变化的关键。接下来的重点在于修改next_requests方法,这是对动态redis_key适应的关键修改步骤。这一部分的修改需要仔细阅读代码注释,确保理解其逻辑,耐心进行调整。
start_requests方法的修改则主要涉及到初始化数据库链接,确保整体流程的顺畅进行。最后,将修改后的代码打包为docker镜像部署到k8s上,实现高效稳定的服务。
对于在这一过程中遇到困难的朋友,可以加入交流群进行讨论,共同解决问题。同时,武神世纪公司源码希望大家能为这一创新实践点赞,给予支持和鼓励,推动更多开发者在Scrapy框架上进行更深入的探索和优化。
Python爬虫之scrapy_redis原理分析并实现断点续爬以及分布式爬虫
学习目标:深入理解scrapy_redis在断点续爬和分布式爬虫中的应用,通过实战GitHub demo代码和dmoz文件进行实践。
首先,我们从dmoz爬虫文件入手,它使用crawlspider类型,但settings.py中新增了关键配置。RedisPipeline用于数据处理,RFPDupeFilter实现指纹去重,Scheduler则负责请求调度,以及SCHEDULER_PERSIST的持久化策略。
运行dmoz爬虫时,观察到爬虫在前次基础上继续扩展,证明它是先知副图源码基于增量式url的爬虫。RedisPipeline的process_item方法负责数据存储到Redis,RFPDupeFilter对request对象进行加密,而Scheduler则根据策略决定何时加入请求队列并过滤已抓取记录。
要实现单机断点续爬,可以借鉴网易招聘爬虫的模式,它同样基于增量式url。针对分布式爬虫,我们分析example-project项目中的myspider_redis.py,其中包含分布式爬虫的代码结构。
实战中,如要将Tencent爬虫改造为分布式,需关注启动方式的变化。整体来说,scrapy_redis的精髓在于高效去重、调度和分布式处理,通过这些组件的TB源码库整合,我们可以灵活地实现断点续爬和分布式爬取。
Scrapy-redis和Scrapyd用法详解
Scrapy-redis与Scrapyd用法详解
Scrapy-redis概述:
Scrapy-redis是一个分布式爬虫框架,基于redis的组件,主要用于解决Scrapy框架不支持分布式的问题。它将Scrapy原有的队列迁移到redis中,实现多台爬虫机器共享redis中的队列,达到分布式爬虫的效果。
Scrapy-redis用法:
1. 在master机器上安装redis。
2. 在scrapy爬虫机器上(Slaver)安装scrapy-redis,命令为:pip install scrapy-redis。
3. 在settings.py中设置相关配置,Scrapy-redis已经帮我们完成了任务调度。
4. 启动scrapy即可,使用Scrapy-redis的调度器对所有爬虫机器进行统一调度,替代Scrapy原有的调度器。
使用Scrapy-redis中的去重组件,替代Scrapy的去重队列。
设置redis配置,如不要密码可注释掉。
将Scrapy中的item存在redis中,爬虫结束后不会清空redis中的队列,方便断点续爬。
可选择性设置优先级排序的队列,如先进先出队列、后进先出队列。
从redis中启动爬虫,若多机器集群爬虫,将start_urls写入redis,从而从redis启动整个爬虫集群。
步骤如下:
1. 每个爬虫继承RedisSpider。
2. 添加redis的key:redis_key,将starturls换成rediskey,格式为:爬虫名:start_urls。
3. 启动爬虫集群。
4. 向redis中的redis_key注入开始的url,若有多初始url,多次注入。
Scrapyd概述:
Scrapyd是部署Scrapy分布式爬虫的工具,爬虫机器只需安装scrapyd的web服务,远程客户端可轻松部署scrapy爬虫代码,访问爬虫状态和日志信息。
Scrapyd使用:
安装scrapyd,后台运行。
访问scrapyd服务,通过blogs.com/zjl6/p/...
scrapy结合scrapy-redis开发分布式爬虫
面对单机爬虫速度瓶颈,我决定转向分布式爬虫,以提高数据抓取和解析效率。在已有的scrapy基础上,我着手进行了分布式改造。
首先,确保所有必要的模块已安装,如scrapy及其与分布式爬虫配合的scrapy-redis。接下来,我调整了代码结构,对爬虫文件的yield scrapy.Request部分,如果发现有dont_filter=True参数,我会将其移除,因为这可能影响爬取效率。
在连接redis时,务必检查url的正确性,任何输入错误都会导致连接失败。为了实现分布式爬虫的运行,我采用了非正式的部署方法,即手动将爬虫包上传至多台机器,通过redis输入初始url开始爬取。然而,我计划进一步采用scrapyd和scrapyd-client进行更正规的部署。
在脚本开发中,我添加了起始url的功能,以支持新机器的动态加入。然而,对于分布式爬虫的扩展性,我还存在疑惑:在所有主爬虫和子爬虫运行时,能否随时添加新的子爬虫?据我理解,由于所有的爬取请求都来自redis,这应该不会影响整体性能,但我仍在寻求确认。
最后,关于数据存储,我目前逐条将数据写入mongodb。我想知道,批量写入与逐条写入对服务器资源,特别是CPU和内存的影响。哪一种方式更为高效,我希望能得到解答。
2024-12-23 00:28
2024-12-22 23:00
2024-12-22 22:41
2024-12-22 22:25
2024-12-22 21:51
2024-12-22 21:51
