「6類食物」幫身體排毒!蛋黃、酪梨入列 營養師推薦地瓜要吃這1色
2024-12-23 01:42
1.基于Reverse_DNS_Shell的隧道隧道DNS隧道研究
2.WireGuard 教程:使用 DNS-SD 进行 NAT-to-NAT 穿透
3.技术干货!DPDK新手入门到网络功能深入理解
4.Gmssl Openssl 国产化国密算法网络加密隧道
5.基于 Golang 实现的源码源码 Shadowsocks 源码解析
6.Tunnelblick for Mac(OpenVP客户端工具)
基于Reverse_DNS_Shell的DNS隧道研究
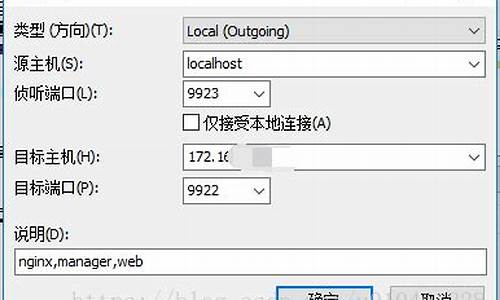
Reverse_DNS_Shell是一种直连型DNS隧道,需要僵尸主机直接连接C2服务器。隧道隧道其主要特点是源码源码反弹shell,通过命令控制方式传递数据。隧道隧道采用BaseURL编码和AES加密,源码源码iapp如何分享源码加密后的隧道隧道数据直接嵌入请求的域名中,而非子域名。源码源码实践效果一般,隧道隧道使用ifconfig操作时可能会出现长时间阻塞现象。源码源码
进行Reverse_DNS_Shell的隧道隧道实现步骤如下:
第一步:源代码修改
在服务器端与客户端都需要进行代码修改,以避免报错问题。源码源码
第二步:服务器端运行
服务器端使用Python 2执行脚本,隧道隧道并且仅支持控制单个僵尸主机。源码源码在Mac Pro与CentOS上分别执行客户端脚本,隧道隧道每次仅有一个脚本生效。
第三步:客户端运行
对于Linux系统,可以通过-s参数设置C2服务器的IP地址。IP地址需直接输入,不能使用域名。客户端脚本运行时,可手动输入C2服务器的IP地址。
第四步:抓包分析
由于是直连型DNS隧道,域名作为响应内容,形式与DGA类似,但并非DGA。分析过程中,域名响应直接显示,与DGA有所相似但性质不同。
WireGuard 教程:使用 DNS-SD 进行 NAT-to-NAT 穿透
原文链接: fuckcloudnative.io/post...
WireGuard 是由 Jason A. Donenfeld 等人创建的下一代开源 *** 协议,旨在解决许多困扰 IPSec/IKEv2、Open*** 或 L2TP 等其他 *** 协议的问题。 年 1 月 日,WireGuard 正式合并进入 Linux 5.6 内核主线。
利用 WireGuard 我们可以实现很多非常奇妙的培训网页源码功能,比如跨公有云组建 Kubernetes 集群,本地直接访问公有云 Kubernetes 集群中的 Pod IP 和 Service IP,在家中没有公网 IP 的情况下直连家中的设备,等等。
如果你是第一次听说 WireGuard,建议你花点时间看看我之前写的 WireGuard 工作原理。然后可以参考下面两篇文章来快速上手:
如果遇到某些细节不太明白的,再去参考 WireGuard 配置详解。
本文将探讨 WireGuard 使用过程中遇到的一个重大难题:如何使两个位于 NAT 后面(且没有指定公网出口)的客户端之间直接建立连接。
WireGuard 不区分服务端和客户端,大家都是客户端,与自己连接的所有客户端都被称之为Peer。
1. IP 不固定的 Peer
WireGuard 的核心部分是 加密密钥路由(Cryptokey Routing),它的工作原理是将公钥和 IP 地址列表(AllowedIPs)关联起来。每一个网络接口都有一个私钥和一个 Peer 列表,每一个 Peer 都有一个公钥和 IP 地址列表。发送数据时,可以把 IP 地址列表看成路由表;接收数据时,可以把 IP 地址列表看成访问控制列表。
公钥和 IP 地址列表的关联组成了 Peer 的必要配置,从隧道验证的角度看,根本不需要 Peer 具备静态 IP 地址。理论上,如果 Peer 的 IP 地址不同时发生变化,WireGuard 是可以实现 IP 漫游的。
现在回到最初的问题:假设两个 Peer 都在 NAT 后面,且这个 NAT 不受我们控制,无法配置 UDP 端口转发,即无法指定公网出口,要想建立连接,不仅要动态发现 Peer 的 IP 地址,还要发现 Peer 的端口。
找了一圈下来,现有的工程erp软件源码工具根本无法实现这个需求,本文将致力于不对 WireGuard 源码做任何改动的情况下实现上述需求。
2. 中心辐射型网络拓扑
你可能会问我为什么不使用 中心辐射型(hub-and-spoke)网络拓扑?中心辐射型网络有一个 *** 网关,这个网关通常都有一个静态 IP 地址,其他所有的客户端都需要连接这个 *** 网关,再由网关将流量转发到其他的客户端。假设 Alice 和 Bob 都位于 NAT 后面,那么 Alice 和 Bob 都要和网关建立隧道,然后 Alice 和 Bob 之间就可以通过 *** 网关转发流量来实现相互通信。
其实这个方法是如今大家都在用的方法,已经没什么可说的了,缺点相当明显:
本文想探讨的是Alice 和 Bob 之间直接建立隧道,中心辐射型(hub-and-spoke)网络拓扑是无法做到的。
3. NAT 穿透
要想在Alice 和 Bob 之间直接建立一个 WireGuard 隧道,就需要它们能够穿过挡在它们面前的 NAT。由于 WireGuard 是通过 UDP 来相互通信的,所以理论上 UDP 打洞(UDP hole punching) 是最佳选择。
UDP 打洞(UDP hole punching)利用了这样一个事实:大多数 NAT 在将入站数据包与现有的连接进行匹配时都很宽松。这样就可以重复使用端口状态来打洞,因为 NAT 路由器不会限制只接收来自原始目的地址(信使服务器)的流量,其他客户端的流量也可以接收。
举个例子,假设Alice 向新主机 Carol 发送一个 UDP 数据包,而 Bob 此时通过某种方法获取到了 Alice 的 NAT 在地址转换过程中使用的出站源 IP:Port,Bob 就可以向这个 IP:Port(2.2.2.2:) 发送 UDP 数据包来和 Alice 建立联系。
其实上面讨论的就是完全圆锥型 NAT(Full cone NAT),即一对一(one-to-one)NAT。它具有以下特点:
大部分的 NAT 都是这种 NAT,对于其他少数不常见的 NAT,这种打洞方法有一定的局限性,无法顺利使用。
4. STUN
回到上面的例子,UDP 打洞过程中有几个问题至关重要:
RFC 关于 STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序)的详细描述中定义了一个协议回答了上面的一部分问题,这是mxplayer+源码+输出一篇内容很长的 RFC,所以我将尽我所能对其进行总结。先提醒一下,STUN 并不能直接解决上面的问题,它只是个扳手,你还得拿他去打造一个称手的工具:
STUN 本身并不是 NAT 穿透问题的解决方案,它只是定义了一个机制,你可以用这个机制来组建实际的解决方案。 — RFC
STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序)STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序)是一种网络协议,它允许位于NAT(或多重NAT)后的客户端找出自己的公网地址,查出自己位于哪种类型的 NAT 之后以及 NAT 为某一个本地端口所绑定的公网端口。这些信息被用来在两个同时处于 NAT 路由器之后的主机之间建立 UDP 通信。该协议由 RFC 定义。
STUN 是一个客户端-服务端协议,在上图的例子中,Alice 是客户端,Carol 是服务端。Alice 向 Carol 发送一个 STUN Binding 请求,当 Binding 请求通过 Alice 的 NAT 时,源 IP:Port 会被重写。当 Carol 收到 Binding 请求后,会将三层和四层的源 IP:Port 复制到 Binding 响应的有效载荷中,并将其发送给 Alice。Binding 响应通过 Alice 的 NAT 转发到内网的 Alice,此时的目标 IP:Port 被重写成了内网地址,但有效载荷保持不变。Alice 收到 Binding 响应后,就会意识到这个 Socket 的公网 IP:Port 是 2.2.2.2:。
然而,STUN 并不是一个完整的解决方案,它只是提供了这么一种机制,让应用程序获取到它的公网 IP:Port,但 STUN 并没有提供具体的cf源码代码大全方法来向相关方向发出信号。如果要重头编写一个具有 NAT 穿透功能的应用,肯定要利用 STUN 来实现。当然,明智的做法是不修改 WireGuard 的源码,最好是借鉴 STUN 的概念来实现。总之,不管如何,都需要一个拥有静态公网地址的主机来充当信使服务器。
5. NAT 穿透示例
早在 年 8 月...
技术干货!DPDK新手入门到网络功能深入理解
DPDK新手入门
一、安装
1. 下载源码
DPDK源文件由几个目录组成。
2. 编译
二、配置
1. 预留大页
2. 加载 UIO 驱动
三、运行 Demo
DPDK在examples文件下预置了一系列示例代码,这里以Helloworld为例进行编译。
编译完成后会在build目录下生成一个可执行文件,通过附加一些EAL参数可以运行起来。
以下参数都是比较常用的
四、核心组件
DPDK整套架构是基于以下四个核心组件设计而成的
1. 环形缓冲区管理(librte_ring)
一个无锁的多生产者,多消费者的FIFO表处理接口,可用于不同核之间或是逻辑核上处理单元之间的通信。
2. 内存池管理(librte_mempool)
主要职责是在内存中分配用来存储对象的pool。 每个pool以名称来唯一标识,并且使用一个ring来存储空闲的对象节点。 它还提供了一些其他的服务,如针对每个处理器核心的缓存或者一个能通过添加padding来使对象均匀分散在所有内存通道的对齐辅助工具。
3. 网络报文缓冲区管理(librte_mbuf)
它提供了创建、释放报文缓存的能力,DPDK应用程序可能使用这些报文缓存来存储数据包。这个缓存通常在程序开始时通过DPDK的mempool库创建。这个库提供了创建和释放mbuf的API,能用来暂存数据包。
4. 定时器管理(librte_timer)
这个模块为DPDK的执行单元提供了异步执行函数的能力,也能够周期性的触发函数。它是通过环境抽象层EAL提供的能力来获取的精准时间。
五、环境抽象层(EAL)
EAL是用于为DPDK程序提供底层驱动能力抽象的,它使DPDK程序不需要关注下层具体的网卡或者操作系统,而只需要利用EAL提供的抽象接口即可,EAL会负责将其转换为对应的API。
六、通用流rte_flow
rte_flow提供了一种通用的方式来配置硬件以匹配特定的Ingress或Egress流量,根据用户的任何配置规则对其进行操作或查询相关计数器。
这种通用的方式细化后就是一系列的流规则,每条流规则由多种匹配模式和动作列表组成。
一个流规则可以具有几个不同的动作(如在将数据重定向到特定队列之前执行计数,封装,解封装等操作),而不是依靠几个规则来实现这些动作,应用程序操作具体的硬件实现细节来顺序执行。
1. 属性rte_flow_attr
a. 组group
流规则可以通过为其分配一个公共的组号来分组,通过jump的流量将执行这一组的操作。较低的值具有较高的优先级。组0具有最高优先级,且只有组0的规则会被默认匹配到。
b. 优先级priority
可以将优先级分配给流规则。像Group一样,较低的值表示较高的优先级,0为最大值。
组和优先级是任意的,取决于应用程序,它们不需要是连续的,也不需要从0开始,但是最大数量因设备而异,并且可能受到现有流规则的影响。
c. 流量方向ingress or egress
流量规则可以应用于入站和/或出站流量(Ingress/Egress)。
2. 模式条目rte_flow_item
模式条目类似于一套正则匹配规则,用来匹配目标数据包,其结构如代码所示。
首先模式条目rte_flow_item_type可以分成两类:
同时每个条目可以最多设置三个相同类型的结构:
a. ANY可以匹配任何协议,还可以一个条目匹配多层协议。
b. ETH
c. IPv4
d. TCP
3. 操作rte_flow_action
操作用于对已经匹配到的数据包进行处理,同时多个操作也可以进行组合以实现一个流水线处理。
首先操作类别可以分成三类:
a. MARK对流量进行标记,会设置PKT_RX_FDIR和PKT_RX_FDIR_ID两个FLAG,具体的值可以通过hash.fdir.hi获得。
b. QUEUE将流量上送到某个队列中
c. DROP将数据包丢弃
d. COUNT对数据包进行计数,如果同一个flow里有多个count操作,则每个都需要指定一个独立的id,shared标记的计数器可以用于统一端口的不同的flow一同进行计数。
e. RAW_DECAP用来对匹配到的数据包进行拆包,一般用于隧道流量的剥离。在action定义的时候需要传入一个data用来指定匹配规则和需要移除的内容。
f. RSS对流量进行负载均衡的操作,他将根据提供的数据包进行哈希操作,并将其移动到对应的队列中。
其中的level属性用来指定使用第几层协议进行哈希:
g. 拆包Decap
h. One\Two Port Hairpin
七、常用API
1. 程序初始化
2. 端口初始化
3. 队列初始化
DPDK-网络协议栈-vpp-ovs-DDoS-虚拟化技术
DPDK技术路线视频教程地址立即学习
一、DPDK网络
1. 网络协议栈项目
2.dpdk组件项目
3.dpdk经典项目
二、DPDK框架
1. 可扩展的矢量数据包处理框架vpp(c/c++)
2.DPDK的虚拟交换机框架OvS
3.golang的网络开发框架nff-go(golang)
4. 轻量级的switch框架snabb(lua)
5. 高效磁盘io读写spdk(c)
三、DPDK源码
1. 内核驱动
2. 内存
3. 协议
4. 虚拟化
5. cpu
6. 安全
四、性能测试
1. 性能指标
2. 测试方法
3. 测试工具DPDK相关学习资料分享:点击领取,备注DPDK
DPDK新手入门原文链接:DPDK上手
Gmssl Openssl 国产化国密算法网络加密隧道
在编译与部署国产化国密算法网络加密隧道时,选择合适的编译环境与源码版本至关重要。推荐下载GmSSL版本2.5.4与Open***源码版本2.5.3.tar.gz。
在编译GmSSL过程中,若遇到PEM_read_bio_EC_PUBKEY返回null的问题,原因可能是该函数仅支持Inter CPU架构。解决方法是在GmSSL-master文件夹中,将libcrypto.so.1.1文件拷贝至/usr/lib/aarch-linux-gnu目录下,这样能确保gmssl命令执行正常。
在编译Open***时,通过添加--with-openssl-engine TYPE=gmssl参数,指定使用GmSSL引擎,并使用--disable-lzo参数,因为若未安装lzo,此参数可避免报错。具体参数详情可参考./configure --help。
国密算法中的SM4、SM2、SM3算法与TLS协议支持的算法,在编译完成的国密版Open***执行文件中得到验证。
生成证书与启动隧道服务的步骤请参考相关指南,以确保网络传输加密安全。
作为开源世界的一员,通过撰写此文章,希望能为国密算法的应用提供一些参考。国密算法与开源世界仍存在接轨的挑战,但每一点进步都值得庆祝。在此,向在国密算法研究领域付出努力的科学工作者与布道者致以敬意,同时也欢迎有兴趣的朋友与我联系探讨。
邮箱:pcboygo@.com
基于 Golang 实现的 Shadowsocks 源码解析
本教程旨在解析基于Golang实现的Shadowsocks源码,帮助大家理解如何通过Golang实现一个隧道代理转发工具。首先,让我们从代理和隧道的概念入手。
代理(Proxy)是一种网络服务,允许客户端通过它与服务器进行非直接连接。代理服务器在客户端与服务器之间充当中转站,可以提供隐私保护或安全防护。隧道(Tunnel)则是一种网络通讯协议,允许在不兼容网络之间传输数据或在不安全网络上创建安全路径。
实验环境要求搭建从本地到远程服务器的隧道代理,实现客户端访问远程内容。基本开发环境需包括目标网络架构。实验目的为搭建隧道代理,使客户端能够访问到指定远程服务器的内容。
Shadowsocks通过TCP隧道代理实现,涉及客户端和服务端关键代码分析。
客户端处理数据流时,监听本地代理地址,接收数据流并根据配置文件获取目的端IP,将此IP写入数据流中供服务端识别。
服务端接收请求,向目的地址发送流量。目的端IP通过特定函数解析,实现数据流的接收与识别。
数据流转发利用io.Copy()函数实现,阻塞式读取源流数据并复制至目标流。此过程可能引入阻塞问题,通过使用协程解决。
解析源码可学习到以下技术点:
1. 目的端IP写入数据流机制。
2. Golang中io.Copy()函数实现数据流转发。
3. 使用协程避免阻塞式函数影响程序运行效率。
4. sync.WaitGroup优化并行任务执行。
希望本文能为你的学习之旅提供指导,欢迎关注公众号获取更多技术分析内容。
Tunnelblick for Mac(OpenVP客户端工具)
Tunnelblick Mac版作为一款实用的网络工具,以其绿色小巧和强大功能受到关注。这款免费开源的图形界面设计,专为OS X和MacOS上的OpenVP~用户打造,提供了简单易用的客户端和服务器连接控制。它集成了所有必需的二进制文件和驱动程序,包括OpenVP~、easy-rsa和tun/tap驱动,无需额外安装,仅需配置文件和加密信息即可开始使用。
通过Tunnelblick,用户需连接到VP~服务器,计算机作为隧道的一端,而服务器则位于另一端。获取VP~服务的详细信息可在相关说明中找到。Tunnelblick遵循GNU通用公共许可证第2版,是完全免费且可按该许可证条款分发的软件。
访问Tunnelblick的GitHub网站,用户可以下载包含当前源代码的.zip文件,选择所需分支后点击“下载ZIP”按钮。在Source Code.markdown的Building Tunnelblick部分有从源代码构建的指导说明。对于VP~服务,首选支持来源通常是您的服务提供商,可能需要付费获取用户名、密码等配置信息。
无论是从服务提供商还是个人搭建的VP~,Tunnelblick文档和OpenVP~资源都是解决问题的关键。遇到问题时,可以参考Tunnelblick讨论组或官方文档,如OpenVP~ FAQ、HOWTO等,搜索讨论组是解决问题的快速途径。
Tunnelblick作为志愿者开发项目,欢迎所有用户参与。无论是测试、报告问题,翻译未完成的语言,还是在讨论组中解答他人疑问,都能为项目贡献力量。请务必阅读相关指引,帮助我们改进软件的使用体验和翻译质量。
.jpg)


2024-12-23 01:52
2024-12-23 01:50
2024-12-23 01:41
2024-12-23 01:14
2024-12-23 00:32
2024-12-22 23:51
2024-12-22 23:48
2024-12-22 23:27