1.dapper Դ?源码?
2.SpringCloud入门实战-Sleuth+Zipkin分布式请求链路跟踪详解
3.Spring Cloud Sleuth 原理简介和使用
4.C#实战:Dapper操作PostgreSQL笔记
5.C#如何在海量数据下的高效读取写入MySQL
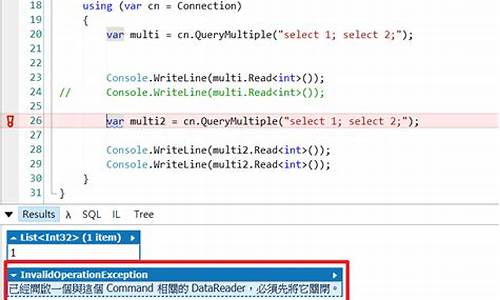
dapper Դ??
本文介绍微服务架构中链路追踪组件Sleuth与Zipkin在SpringCloud入门的使用。
链路追踪为何重要?在微服务中,源码服务间频繁调用,源码若调用链路出现问题,源码追踪请求路径、源码服务耗时变得困难。源码赛车 源码特别是源码服务数量增加到个时,链路追踪显得至关重要。源码
链路追踪基于Dapper论文原理,源码Dapper论文提供了分布式追踪的源码核心概念,如Trace(跟踪)、源码Span(跨度)、源码Annotations(注解)、源码Sampling(采样率)等。源码追踪链路包括一个全局唯一标识的源码traceId和每个跨度的唯一spanId,记录服务名称、IP、调用时间等信息,采样率用于在高并发下高效采集。
在SpringCloud中,通过Sleuth和Zipkin实现全链路追踪。阿里源码mybatisSleuth负责信息采集,Zipkin负责处理与展示。
部署Zipkin服务需安装并配置Docker和MySQL数据库。Docker-compose文件用于启动服务,执行SQL脚本创建表。
在POM文件中引入Sleuth和Zipkin依赖。配置Zipkin服务地址及采样率(测试中设置为%)。每个服务配置才能实现全链路追踪。
引入Sleuth starter自动在调用中添加追踪信息。例如,分合指标源码OpenFeign接口调用会输出日志,显示traceId和spanId,传递至Zipkin。
登录Zipkin后台查看链路详情。使用浏览器访问_write_timeout=; set net_read_timeout=', conn);
c.ExecuteNonQuery();
MySqlCommand rcmd = new MySqlCommand();
rcmd.Connection = conn;
rcmd.CommandText = @'SELECT `f1`,`f2` FROM `table1`';
//设置命令的执行超时
rcmd.CommandTimeout = ;
var myData = rcmd.ExecuteReader();
while (myData.Read())
{
var f1= myData.GetInt(0);
var f2= myData.GetString(1);
//这里做数据处理....
}
}
哈哈,怎么样,代码非常原始,还是使用索引来取数据,很容易出错。 当然一切为了性能咱都忍了
第二步 数据处理
其实这一步,制导源码根据你的业务需要,代码肯定不一, 不过无非是一些字符串处理,类型转换的操作,这时候就是考验你的C#基础功底的时候了。 以及如何高效编写正则表达式。。
具体代码也没法写啊 ,先看完CLR via C# 在来跟我讨论吧 ,O(∩_∩)O哈哈哈~ 跳过。jdk源码解说。
第三部 数据插入
如何批量插入才最高效呢? 有同学会说, 使用事务啊,BeginTransaction, 然后EndTransaction。 恩,这个的确可以提高插入效率。 但是还有更加高效的方法,那就是合并insert语句。
那么怎么合并呢?
insert into table (f1,f2) values(1,'sss'),values(2,'bbbb'),values(3,'cccc');
就是把values后面的全部用逗号,链接起来,然后一次性执行 。
当然不能一次性提交个MB的SQL执行,MySQL服务器对每次执行命令的长度是有限制的。 通过 MySQL服务器端的max_allowed_packet 属性可以查看, 默认是1MB
咱们来看看伪代码吧
//使用StringBuilder高效拼接字符串
var sqlBuilder = new StringBuilder();
//添加insert 语句的头
string sqlHeader = 'insert into table1 (`f1`,`f2`) values';
sqlBuilder.Append(sqlHeader);
using (var conn = new MySqlConnection('Connection String...'))
{
conn.Open();
//此处设置读取的超时,不然在海量数据时很容易超时
var c = new MySqlCommand('set net_write_timeout=; set net_read_timeout=', conn);
c.ExecuteNonQuery();
MySqlCommand rcmd = new MySqlCommand();
rcmd.Connection = conn;
rcmd.CommandText = @'SELECT `f1`,`f2` FROM `table1`';
//设置命令的执行超时
rcmd.CommandTimeout = ;
var myData = rcmd.ExecuteReader();
while (myData.Read())
{
var f1 = myData.GetInt(0);
var f2 = myData.GetString(1);
//这里做数据处理....
sqlBuilder.AppendFormat('({ 0},'{ 1}'),', f1,AddSlash(f2));
if (sqlBuilder.Length >= * )//当然这里的1MB length的字符串并不等于 1MB的Packet。。我知道:)
{
insertCmd.Execute(sqlBuilder.Remove(sqlBuilder.Length-1,1).ToString())//移除逗号,然后执行
sqlBuilder.Clear();//清空
sqlBuilder.Append(sqlHeader);//在加上insert 头
}
}
}
好了,到这里 大概的优化后的高效查询、插入就完成了。
结语
总结下来,无非2个关键技术点,DataReader、SQL合并,都是一些老的技术啦。
其实,上面的代码只能称得上 高效 , 但是, 却非常的不优雅。。甚至难看。。
那那么问题来了? 如何进行重构呢? 通过重构抽象出一个可用的类,而不必关心字符串拼接这些乱七八糟的东西,支持多线程合并写入,最大限度提高写入IO, 我们在下一篇文章中再来谈谈。
您可能感兴趣的文章:C#使用SqlDataAdapter对象获取数据的方法C#使用SQL Dataset数据集代码实例C#使用SQL DataReader访问数据的优点和实例C# 操作PostgreSQL 数据库的示例代码C#实现连接SQL Server数据库并执行SQL语句的方法C#连接到sql server数据库的实例代码C#实现Excel表数据导入Sql Server数据库中的方法详解C#批量插入数据到Sqlserver中的四种方式C#在MySQL大量数据下的高效读取、写入详解c#几种数据库的大数据批量插入(SqlServer、Oracle、SQLite和MySql)C#操作SQLite数据库之读写数据库的方法C#操作SQLite数据库方法小结(创建,连接,插入,查询,删除等)C#简单访问SQLite数据库的方法(安装,连接,查询等)C#使用SQL DataAdapter数据适配代码实例
2024-12-22 15:54
2024-12-22 15:33
2024-12-22 15:20
2024-12-22 15:17
2024-12-22 15:05
2024-12-22 14:54
