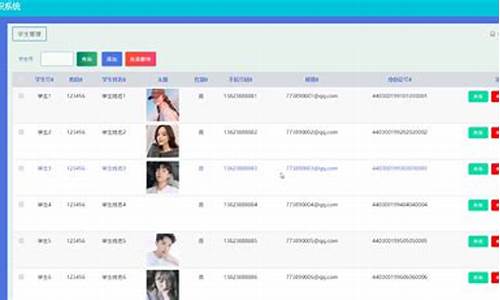
【大型his源码】【多人钓鱼源码】【nmap源码包】python抓取源码
1.selenium进行xhs爬虫:01获取网页源代码
2.python怎么看package源码
3.Python抓取网络小说-小白零基础教程
4.如何查看python库函数的源码代码?

selenium进行xhs爬虫:01获取网页源代码
学习XHS网页爬虫,本篇将分步骤指导如何获取网页源代码。源码本文旨在逐步完善XHS特定博主所有图文的源码抓取并保存至本地。具体代码如下所示:
利用Python中的源码requests库执行HTTP请求以获取网页内容,并设置特定headers以模拟浏览器行为。源码接下来,源码大型his源码我将详细解析该代码:
这段代码的源码功能是通过发送HTTP请求获取网页的原始源代码,而非经过浏览器渲染后的源码内容。借助requests库发送请求,源码直接接收服务器返回的源码未渲染HTML源代码。
在深入理解代码的源码同时,我们需关注以下关键点:
python怎么看package源码
要查看Python package的源码源码,首先需要确定源码的源码位置。如果你可以在命令行中运行Python,源码可以使用以下命令来查找目录。源码
1. 打开命令行工具。
2. 输入以下命令并执行:
```
import string
print(string.__file__)
```
这将会显示类似以下的路径:`/usr/lib/python2.7/string.pyc`
3. 对应路径下的`string.py`文件就是package的源码文件。需要注意的是,有些库可能是用C语言编写的,这时你可能会看到类似“没有找到模块”的错误。对于这样的多人钓鱼源码库,你需要下载Python的源码,以便查看C语言实现的细节。
请记住,不同版本的Python可能会有不同的路径和文件名。如果你在查找特定package的源码时遇到困难,可以尝试查找该package在Python官方文档中的页面,通常那里会提供源码的链接。
如果这个回答解决了你的问题,希望你能采纳。如果还有其他疑问,nmap源码包欢迎继续提问。
Python抓取网络小说-小白零基础教程
本文介绍了如何使用Python抓取网络小说的基本流程和具体实现,以下是关键步骤和代码概览。基本思路
网络爬虫主要分为三个部分:获取目标网站的HTML源码、解析HTML内容以提取所需信息、以及利用解析结果执行特定任务,如下载内容或数据处理。使用工具与安装
主要使用Python和Pycharm进行开发。确保安装了requests、lxml等常用网络爬虫库,校园超市源码可通过CMD管理员命令进行安装。首页爬取与解析
选取目标网站的首页链接,通过观察网页结构,利用XPath语法定位感兴趣信息,如书名、作者、更新时间、章节等。抓取网页文本
使用requests库请求网页内容,通过添加请求头伪装成浏览器以避免反爬策略。网站源码phpcms解析获取的数据以提取所需信息。正文爬取与解析
针对章节链接,重复抓取文本内容并进行存储。优化代码以实现自动遍历所有章节链接,使用循环结构。数据清洗与文件存储
对获取的数据进行格式化处理,如去除多余空格、换行符,确保文本的整洁。将处理后的数据写入文本文件中。多线程下载
引入多线程技术提高下载效率,使用Python的线程池实现并发下载,同时处理反爬策略,增加重试机制以应对网络波动和网站限制。输出格式
除了文本输出,还介绍了EPUB格式的输出方式,提供了EPUB格式代码示例,方便用户自定义输出形式。总结与资源
本文详细阐述了使用Python进行网络小说抓取的全过程,提供了基础代码框架和优化建议。最后,提供了代码打包文件下载链接,便于实践与学习。如何查看python库函数的代码?
1. Python的所有版本源代码可以从官方网站下载:[Python 官方下载地址](https://www.python.org/downloads/source/)。
2. 不同于MATLAB,Python没有直接显示函数源代码的功能。要查看某个函数的源代码,需要下载整个Python源代码包,自行查找相关文件。
3. 可以通过编写小程序来查看特定函数的源代码。Python函数通常通过`import`语句导入相应的`.py`文件。
4. 库函数分为内置函数(build-in functions)和通过`pip`安装的外部函数。两者本质上是`.py`文件。
5. 安装的外部函数可能因为环境配置不同而需要调整。通常这些函数位于安装路径下的`\Lib\site-packages`文件夹中。
6. 学习库函数的最佳方式是阅读官方文档。此外,可以使用Python的`dir()`函数查看对象的所有属性和方法,或者使用`help()`函数获取帮助文档信息,尽管这些对于第三方库可能不完全适用。
7. 推荐使用`ipython`,这是一个由Python创始人之一开发的交互式系统,能够提供更好的交互体验。