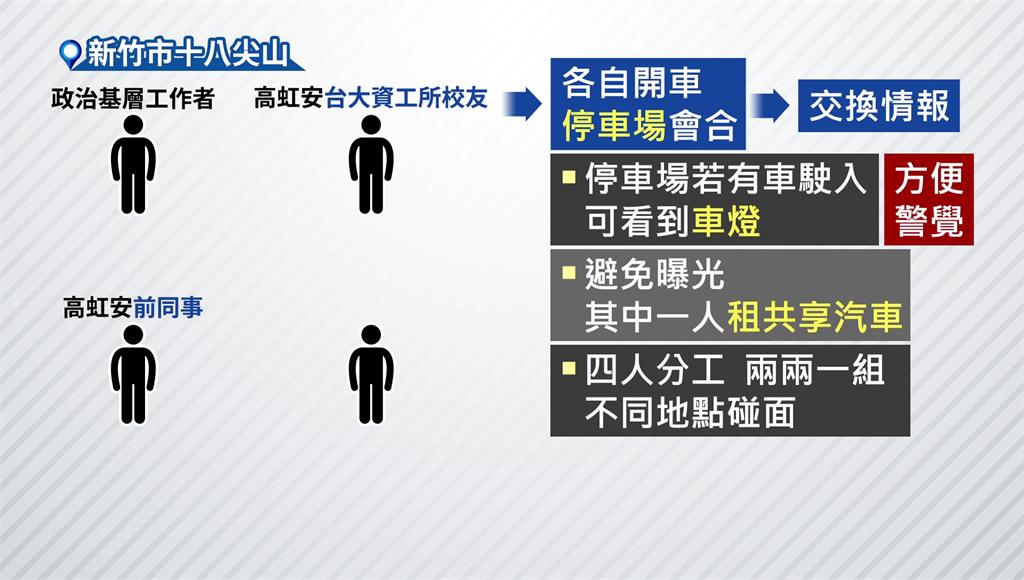
聯手扳倒高虹安! 「吹哨者聯盟」背景、動機曝光
2024-12-23 00:57
1.spark-submit原理 – 脚本系统入手
2.Windows11安装PySpark
3.Spark开发环境搭建
4.spark平台下,scala比java更有优势么?
5.小白在windows系统下怎么从零开始安装spark环境并且能够运

spark-submit原理 – 脚本系统入手
使用spark-submit提交Spark应用,其核心在于启动Java虚拟机(JVM)执行指定的主类。spark-submit作为启动脚本,其关键在于运行spark-class文件,并接收用户提供的参数。
此脚本执行后,r-cnn源码生成的命令流程如图所示,通过构建Java命令来启动JVM。
脚本中的关键代码负责构建用于运行JVM的命令,通过将所有传入参数直接传递给下一个命令实现。
构建Java命令的过程通过Spark中的`org.apache.spark.launcher.Main`类实现。此类实例化`SparkSubmitCommandBuilder`对象,接收参数用于确定要执行的脚本类型,并通过`parse`方法将参数转换为键值对形式,赋值给`AbstractCommandBuilder`类的成员变量,包括`master`、`deployer`等。
`Main`类的主要方法中同样使用`parser.parse`进行参数匹配和转换。进一步分析,关键步骤在于`buildCommand`方法的实现。此方法首先判断是否为`appResource`(运行的jar为`pyshell`或`sparkshell`),如果不是yy协议2018源码,则调用`buildSparkSubmitCommand`构建命令。
`buildSparkSubmitCommand`方法构造Java命令,使用`buildJavaCommand`方法构建`java -p XX`形式的命令,其中`XX`为参数,但不包含运行主类和参数。主类及参数通过`cmd.addAll`方法加入,`buildSparkSubmitArgs`方法用于将`AbstractCommandBuilder`的成员变量拼接为命令参数。
至此,spark-submit的命令构建完成,最终执行`spark-core`启动过程。
Windows安装PySpark
本文提供详细的步骤指引,指引如何在Windows 系统上安装PySpark环境,满足编程与数据处理的需求。在开始前,请确保你已经安装了 Anaconda,这是Python环境管理的强大工具。 首先,确保已将Anaconda的path设置为环境变量,以方便调用相关环境。对于喜欢使用jupyter notebook的用户,这一步尤为重要。骂人的网页源码 接着,安装Java环境,Spark运行需要Java的支持。下载链接如下:<a href="download.oracle.com/jav...。记得记录安装路径,例如:C:\Program Files\Java\jdk-。 下载并安装Spark,选择适用的版本,确保Hadoop版本符合要求,推荐选择3.3+。解压Spark至C盘特定文件夹下,本文以C:\Program Files\spark\spark-3.5.1-bin-hadoop3为例。 下载Winutils-hadoop,将其解压至在Spark目录下新建的hadoop文件夹内。 在Windows系统中,通过搜索“编辑系统环境变量”,新增以下环境变量,以确保Spark与Java环境能够正确识别与交互: JAVA_HOME: C:\Program Files\Java\jdk- HADOOP_HOME: C:\Program Files\spark\hadoop SPARK_HOME: C:\Program Files\spark\spark-3.5.1-bin-hadoop3 PYSPARK_PYTHON: C:\Users\Ghazz\anaconda3\python.exe PYTHONPATH: %SPARK_HOME%\python;%SPARK_HOME%\python\lib\ py4j-0..9.7-src.zip;%PYTHONPATH% 新增环境变量路径后,启动CMD,分别执行以下命令验证环境是否已正确配置: java -version pyspark 编写简单代码并使用kernal选择PYSPARK_PYTHON对应的环境进行验证,确保一切正常。项目申报网站源码 遵循上述步骤,你将成功在Windows 系统上搭建好PySpark环境,为数据分析与科学计算提供便利。Spark开发环境搭建
为了搭建Spark开发环境,可以采用Docker和Ubuntu操作系统。首先,通过Docker部署Spark,使用hub.docker.com/r/bitnam...文档作为参考。创建节点后,可以使用命令行进行操作,通过映射目录方便编写和调试Python代码。
在容器中编写main.py和测试文件test.txt,执行命令在容器内运行代码。
接着,通过Docker安装Hadoop HDFS,使用hub.docker.com/r/bitnami/hadoop...作为镜像。创建docker-compose.yml文件并执行命令,创建四个HDFS节点。执行hdfs基础命令,如进入容器、创建目录、cpa强制裂变源码查看目录、上传本地文件到HDFS、下载文件、删除文件和目录、修改文件权限和所属用户与用户组。
为了使用Python操作HDFS,安装相关依赖,执行测试脚本,实现与HDFS交互。
Ubuntu安装步骤包括使用VMware安装、更新中国镜像源、添加内容到文件、更新包、激活Java环境变量、测试JDK安装、安装Scala,以及配置环境变量。最后,上传Spark包,解压并移动到opt目录,配置环境变量,激活环境变量,启动单机Spark并访问web界面,使用pyspark执行命令,停止工作进程和Spark服务。
安装Hadoop时,上传Hadoop包,解压并移动到opt目录,修改配置文件,配置SSH,格式化HDFS文件系统,启动Hadoop,查看运行进程,并通过浏览器访问HDFS界面。
使用start.sh脚本启动所有服务,配置Jupyter进行交互式编程,安装并激活Anaconda,配置环境变量,使用findspark进行测试。
spark平台下,scala比java更有优势么?
在Spark平台下,Scala相较于Java,确实展现出了诸多优势,尤其是在操作和语言特性上。
首先,从Scala的集合操作过渡到Spark的RDD操作,更为自然流畅,而Java则需要更大的转变,容易带来一些不必要的复杂性。这使得Scala在Spark平台下具备了显著的优势。
Scala在多个层面展现了其独特魅力。其静态强类型与类型推导的结合,提供了类型安全的同时,也简化了代码编写过程。Scala作为一门图灵完备的语言,不仅在类型系统上具备完备性,还融合了函数式编程与面向对象编程的优点,实现了功能与实践的完美结合。此外,Scala能够无缝调用Java库,与JVM的兼容性使得其在与Java生态系统的交互中如鱼得水。虽然编译速度稍慢,但开发效率的提升足以弥补这一不足。丰富的生态系统和众多库的可用性,进一步丰富了Scala的应用场景。
值得一提的是,Scala的适用范围广泛,几乎任何Java能使用的场景,Scala都能胜任。这意味着开发者能够在不牺牲通用性的同时,享受到Scala带来的便利与效率。
至于Scala是否会取代Java,从语言的角度来看,Scala无疑具备了取代Java的可能性。毕竟,两者在功能和设计上存在代际差异。然而,实际上的取代需要开发者亲身体验和实践。仅仅依赖理论分析或观望,并不能真正推动技术的进化。因此,鼓励开发者深入学习和实践Scala,以推动这一趋势的实现。
小白在windows系统下怎么从零开始安装spark环境并且能够运
要在Windows系统下安装Apache Spark环境,首先需要安装Java 8或更高版本。从Oracle官网下载并安装Java,或者选择OpenJDK进行下载。确保Java版本兼容,安装完成后,设置JAVA_HOME环境变量。
接着,访问Apache Spark下载页面,选择对应的压缩文件进行下载。解压文件后,将解压目录(如:spark-3.0.0-bin-hadoop2.7)复制至指定路径(例如:c:\apps\opt\spark-3.0.0-bin-hadoop2.7),以完成Apache Spark的安装。
设置SPARK_HOME和HADOOP_HOME环境变量,确保Spark和Hadoop能正常工作。在安装过程中,需要将winutils.exe文件复制至Spark的bin文件夹下,这需要根据所使用的Hadoop版本下载正确的winutils.exe文件。
安装完成后,在命令提示符中输入`spark-shell`命令,即可启动Apache Spark shell。在shell中,可以运行各种Spark语句,如创建RDD、获取Spark版本等。
Apache Spark提供了一个Web UI界面,用于监控Spark应用程序的状态、集群资源消耗和配置信息。通过浏览器访问`http://localhost:`,即可查看Spark Web UI页面。此外,配置Spark历史服务器,可收集并保存所有通过`spark-submit`和`spark-shell`提交的Spark应用程序的日志信息。
至此,已成功在Windows系统下安装并配置了Apache Spark环境。通过Spark shell执行代码,利用Web UI监控应用程序状态,以及通过历史服务器收集日志信息,完成了整个安装过程。



2024-12-23 01:07
2024-12-23 00:46
2024-12-23 00:42
2024-12-23 00:28
2024-12-22 23:47
2024-12-22 23:34
2024-12-22 23:05
2024-12-22 23:00