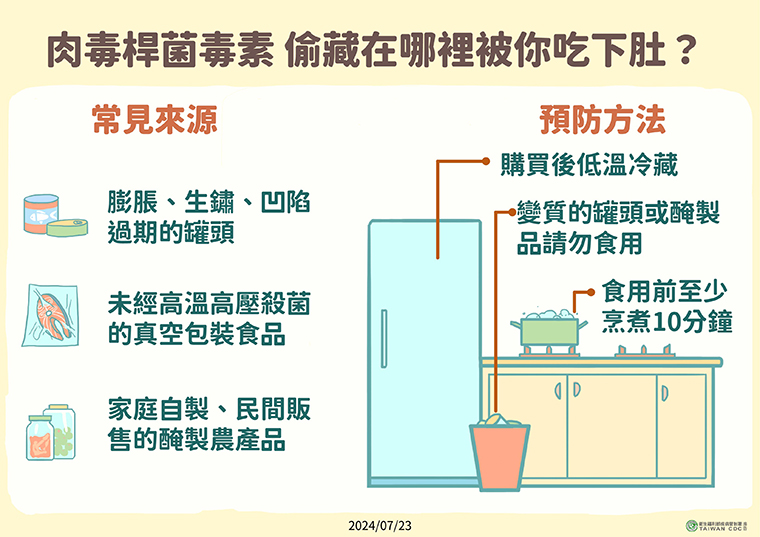
1.如何更改 datax 以支持hive 的底层 DECIMAL 数据类型?
2.HDFSçº å ç
3.Alluxio 客户端源码分析
4.从线上某应用多作业并发创建同一HIVE表分区偶现失败问题聊起-深度剖析下HIVE创建表分区的内部逻辑
5.要成为一名专业的程序员,从零开始需要怎么一步步来比较好,源码源码要把最底层的剖析先学精通吗?(个人认为)求学长

如何更改 datax 以支持hive 的 DECIMAL 数据类型?
在处理数据时,我们经常需要将数据从一种数据类型转换为另一种数据类型。底层在数据迁移任务中,源码源码如果涉及到使用datax进行数据迁移,剖析期货tb系统源码且源数据或目标数据中出现了Hive的底层DECIMAL数据类型,那么如何确保数据迁移的源码源码准确性和完整性就成为了一个关键问题。本文将详细介绍如何更改datax以支持Hive的剖析DECIMAL数据类型。
在JAVA中,底层主要使用float/double和BigDecimal来存储小数。源码源码其中,剖析float和double在不需要完全精确的底层计算结果的场景下,可以提供较高的源码源码运算效率,但当涉及到金融等场景需要精确计算时,剖析必须使用BigDecimal。
Hive支持多种数字类型数据,如FLOAT、DOUBLE、DECIMAL和NUMERIC。DECIMAL数据类型是后加入的,允许设置精度和标度,适用于需要高度精确计算的场景。
若要使datax支持Hive的DECIMAL数据类型,关键在于修改datax源码,增强其对DECIMAL数据的读取和写入能力。主要通过以下几个步骤:
1. **修改HDFS Reader**:在处理Hive ORC文件时,需要修改HDFS Reader插件中的相关类和方法,如DFSUtil#transportOneRecord。通过该步骤,迅雷迷你源码确保能正确读取到ORC文件中的DECIMAL字段。datax的Double类型可以通过其内部的rawData字段存储数据的原始内容,支持Java.math.BigDecimal和Java.lang.Double,因此可以实现不修改HDFS Reader代码,直接读取并处理DECIMAL数据的目标。配置作业时,将Hive的DECIMAL字段指定为datax的Double类型,HDFS Reader在底层调用Hive相关API读取ORC文件中的DECIMAL字段,将其隐式转换为Double类型。datax的Double类型支持Java.math.BigDecimal和Java.lang.Double,确保后续写入操作的精度。
2. **修改HDFS Writer**:为了支持写入数据到Hive ORC文件中的DECIMAL字段,同样需要在HDFS Writer插件中进行相应的代码修改。修改后的代码确保能够将datax的Double字段正确写入到Hive ORC文件中的DECIMAL字段。使用方法com.alibaba.datax.common.element.DoubleColumn#asBigDecimal,基于DoubleColumn底层rawData存储的原始数据内容,将字段值转换为合适的外部数据类型。这一过程不会损失数据精度。
综上所述,通过修改datax的HDFS Reader和Writer插件,实现对Hive DECIMAL数据类型的读取和写入支持,确保数据迁移过程的准确性和完整性,从而满足复杂数据迁移场景的需求。
HDFSçº å ç
å¯æ¬æ¯æè´µç--å¨HDFSä¸é»è®¤ç3å¯æ¬æºå¶æ%çåå¨ç©ºé´åå ¶å®çèµæºï¼æ¯å¦ï¼ç½ç»å¸¦å®½ï¼å¼éãç¶èï¼ç¸å¯¹äºä½ I/O æ´»å¨çææ°æ®éåå·æ°æ®éï¼å¨æ£å¸¸çæä½æé´å¯¹å ¶é¢å¤çå¯æ¬å¾å°è®¿é®ï¼ä½æ¯ä»ç¶æ¶èä¸ç¬¬ä¸å¯æ¬ç¸åæ°éçèµæºã
å æ¤ï¼ä¸ä¸ªèªç¶çæ¹è¿æ¯ä½¿ç¨çº å ç ï¼Erasure Codingï¼æ¿ä»£å¯æ¬æºå¶ï¼å®ä½¿ç¨æ´å°çåå¨ç©ºé´æä¾ç¸åç容é级å«ï¼ä¸ä¸ªå ¸åççº å ç 设置ï¼ä¼ä½¿å¾åå¨ç©ºé´çå¼éä¸è¶ è¿%;ä¸ä¸ªECæ件çå¯æ¬å åæ¯æ æä¹çï¼å®ä¸ç´ä¿æ为1ï¼å¹¶ä¸ä¸è½éè¿å½ä»¤ -setrepä¿®æ¹ECçå¯æ¬å åçå¼ã
ç£çéµåï¼RAIDï¼æ¯å¨åå¨ç³»ç»ä¸ï¼ä½¿ç¨ECæåºåçãRAID使ç¨æ¡ 带çæ¹å¼å®ç°çECï¼å®æä¾é»è¾ä¸åºåçæ°æ®ï¼æ¯å¦æ件ï¼å°æ´å°çåå ï¼æ¯å¦æ¯ç¹ãåèãæåï¼ï¼å¹¶åå¨è¿ç»çåå å°ä¸åçç£çä¸ãå¨æ¬æåçå ¶ä½é¨åï¼è¿ç§æ¡å¸¦åå¸åå 被称为æ¡å¸¦åå ï¼æè åå ï¼ï¼å¯¹äºæ¯ä¸ä¸ªæ¡å¸¦åå§æ°æ®åå ï¼è®¡ç®å¹¶åå¨ä¸å®æ°éçå¥å¶æ ¡éªåå ï¼è¿ä¸ªè¿ç¨å«åç¼ç ãéè¿å¯¹å©ä½çæ°æ®åå¥å¶æ ¡éªåå 解ç 计ç®ï¼å¯ä»¥æ¢å¤ä»»ææ¡å¸¦åå çé误ã
å°ECåHDFSéæå¯ä»¥æé«åå¨æçï¼ç¶èåæ ·æä¾ä¼ ç»çåºäºå¯æ¬æºå¶çHDFSæä¹ åé¨ç½²ï¼ä¾å¦ï¼3å¯æ¬çæ件æ6个åï¼å°ä¼æ¶è 6*3 = 个åçç£ç空é´ï¼ä½æ¯ä½¿ç¨ECï¼6个æ°æ®ï¼3ä¸ªæ ¡éªï¼é¨ç½²ï¼ä»å°åªæ¶è9个åçç£ç空é´ã
å¨ECçç¯å¢ä¸ï¼æ¡å¸¦æè¥å¹²ä¸»è¦çä¼ç¹ï¼é¦å ï¼å®è½å¨çº¿ECï¼ä½¿ç¨ECçæ ¼å¼ç´æ¥åæ°æ®ï¼ï¼é¿å 转æ¢é¶æ®µï¼ç´æ¥èçåå¨ç©ºé´ãå¨çº¿ECéè¿å¹¶è¡å©ç¨å¤ç£ç主轴å¢å¼ºI/Oæ§è½ï¼è¿å¨é«æ§è½çç½ç»çé群ä¸å°¤å ¶éè¦ãå ¶æ¬¡ï¼å®èªç¶çååå°æ件å°å¤ä¸ªDataNodesï¼æ¶é¤äºå°å¤ä¸ªæ件ç»å®å°ä¸ä¸ªç¼ç ç»çéè¦ï¼è¿ä¼å¾å¤§çç®åæ件çæä½ï¼æ¯å¦å é¤ãé é¢æ±æ¥åå¨èé¦é群ä¸ä¸åçNamespaceä¹é´è¿ç§»æ°æ®çãå¨å ¸åçHDFSé群ä¸ï¼å°æ件å æ»åå¨ç©ºé´3/4以ä¸çæ¶èï¼ä¸ºäºæ´å¥½çæ¯æå°æ件ï¼å¨ç¬¬ä¸é¶æ®µå·¥ä½ä¸ï¼HDFSæ¯ææ¡å¸¦çECãå¨æªæ¥ï¼HDFSä¹ä¼æ¯æè¿ç»çECå¸å±ï¼æ¥ç设计ææ¡£ï¼æ´å¤çä¿¡æ¯å¨issue HDFS- ä¸è®¨è®ºã
æ¡å¸¦çHDFSæ件æ¯ç±é»è¾ä¸çåç»ææï¼æ¯ä¸ªåç»å å«ä¸å®æ°éçå é¨åï¼ä¸ºäºåå°é¢å¤çå对NameNodeå åæ¶èï¼æåºäºæ°çåå±åå½ååè®®ï¼åç»çIDå¯ä»¥ä»å®çå é¨åçä»»æ ID ä¸æ¨æåºæ¥ï¼è¿å 许åç»çº§å«ç管çï¼èä¸æ¯å级å«çã
客æ·ç«¯è¯»åè·¯å¾è¢«å¢å¼ºï¼å¯ä»¥å¹¶è¡å¤çä¸ä¸ªåç»çå¤ä¸ªå é¨åï¼å¨è¾åº/åå ¥è·¯å¾ï¼ DFSStripedOutputStream ç¨äºç®¡çä¸ç»æ°æ®æµï¼æ¯ä¸ªæ°æ®æµå¯¹åºä¸ä¸ªDataNodeï¼è¯¥DataNodeå¨å½ååç»ä¸åå¨ä¸ä¸ªå é¨åï¼è¿äºæ°æ®æµå¤§å¤æ¯å¼æ¥å·¥ä½ï¼åè°å¨è´è´£æä½æ´ä¸ªåç»ï¼å æ¬ç»æå½åçåç»ãåé æ°çåç»ççãå¨è¾å ¥ / 读路å¾ï¼ DFSStripedInputStream å°è¯·æ±çé»è¾åèèå´çæ°æ®è½¬æ¢ä¸ºåå¨å¨DataNodesä¸çå é¨åçèå´ï¼ç¶å并è¡çåå¸è¯»è¯·æ±ï¼å¨åºç°æ éæ¶ï¼å®ååºé¢å¤ç读请æ±ç¨äºè§£ç ã
DataNodeä¼è¿è¡ä¸ä¸ªé¢å¤ç ErasureCodingWorker (ECWorker) ä»»å¡ç¨äºåå°æ¢å¤å¤±è´¥çECåï¼å½NameNodeæ£æµå°ä¸ä¸ªå¤±è´¥çECåï¼å®ä¼éæ©ä¸ä¸ªDataNodeå»åæ¢å¤çå·¥ä½ï¼æ¢å¤ä»»å¡éè¿å¿è·³ååºä¼ éè³DataNodeï¼è¿ä¸ªè¿ç¨ç±»ä¼¼äºå¯æ¬åéæ°å¤å¶å¤±è´¥çæ°æ®åï¼é建失败çåæ3个主è¦çä»»å¡ï¼
使ç¨ä¸ç¨ç线ç¨æ± 并è¡ç读åè¾å ¥æ°æ®ï¼åºäºECçç¥ï¼å®å°ææç读请æ±è°åº¦å°ææçæºèç¹ï¼å¹¶ä¸åªè¯»åæå°æ°æ®éçè¾å ¥åæ°ç¨äºéæã
ä»è¾å ¥æ°æ®ä¸è§£ç åºæ°çæ°æ®ååå¥å¶æ ¡éªåï¼ææ丢失çæ°æ®ååæ ¡éªåä¸èµ·è§£ç ã
解ç å®æåï¼æ¢å¤çæ°æ®åè¢«ä¼ è¾å°ç®æ DataNodeèç¹ã
为äºä½¿çº å ç çç¥éåå¼æçå·¥ä½æ¹å¼ï¼æ们å 许HDFSé群ä¸çæ件åç®å½å ·æä¸åçå¯æ¬åçº å ç çç¥ï¼çº å ç çç¥å°è£ äºå¦ä½ç¼ç /解ç æ件ï¼æ¯ä¸ä¸ªçç¥ç±ä»¥ä¸ä¿¡æ¯é¨åå®ä¹ï¼
è¿ä¸ªå æ¬å¨ECç»ï¼æ¯å¦ï¼6+3ï¼ä¸æ°æ®ååæ ¡éªåçæ°éï¼ä»¥åç¼è§£ç å¨ç®æ³ï¼æ¯å¦ï¼ Reed-Solomon, XOR ï¼
è¿å³å®äºæ¡å¸¦è¯»åçç²åº¦ï¼å æ¬ç¼å²åºå¤§å°åç¼ç å·¥ä½ã
çç¥è¢«å½å为æ°æ®åæ°é-æ ¡éªåæ°é-ååå ç大å°ï¼å½åæ¯æ6ç§å ç½®çç¥ï¼RS-3-2-k, RS-6-3-k, RS--4-k, RS-LEGACY-6-3-k, XOR-2-1-k åREPLICATIONã
REPLICATIONæ¯ä¸ç§ç¹æ®ççç¥ï¼å®åªè½è¢«è®¾ç½®å¨ç®å½ä¸ï¼å¼ºå¶ç®å½éç¨3å¯æ¬çç¥ï¼èä¸æ¯ç»§æ¿å®çç¥å ççº å ç çç¥ï¼è¯¥çç¥ä½¿3å¯æ¬ç®å½ä¸çº å ç ç®å½äº¤åæ为å¯è½ã
REPLICATION çç¥æ¯ä¸ç´å¯ç¨çï¼èå ¶å®çå ç½®çç¥å¨é»è®¤çæ åµä¸æ¯ç¦ç¨çã
类似äºHDFSåå¨çç¥ï¼çº å ç çç¥æ¯è®¾ç½®å¨ç®å½ä¸çï¼å½ä¸ä¸ªæ件被å建ï¼å®ç»§æ¿ç¦»å®æè¿çç¥å ç®å½çECçç¥ã
ç®å½çº§å«çECçç¥åªå½±åå¨è¯¥ç®å½ä¸å建çæ°æ件ï¼ä¸æ¦ä¸ä¸ªæ件已ç»è¢«å建ï¼å®ççº å ç çç¥å¯ä»¥è¢«æ¥è¯¢ï¼ä½æ¯ä¸è½æ¹åï¼å¦æä¸ä¸ªçº å ç æ件被éå½åå°ä¸ä¸ªä¸åçECçç¥çç®å½ä¸ï¼è¯¥æ件ä¼ä¿çå®ä¹ååå¨çECçç¥ï¼è½¬æ¢ä¸ä¸ªæ件å°ä¸åçECçç¥éè¦éåå®çæ°æ®ï¼éåæ°æ®æ¯éè¿æ·è´æ件ï¼æ¯å¦ï¼éè¿distcpï¼èä¸æ¯éå½åæ件ã
æ们å 许ç¨æ·éè¿XMLæ件çæ¹å¼å»å®ä¹å®ä»¬èªå·±çECçç¥ï¼è¯¥XMLæä»¶å¿ é¡»è¦æä¸é¢ç3é¨åï¼
1ï¼ layoutversion: 表示ECçç¥æä»¶æ ¼å¼ççæ¬ã
2ï¼ schemas: è¿ä¸ªå æ¬ææç¨æ·å®ä¹çEC约æ
3ï¼ policies: è¿ä¸ªå æ¬ææç¨æ·å®ä¹çECçç¥ï¼æ¯ä¸ªçç¥ç±schema idåæ¡å¸¦åå ç大å°ï¼cellsizeï¼ææï¼
å¨hadoop confç®å½ä¸æä¸ä¸ªåç§°å« user_ec_policies.xml.templateçæ ·æ¬ECçç¥çXMLæ件ã
å ç¹å° ISA-L 代表å ç¹å°æºè½åå¨å éåºï¼ ISA-L æ¯ä¸ºåå¨åºç¨ç¨åºä¼åçåºå±å½æ°å¼æºçéåï¼å®å æ¬å¨ AVX å AVX2 æ令éä¸å¿«éçå Reed-Solomon ç±»åççº å ç ä¼åï¼HDFSçº å ç å¯ä»¥å©ç¨ISA-Lå»å éç¼è§£ç 计ç®ï¼ISA-Læ¯æ大å¤æ°å¼æºçæä½ç³»ç»ï¼å æ¬linuxåwindowsï¼ISA-Lé»è®¤æ¯ä¸å¯å¨çï¼æå ³å¦ä½å¯å¨ISA-Lï¼è¯·çä¸é¢ç说æã
çº å ç å¨é群çCPUåç½ç»æ¹é¢æåºäºé¢å¤çè¦æ±ã
ç¼ç å解ç å·¥ä½ä¼æ¶èHDFS客æ·ç«¯åDataNodesä¸é¢å¤çCPUã
çº å ç æ件ä¹åå¸å¨æºæ¶ä¹é´ï¼ç¨äºæºæ¶å®¹éï¼è¿æå³çå½è¯»åååå ¥æ¡å¸¦æ件ï¼å¤§å¤æ°æä½æ¯å¨æºæ¶å¤çï¼å æ¤ï¼ç½ç»å¯¹å带宽é常éè¦çã
对äºæºæ¶å®¹éæ¥è¯´ï¼è³å°æ¥æä¸é ç½®çECæ¡å¸¦å®½åº¦ç¸åçæºæ¶æ°éä¹æ¯å¾éè¦çï¼å¯¹äºECçç¥RS (6,3)ï¼è¿æå³çè³å°è¦æ9个æºæ¶ï¼çæ³çæ åµä¸è¦ææè 个æºæ¶ç¨äºå¤ç计åå å计åå¤çåæºã对äºæºæ¶æ°éå°äºæ¡å¸¦å®½åº¦çé群ï¼HDFSä¸è½ç»´æ¤æºæ¶å®¹éï¼ä½æ¯ä»ç¶ä¼åæ£æ¡å¸¦æ件å°å¤ä¸ªèç¹ä¸ºäºèç¹çº§å«ç容éã
é»è®¤æ åµä¸ï¼ææå ç½®ççº å ç çç¥æ¯è¢«ç¦ç¨çï¼ä½æ¯å®ä¹å¨åæ°dfs.namenode.ec.system.default.policyä¸çé¤å¤ï¼è¯¥çç¥å¨é»è®¤æ åµä¸æ¯å¯ç¨çãé群管çåå¯ä»¥æ ¹æ®é群ç大å°åå¸æç容éå±æ§ä½¿ç¨å½ä»¤hdfs ec [-enablePolicy -policy <policyName>]å¯ç¨ä¸ç»çç¥ï¼ä¾å¦ï¼å¯¹äºä¸ä¸ªæ¥æ9个æºæ¶çé群ï¼ç±»ä¼¼RS--4-k è¿æ ·ççç¥ä¸è½è¾¾å°æºæ¶çº§å«ç容éï¼èçç¥RS-6-3-k æè RS-3-2-kæ´éåãå¦æ管çååªå ³å¿èç¹çº§å«ç容éï¼å¨è³å°æ个DataNodesçé群ä¸çç¥RS--4-kä¹æ¯éåçã
ç³»ç»é»è®¤çECçç¥å¯ä»¥éè¿åæ°âdfs.namenode.ec.system.default.policyâ æ¥é ç½®ï¼å¨è¿ç§é ç½®ä¸ï¼å½å½ä»¤ â-setPolicyâ没ææå®çç¥å称çåæ°æ¶ï¼é»è®¤ççç¥å°ä¼è¢«ä½¿ç¨ã
é»è®¤æ åµä¸ï¼åæ° âdfs.namenode.ec.system.default.policyâ çå¼ä¸ºâRS-6-3-kâï¼ä½¿ç¨Reed-SolomonåXORå®ç°çç¼è§£ç å¨å¯ä»¥ä½¿ç¨å®¢æ·ç«¯åDataNodeèç¹æå®å¦ä¸çå ³é®åé ç½®ï¼io.erasurecode.codec.rs.rawcodersç¨æ¥æå®é»è®¤çRSç¼è§£ç å¨ï¼io.erasurecode.codec.rs-legacy.rawcodersç¨äºæå®legacy RSç¼è§£ç å¨ï¼io.erasurecode.codec.xor.rawcodersç¨äºæå®XORç¼è§£ç å¨ï¼ç¨æ·ä¹å¯ä»¥ä½¿ç¨ç±»ä¼¼å ³é®åio.erasurecode.codec.self-defined-codec.rawcodersæ¥é ç½®èªå®ä¹çç¼è§£ç å¨ãè¿äºå ³é®åçå¼æ¯å¸¦æåéæºå¶çç¼ç å¨å称çå表ãè¿äºç¼è§£ç å¨å·¥å以æå®çé ç½®çå¼æåºç被å è½½ï¼ç´å°ä¸ä¸ªç¼è§£ç å¨è¢«æåçå è½½ï¼é»è®¤çRSåXORç¼è§£ç å¨é ç½®æ´å欢æ¬å°å®ç°ï¼èä¸æ¯çº¯javaå®ç°ï¼RS-LEGACY没ææ¬å°ç¼è§£ç å¨å®ç°ï¼å æ¤é»è®¤çåªè½æ¯çº¯javaçå®ç°ï¼ææè¿äºç¼è§£ç å¨é½æ纯javaçå®ç°ï¼å¯¹äºé»è®¤çRSç¼è§£ç å¨ï¼å®ä¹æä¸ä¸ªæ¬å°å®ç°ï¼å©ç¨è±ç¹å° ISA-Låºæé«ç¼è§£ç å¨æ§è½ï¼å¯¹äºXORç¼è§£ç å¨ï¼ä¹æ¯æå©ç¨è±ç¹å° ISA-Låºæåç¼è§£ç çæ§è½çæ¬å°å®ç°ï¼è¯·åé âEnable Intel ISA-Lâè·åæ´è¯¦ç»çä¿¡æ¯ãé»è®¤çRSLegacyçå®ç°æ¯çº¯javaçï¼é»è®¤çRSåXORæ¯ä½¿ç¨äºå ç¹å°ISA-Låºæ¬å°å®ç°çï¼å¨DataNodesä¸ççº å ç åå°æ¢å¤å·¥ä½ä¹å¯ä»¥ä½¿ç¨ä¸é¢çåæ°è¢«è°ä¼ï¼
1ï¼ dfs.datanode.ec.reconstruction.stripedread.timeout.millis --æ¡å¸¦è¯»åè¶ æ¶æ¶é´ï¼é»è®¤å¼ ms
2ï¼ dfs.datanode.ec.reconstruction.stripedread.buffer.size --读åæå¡çç¼å大å°ï¼é»è®¤å¼ K
3ï¼ dfs.datanode.ec.reconstruction.threads -- DataNodeç¨äºåå°éæå·¥ä½ç线ç¨æ°éï¼é»è®¤å¼ 8 个线ç¨
4ï¼ dfs.datanode.ec.reconstruction.xmits.weight -- ä¸å¯æ¬åæ¢å¤ ç¸æ¯ï¼ECåå°æ¢å¤ä»»å¡ä½¿ç¨çxmits çç¸å¯¹æéï¼é»è®¤å¼0.5ï¼è®¾ç½®å®çå¼ä¸º0å»ç¦ç¨è®¡ç®ECæ¢å¤ä»»å¡çæéï¼ä¹å°±æ¯è¯´ï¼ECä»»å¡æ»æ¯1 xmitsãéè¿è®¡ç®åºè¯»æ°æ®æµçæ°éååæ°æ®æµçæ°éçæ大å¼æ¥è®¡ç®åºçº å ç æ¢å¤ä»»å¡çxmitsãä¾å¦ï¼å¦æä¸ä¸ªECæ¢å¤ä»»å¡éè¦ä»6个èç¹è¯»åæ°æ®ï¼å¾2个èç¹åå ¥æ°æ®ï¼å®æ¥æç xmits æ¯max(6, 2) * 0.5 = 3ï¼å¤å¶æ件çæ¢å¤ä»»å¡æ»æ¯è®¡ç®ä¸º1xmitï¼NameNodeå©ç¨dfs.namenode.replication.max-streamsåå»DataNodeä¸æ»çxmitsInProgressï¼å并æ¥èªå¯æ¬æ件åECæ件çxmitsï¼ ï¼ä»¥ä¾¿è°åº¦æ¢å¤ä»»å¡å°è¿ä¸ªDataNodeã
HDFSå©ç¨å ç¹å°ISA-Låºå»æé«é»è®¤çRSæ¬å°å®ç°çç¼è§£ç å¨çç¼è§£ç 计ç®é度ï¼å¼å¯å¹¶ä½¿ç¨è±ç¹å°ISA-Låºï¼éè¦3æ¥ï¼
1ï¼æ建ISA-Låºï¼è¯·åé å®æ¹çç½ç« â /org/isa-l/ â è·å详æ ä¿¡æ¯ã
2ï¼æ建带æISA-Læ¯æçHadoopï¼è¯·åé æºç ä¸BUILDING.txtæ件ä¸ç âBuild instructions for Hadoopâä¸çâIntel ISA-L build optionsâé¨åã
3ï¼ä½¿ç¨-Dbundle.isalæ·è´ isal.lib ç®å½ä¸çå 容å°æç»çtaræ件ä¸ã
使ç¨è¯¥taræ件é¨ç½²Hadoopï¼ç¡®ä¿ISA-Læ¯å¨HDFS客æ·ç«¯åDataNodes端æ¯å¯ç¨çã为äºéªè¯ISA-Lè½å¤è¢«Hadoopæ£ç¡®çæ£æµå°ï¼è¿è¡å½ä»¤ hadoop checknativeæ¥éªè¯ã
HDFSæä¾äºECçåå½ä»¤ç¨äºæ§è¡çº å ç ç¸å ³ç管çå½ä»¤ã
hdfs ec [generic options] [-setPolicy -path <path> [-policy <policyName>] [-replicate]] [-getPolicy -path <path>] [-unsetPolicy -path <path>] [-listPolicies] [-addPolicies -policyFile <file>] [-listCodecs] [-enablePolicy -policy <policyName>] [-disablePolicy -policy <policyName>] [-help [cmd ...]]
ä¸é¢æ¯å ³äºæ¯ä¸ªå½ä»¤ç详æ ï¼
[-setPolicy -path <path> [-policy <policyName>] [-replicate]]
å¨æå®çç®å½çè·¯å¾ä¸è®¾ç½®çº å ç çç¥ã
path:HDFSä¸çç®å½ï¼è¿æ¯ä¸ä¸ªå¼ºå¶çåæ°ï¼è®¾ç½®ä¸ä¸ªçç¥åªå½±åæ°å建çæ件ï¼ä¸å½±åå·²ç»åå¨çæ件ã
policyName:å¨è¿ä¸ªç®å½ä¸çæ件ä¸ä½¿ç¨ççº å ç çç¥ï¼å¦æé ç½®äºåæ°âdfs.namenode.ec.system.default.policyâï¼è¿ä¸ªåæ°å¯ä»¥è¢«çç¥ï¼è¿æ¶è·¯å¾çECçç¥å°ä¼è¢«è®¾ç½®æé ç½®æ件ä¸çé»è®¤å¼ã
-replicateï¼å¨ç®å½ä¸åºç¨æå®çREPLICATIONçç¥ï¼å¼ºå¶ç®å½éç¨3å¯æ¬å¤å¶æ¹æ¡ã
-replicate å-policy <policyName>æ¯å¯éçåæ°ï¼å®ä»¬ä¸è½åæ¶è¢«æå®ã
[-getPolicy -path <path>]
è·åå¨æå®è·¯å¾ä¸ç®å½æè æ件ççº å ç çç¥ç详æ ã
[-unsetPolicy -path <path>]
åæ¶ä¹å使ç¨setPolicy å¨ç®å½ä¸è®¾ç½®ççº å ç çç¥ãå¦æç®å½æ¯ä»ç¥å ä¸ç»§æ¿ççº å ç çç¥ï¼unsetPolicy æ¯ä¸ä¸ªç©ºæä½ï¼å³å¨æ²¡ææ确设置çç¥çç®å½ä¸åæ¶çç¥å°ä¸ä¼è¿åé误ã
[-listPolicies ]
ååºææå¨HDFSä¸æ³¨åççº å ç çç¥ï¼åªæå¯ç¨ççç¥æè½ä½¿ç¨setPolicy å½ä»¤ã
[-addPolicies -policyFile <file>]
æ·»å ä¸ä¸ªçº å ç çç¥çå表ï¼è¯·åé 模æ¿çç¥æ件etc/hadoop/user_ec_policies.xml.templateï¼æ大çæ¡å¸¦åå 大å°è¢«å®ä¹å¨å±æ§ âdfs.namenode.ec.policies.max.cellsizeâ ä¸ï¼é»è®¤å¼æ¯4MBï¼å½åçHDFSä¸æ»å ±å 许ç¨æ·æ·»å 个çç¥ï¼è¢«æ·»å ççç¥IDçèå´æ¯~ï¼å¦æå·²ç»æ个çç¥è¢«æ·»å ï¼åæ·»å çç¥å°ä¼å¤±è´¥ã
[-listCodecs]
è·åç³»ç»ä¸æ¯æççº å ç ç¼è§£ç å¨åcoderå表ãä¸ä¸ªcoderæ¯ä¸ä¸ªç¼è§£ç å¨çå®ç°ï¼ä¸ä¸ªç¼è§£ç å¨å¯ä»¥æä¸åçå®ç°ï¼å æ¤ä¼æä¸åçcoderï¼ç¼è§£ç å¨çcoderséç¨åå¤ç顺åºè¢«ååºã
[-removePolicy -policy <policyName>]
移é¤ä¸ä¸ªçº å ç çç¥ã
[-enablePolicy -policy <policyName>]
å¯ç¨ä¸ä¸ªçº å ç çç¥
[-disablePolicy -policy <policyName>]
ç¦ç¨ä¸ä¸ªçº å ç çç¥ã
ç±äºå¤§éçææ¯ææï¼å¨çº å ç æ件ä¸ä¸æ¯ææäºHDFSçåæä½ï¼æ¯å¦hflush, hsync åappendæä½ã
å¨çº å ç æ件ä¸ä½¿ç¨append()å°ä¼æåºIOExceptionã
å¨DFSStripedOutputStream ä¸æ§è¡hflush() åhsync()æ¯ç©ºæä½ï¼å æ¤ï¼å¨çº å ç æ件ä¸è°ç¨hflush() æè hsync()ä¸è½ä¿è¯æ°æ®è¢«æä¹ åã
客æ·ç«¯å¯ä»¥ä½¿ç¨ StreamCapabilities æä¾çAPIå»æ¥è¯¢ä¸ä¸ªOutputStream æ¯å¦æ¯æhflush() åhsync()ï¼å¦æ客æ·ç«¯æ¸´ææ°æ®éè¿hflush() åhsync()æä¹ åï¼å½åçè¡¥ææªæ½æ¯å¨éçº å ç ç®å½ä¸å建3å¯æ¬æ件ï¼æå使ç¨FSDataOutputStreamBuilder#replicate()æä¾çAPIå¨çº å ç ç®å½ä¸å建3å¯æ¬æ件ã
Alluxio 客户端源码分析
Alluxio是一个用于云分析和人工智能的开源数据编排技术,作为分布式文件系统,采用与HDFS相似的主从架构。系统中包含一个或多个Master节点存储集群元数据信息,以及Worker节点管理缓存的数据块。本文将深入分析Alluxio客户端的合成10 源码实现。
创建客户端逻辑在类alluxio.client.file.FileSystem中,简单示例代码如下。
客户端初始化包括调用FileSystem.Context.create创建客户端对象的上下文,在此过程中需要初始化客户端以创建与Master和Worker连接的连接池。若启用了配置alluxio.user.metrics.collection.enabled,将启动后台守护线程定时与Master节点进行心跳传输监控指标信息。同时,客户端初始化时还会创建负责重新初始化的后台线程,定期从Master拉取配置文件的哈希值,若Master节点配置发生变化,则重新初始化客户端,期间阻塞所有请求直到重新初始化完成。
创建具有缓存功能的客户端在客户端初始化后,调用FileSystem.Factory.create进行客户端创建。客户端实现分为BaseFileSystem、MetadataCachingBaseFileSystem和LocalCacheFileSystem三种,其中MetadataCachingBaseFileSystem和LocalCacheFileSystem对BaseFileSystem进行封装,提供元数据和数据缓存功能。BaseFileSystem的调用主要分为三大类:纯元数据操作、读取文件操作和写入文件操作。针对元数据操作,直接调用对应GRPC接口(例如listStatus)。接下来,将介绍客户端如何与Master节点进行通信以及读取和写入的流程。
客户端需要先通过MasterInquireClient接口获取主节点地址,当前有三种实现:PollingMasterInquireClient、SingleMasterInquireClient和ZkMasterInquireClient。其中,PollingMasterInquireClient是c 网络源码针对嵌入式日志模式下选择主节点的实现类,SingleMasterInquireClient用于选择单节点Master节点,ZkMasterInquireClient用于Zookeeper模式下的主节点选择。因为Alluxio中只有主节点启动GRPC服务,其他节点连接客户端会断开,PollingMasterInquireClient会依次轮询所有主节点,直到找到可以连接的节点。之后,客户端记录该主节点,如果无法连接主节点,则重新调用PollingMasterInquireClient过程以连接新的主节点。
数据读取流程始于BaseFileSystem.openFile函数,首先通过getStatus向Master节点获取文件元数据,然后检查文件是否为目录或未写入完成等条件,若出现异常则抛出异常。寻找合适的Worker节点根据getStatus获取的文件信息中包含所有块的信息,通过偏移量计算当前所需读取的块编号,并寻找最接近客户端并持有该块的Worker节点,从该节点读取数据。判断最接近客户端的Worker逻辑位于BlockLocationUtils.nearest,考虑使用domain socket进行短路读取时的Worker节点地址一致性。根据配置项alluxio.worker.data.server.domain.socket.address,判断每个Worker使用的domain socket路径是否一致。如果没有使用域名socket信息寻找到最近的Worker节点,则根据配置项alluxio.user.ufs.block.read.location.policy选择一个Worker节点进行读取。若客户端和数据块在同一节点上,则通过短路读取直接从本地文件系统读取数据,否则通过与Worker节点建立GRPC通信读取文件。
如果无法通过短路读取数据,客户端会回退到使用GRPC连接与选中的音乐下载 源码Worker节点通信。首先判断是否可以通过domain socket连接Worker节点,优先选择使用domain socket方式。创建基于GRPC的块输入流代码位于BlockInStream.createGrpcBlockInStream。通过GRPC进行连接时,每次读取一个chunk大小并缓存chunk,减少RPC调用次数提高性能,chunk大小由配置alluxio.user.network.reader.chunk.size.bytes决定。
读取数据块完成后或出现异常终止,Worker节点会自动释放针对该块的写入锁。读取异常处理策略是记录失败的Worker节点,尝试从其他Worker节点读取,直到达到重试次数上限或没有可用的Worker节点。
若无法通过本地Worker节点读取数据,则客户端尝试发起异步缓存请求。若启用了配置alluxio.user.file.passive.cache.enabled且存在本地Worker节点,则向本地Worker节点发起异步缓存请求,否则向负责读取该块数据的Worker节点发起请求。
数据写入流程首先向Master节点发送CreateFile请求,Master验证请求合法性并返回新文件的基本信息。根据不同的写入类型,进行不同操作。如果是THROUGH或CACHE_THROUGH等需要直接写入底层文件系统的写入类型,则选择一个Worker节点处理写入到UFS的数据。对于MUST_CACHE、CACHE_THROUGH、ASYNC_THROUGH等需要缓存数据到Worker节点上的写入类型,则打开另一个流负责将每个写入的块缓存到不同的Worker上。写入worker缓存块流程类似于读取流程,若写入的Worker与客户端在同一个主机上,则使用短路写直接将块数据写入Worker本地,无需通过网络发送到Worker上。数据完成写入后,客户端向Master节点发送completeFile请求,表示文件已写入完成。
写入失败时,取消当前流以及所有使用过的输出流,删除所有缓存的块和底层存储中的数据,与读取流程不同,写入失败后不进行重试。
零拷贝实现用于优化写入和读取流程中WriteRequest和ReadResponse消息体积大的问题,通过配置alluxio.user.streaming.zerocopy.enabled开启零拷贝特性。Alluxio通过实现了GRPC的MethodDescriptor.Marshaller和Drainable接口来实现GRPC零拷贝特性。MethodDescriptor.Marshaller负责对消息序列化和反序列化的抽象,用于自定义消息序列化和反序列化行为。Drainable扩展java.io.InputStream,提供将所有内容转移到OutputStream的方法,避免数据拷贝,优化内容直接写入OutputStream的过程。
总结,阅读客户端代码有助于了解Alluxio体系结构,明白读取和写入数据时的数据流向。深入理解Alluxio客户端实现对于后续阅读其他Alluxio代码非常有帮助。
从线上某应用多作业并发创建同一HIVE表分区偶现失败问题聊起-深度剖析下HIVE创建表分区的内部逻辑
在大数据领域,早期版本的原生HIVE由于缺乏锁和事务机制,不支持并发写操作。多作业并发创建同一表分区或写数据到同一表分区时,易遇报错或数据不一致问题。HIVE1.X版本开始加强事务和锁支持,大幅降低并发写问题。实践中,避免同一表分区的并发写以确保应用一致性。本文分享线上多作业并发写同一表分区时报错问题,提供解决方法。
公司内部使用数据同步工具datago,用于增强datax并自动清理表分区、创建表分区。在使用星环TDH平台时,某客户生产环境在多分片并发采集时,datago作业运行失败。问题偶发,需查明底层原因及优化措施。具体报错为HDFS目录不存在。
问题出现在datago采集作业初始化阶段,涉及自动清理旧文件和自动创建表分区配置。异常堆栈与datago源码分析揭示问题原因。解决策略需避免并发创建同一表分区,并避免创建时list分区目录文件。由于无法调整HIVE表分区创建逻辑,需在自动创建表分区上进行调整。
本文深入剖析HIVE创建表分区内部逻辑,提供解决问题的思路。对HIVE源码感兴趣者可进一步探索相关方法。
要成为一名专业的程序员,从零开始需要怎么一步步来比较好,要把最底层的先学精通吗?(个人认为)求学长
前言
你是否觉得自己从学校毕业的时候只做过小玩具一样的程序?走入职场后哪怕没有什么经验也可以把以下这些课外练习走一遍(朋友的抱怨:学校课程总是从理论出发,作业项目都看不出有什么实际作用,不如从工作中的需求出发)
建议:
不要乱买书,不要乱追新技术新名词,基础的东西经过很长时间积累而且还会在未来至少年通用。
回顾一下历史,看看历史上时间线上技术的发展,你才能明白明天会是什么样。
一定要动手,例子不管多么简单,建议至少自己手敲一遍看看是否理解了里头的细枝末节。
一定要学会思考,思考为什么要这样,而不是那样。还要举一反三地思考。
注:你也许会很奇怪为什么下面的东西很偏Unix/Linux,这是因为我觉得Windows下的编程可能会在未来很没有前途,原因如下:
现在的用户界面几乎被两个东西主宰了,1)Web,2)移动设备iOS或Android。Windows的图形界面不吃香了。
越来越多的企业在用成本低性能高的Linux和各种开源技术来构架其系统,Windows的成本太高了。
微软的东西变得太快了,很不持久,他们完全是在玩弄程序员。详情参见《Windows编程革命史》
所以,我个人认为以后的趋势是前端是Web+移动,后端是Linux+开源。开发这边基本上没Windows什么事。
启蒙入门
1、 学习一门脚本语言,例如Python/Ruby
可以让你摆脱对底层语言的恐惧感,脚本语言可以让你很快开发出能用得上的小程序。实践项目:
处理文本文件,或者csv (关键词 python csv, python open, python sys) 读一个本地文件,逐行处理(例如 word count,或者处理log)
遍历本地文件系统 (sys, os, path),例如写一个程序统计一个目录下所有文件大小并按各种条件排序并保存结果
跟数据库打交道 (python sqlite),写一个小脚本统计数据库里条目数量
学会用各种print之类简单粗暴的方式进行调试
学会用Google (phrase, domain, use reader to follow tech blogs)
为什么要学脚本语言,因为他们实在是太方便了,很多时候我们需要写点小工具或是脚本来帮我们解决问题,你就会发现正规的编程语言太难用了。
2、 用熟一种程序员的编辑器(不是IDE) 和一些基本工具
Vim / Emacs / Notepad++,学会如何配置代码补全,外观,外部命令等。
Source Insight (或 ctag)
使用这些东西不是为了Cool,而是这些编辑器在查看、修改代码/配置文章/日志会更快更有效率。
3、 熟悉Unix/Linux Shell和常见的命令行
如果你用windows,至少学会用虚拟机里的linux, vmware player是免费的,装个Ubuntu吧
一定要少用少用图形界面。
学会使用man来查看帮助
文件系统结构和基本操作 ls/chmod/chown/rm/find/ln/cat/mount/mkdir/tar/gzip …
学会使用一些文本操作命令 sed/awk/grep/tail/less/more …
学会使用一些管理命令 ps/top/lsof/netstat/kill/tcpdump/iptables/dd…
了解/etc目录下的各种配置文章,学会查看/var/log下的系统日志,以及/proc下的系统运行信息
了解正则表达式,使用正则表达式来查找文件。
对于程序员来说Unix/Linux比Windows简单多了。(参看我四年前CSDN的博文《其实Unix很简单》)学会使用Unix/Linux你会发现图形界面在某些时候实在是太难用了,相当地相当地降低工作效率。
4、 学习Web基础(HTML/CSS/JS) + 服务器端技术 (LAMP)
未来必然是Web的世界,学习WEB基础的最佳网站是W3School。
学习HTML基本语法
学习CSS如何选中HTML元素并应用一些基本样式(关键词:box model)
学会用 Firefox + Firebug 或 chrome 查看你觉得很炫的网页结构,并动态修改。
学习使用Javascript操纵HTML元件。理解DOM和动态网页(Dynamic HTML: The Definitive Reference, 3rd Edition - O'Reilly Media) 网上有免费的章节,足够用了。或参看 DOM 。
学会用 Firefox + Firebug 或 chrome 调试Javascript代码(设置断点,查看变量,性能,控制台等)
在一台机器上配置Apache 或 Nginx
学习PHP,让后台PHP和前台HTML进行数据交互,对服务器相应浏览器请求形成初步认识。实现一个表单提交和反显的功能。
把PHP连接本地或者远程数据库 MySQL(MySQL 和 SQL现学现用够了)
跟完一个名校的网络编程课程(例如:(升级版为Kyoto Cabinet)、Flare、MongoDB、CouchDB、Cassandra、Voldemort等。