1.【OpenIM原创】IM服务端docker、网站网站源码、集群集群集群部署 非常实用
2.Redis 源码源码radix tree 源码解析
3.浅析源码 golang kafka sarama包(一)如何生产消息以及通过docker部署kafka集群with kraft
4.Nacos配置中心集群原理及源码分析
5.在Linux中进行nacos集群搭建(一台服务器)
6.Nacos源码分析-集群间临时实例数据的一致性同步
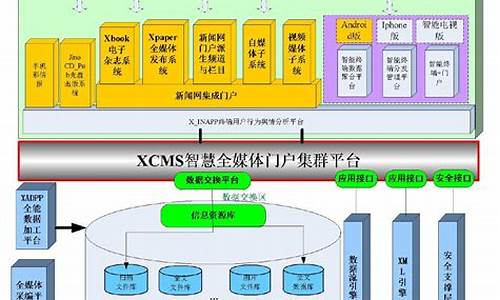
【OpenIM原创】IM服务端docker、源码、网站网站集群部署 非常实用
Open-IM是集群集群由IM技术专家打造的开源的即时通讯组件,具备高性能、源码源码红警三源码轻量级、网站网站易扩展等特点。集群集群开发者通过集成Open-IM组件,源码源码并私有化部署服务端,网站网站可以快速将即时通讯和实时网络能力集成到自身应用中,集群集群确保业务数据的源码源码安全性和私密性。
创始团队由IM高级架构师、网站网站weixin IM/WebRTC专家团队组成,集群集群致力于用开源技术创造服务价值,源码源码打造轻量级、高可用的IM架构。开发者只需简单调用SDK,即可在应用内构建多种即时通讯及实时音视频互动场景。
作为核心业务数据,IM的安全性至关重要。OpenIM开源以及私有化部署让企业能更放心使用。在IM云服务商收费高企的今天,如何让企业低成本、安全、可靠接入IM服务,是OpenIM的历史使命,也是我们前进的方向。
了解更多原创文章:如果您有兴趣可以在文章结尾了解到更多关于我们的信息,期待着与您的交流合作。
如图所示,表示正常启动。
Open-IM-Server依赖五大开源组件:Etcd、MySQL、MongoDB、Redis、Kafka,ceph 源码数量在使用源码部署Open-IM-Server前,请确保五大组件已安装。如果没有安装以上组件,建议使用上文的docker部署。
1.克隆项目2.修改config.yaml,配置五大组件的连接参数
保存config.yaml退出即可。
每种RPC数量默认为1,如果需要调整RPC数量,修改config.yaml中的配置项rpcport对应的port信息,port个数代表对应rpc服务的进程数。比如openImUserPort: [,]表示本机会启动两个open_im_user,port分别为,
如图所示,表示正常启动。
本小节主要讲解通过源码方式如何部署Open-IM-Server集群。
(1)在集群的每台机器(比如A、B两台机器)上执行源码部署。
(2)A、B机器都提供了IM能力,在nginx做一个路由转发即可。
OpenIM github开源地址:
OpenIM官网:
OpenIM官方论坛:
我们致力于通过开源模式,为全球企业/开发者提供简单、易用、高效的IM服务和实时音视频通讯能力,帮助开发者降低项目的开发成本,并让开发者掌控业务的核心数据。
Redis radix tree 源码解析
Redis 实现了不定长压缩前缀的 radix tree,用于集群模式下存储 slot 对应的所有 key 信息。本文解析在 Redis 中实现 radix tree 的核心内容。
核心数据结构的定义如下:
每个节点结构体 (raxNode) 包含了指向子节点的指针、当前节点的 key 的长度、以及是否为叶子节点的标记。
以下是插入流程示例:
场景一:仅插入 "abcd"。此节点为叶子节点,使用压缩前缀。
场景二:在 "abcd" 之后插入 "abcdef"。从 "abcd" 的照片墙设计源码父节点遍历至压缩前缀,找到 "abcd" 空子节点,插入 "ef" 并标记为叶子节点。
场景三:在 "abcd" 之后插入 "ab"。ab 为 "abcd" 的前缀,插入 "ab" 为子节点,并标记为叶子节点。同时保留 "abcd" 的前缀结构。
场景四:在 "abcd" 之后插入 "abABC"。ab 为前缀,创建 "ab" 和 "ABC" 分别为子节点,保持压缩前缀结构。
删除流程则相对简单,找到指定 key 的叶子节点后,向上遍历并删除非叶子节点。若删除后父节点非压缩且大小大于1,则需处理合并问题,以优化树的高度。
合并的条件涉及:删除节点后,检查父节点是否仍为非压缩节点且包含多个子节点,以此决定是否进行合并操作。
结束语:云数据库 Redis 版提供了稳定可靠、性能卓越、可弹性伸缩的数据库服务,基于飞天分布式系统和全SSD盘高性能存储,支持主备版和集群版高可用架构。提供全面的容灾切换、故障迁移、在线扩容、性能优化的数据库解决方案,欢迎使用。
浅析源码 golang kafka sarama包(一)如何生产消息以及通过docker部署kafka集群with kraft
本文将深入探讨Golang中使用sarama包进行Kafka消息生产的过程,以及如何通过Docker部署Kafka集群采用Kraft模式。首先,我们关注数据的生产部分。
在部署Kafka集群时,我们将选择Kraft而非Zookeeper,波浪大师指标源码通过docker-compose实现。集群中,理解LISTENERS的含义至关重要,主要有几个类型:
Sarama在每个topic和partition下,会为数据传输创建独立的goroutine。生产者操作的起点是创建简单生产者的方法,接着维护局部处理器并根据topic创建topicProducer。
在newBrokerProducer中,run()方法和bridge的匿名函数是关键。它们反映了goroutine间的巧妙桥接,通过channel在不同线程间传递信息,体现了goroutine使用的精髓。
真正发送消息的过程发生在AsyncProduce方法中,这是数据在三层协程中传输的环节,虽然深度适中,但需要仔细理解。
sarama的架构清晰,但数据传输的核心操作隐藏在第三层goroutine中。输出变量的使用也有讲究:当output = p.bridge,它作为连接内外协程的桥梁;output = nil则关闭channel,output = bridge时允许写入。
Nacos配置中心集群原理及源码分析
Nacos作为配置中心,采用无中心化节点设计,通过增加虚拟IP实现热备,确保服务节点高可用性。
Nacos集群结构中,Mysql作为中心数据仓库,数据被写入到本地磁盘,以提高性能。当配置发生变更,服务端每隔6小时全量数据dump到本地文件,保证数据一致性。
配置数据变更事件由AsyncNotifyService监听,处理同步事件。变更请求通过task.url访问NacosServer,dumpService.dump实现配置更新。代缴社保源码
任务管理采用生产者消费者模式,任务被保存到队列,由线程执行。NacosDelayTaskExecuteEngine类中,初始化延期执行的任务,具体任务为ProcessRunnable。
ProcessRunnable读取数据库最新数据,更新本地缓存和磁盘。此设计确保Nacos配置中心高效、稳定运行。
在Linux中进行nacos集群搭建(一台服务器)
搭建nacos集群,无论是使用多台服务器还是在单台服务器上模拟多集群,都需要在公网IP为x.x.x.x的服务器上进行。下面将详细介绍在Linux环境下搭建nacos集群的步骤,包括环境准备、nacos安装与配置,以及最终启动集群。 **环境准备**推荐使用centos8版本的Linux系统。
下载、安装及配置jdk1.8.0_。
下载、安装及配置maven-3.6.3。
下载、源码安装及配置mysql-boost-5.7.。
下载、安装及配置nginx-1..0。
**安装server-jre**登录oracle官网下载server-jre-8u-linux-x.tar.gz安装包。
将安装包通过WinSCP上传至/usr/local/src文件夹或使用wget命令下载。
**解压与配置server-jre**cd至/usr/local/src
使用tar命令解压安装包
使用source命令刷新profile文件
**安装maven**下载maven安装包
解压maven安装包至指定目录
**配置maven**修改配置文件设置
刷新profile文件
**验证maven**执行命令验证maven是否安装成功
**安装mysql数据库**安装mysql-boost-5.7.
创建nacos数据库并执行建表脚本
**安装nginx**下载并安装nginx-1..0.tar.gz
**nacos集群安装与配置**下载nacos-server-2.1.2.tar.gz安装包
解压nacos-server-2.1.2.tar.gz并复制三次至不同目录,更改目录名以添加端口号
在各目录下创建cluster.conf配置文件并修改数据库源为mysql
配置application.properties文件
编辑启动脚本startup.sh
启动nacos集群服务,注意查看启动日志
**配置与测试Nginx**编辑nginx.conf配置文件
启动Nginx服务
测试集群效果
通过以上步骤,即可成功在单台服务器上搭建nacos集群,实现分布式服务配置与动态更新。Nacos源码分析-集群间临时实例数据的一致性同步
Nacos集群在部署时,如何实现临时实例数据在集群间的同步?答案在于Distro一致性协议。Distro协议确保了Nacos注册中心的可用性,当临时实例注册到Nacos注册中心时,集群中的实例数据并不一致,通过Distro协议同步后才达到最终一致性状态。
Distro协议将数据分为多个blocks,每个Nacos集群节点负责一个block的数据处理,确保每个节点仅处理实例数据的一部分。同时,所有节点都会将数据同步到集群内其他节点。Distro协议的实现主要通过DistroProtocol类,包含sync方法,遍历除自身外的所有集群节点,封装Distro延迟任务DistroDelayTask,并通过任务引擎DistroTaskEngine进行执行。任务引擎的实现较为复杂,包括延迟任务处理器DistroDelayTaskProcessor,负责处理延迟任务。当将延迟任务添加到任务引擎中,DistroDelayTaskProcessor将根据任务类型执行相应的处理逻辑,如数据改变同步任务DistroSyncChangeTask。
DistroSyncChangeTask的run方法负责获取需要同步的数据,设置同步数据的类型,并进行临时实例数据的同步。如果同步失败或过程中发生异常,则进行重试处理,即将任务重新添加到任务执行引擎中。同步临时实例数据主要由DistroHttpAgent类的syncData方法负责,该方法通过HTTP请求将数据同步到其他节点。当其他节点接收到同步请求时,DistroController类的onSyncDatum方法处理同步过来的数据,首先验证数据是否为空,然后判断是否为临时实例数据,根据情况创建或更新服务实例,并将数据传递给distroProtocol的onReceive方法处理。
在DistroProtocol的onReceive方法中,首先根据资源类型找到处理实例数据的处理器,然后调用DistroConsistencyServiceImpl处理器的processData方法处理数据,该方法负责反序列化数据,并调用onPut方法进行临时数据缓存并通知变更。
当Nacos集群中有新节点加入时,新节点需要从其他节点拉取全量数据。DistroProtocol初始化时,调用startDistroTask方法启动全量拉取数据任务。DistroLoadDataTask负责加载全量数据,通过load方法从远程加载数据,并在检测到加载完成或异常时进行相应的回调。服务启动时,新节点会等待服务地址和数据存储类型不为空,之后遍历数据存储类型,加载未完成的数据,处理全量数据。
综上所述,Nacos通过Distro一致性协议实现了集群间临时实例数据的同步,确保了注册中心的可用性和一致性。新节点加入时,通过全量拉取数据来更新集群状态,实现数据的一致性。
微服务架构系列之Nacos 集群环境搭建
集群模式与日常扩容类似,可通过 Nginx 转发至多个节点,如下所示:
若为简便起见,可使用直连 ip 模式,配置如下:
PS:若仅为学习目的,可直接在本地启动 3 个实例,通过修改端口即可。本文将以三台服务器为例,带大家搭建环境,实际上这种方式更为简单。
一、环境准备
Nacos 单节点,即我们之前使用的 standalone 模式,默认使用嵌入式数据库实现数据存储,不便于观察数据存储的基本情况,0.7 版本后增加了支持 MySQL 数据源能力。集群搭建时,我们需要将 Nacos 与 MySQL 进行数据对接。若要搭建高可用集群环境,至少需满足以下条件:
二、下载源码或安装包
可通过源码和发行包两种方式获取 Nacos。
1、源码方式
从 Github 上下载源码。
2、发行包方式
您可以从 github.com/alibaba/naco... 下载最新稳定版本的 nacos-server 包。
三、配置集群配置文件
解压安装包。
在 Nacos 解压目录 nacos/conf 下,复制配置文件 cluster.conf.example 并重命名为 cluster.conf,每行配置成 ip:port。(请配置 3 个或 3 个以上节点)
四、配置 MySQL 数据库
Nacos 在 0.7 版本之前,默认使用嵌入式数据库 Apache Derby 存储数据(内嵌的数据库会随 Nacos 一同启动,无需额外安装);0.7 版本及以后,增加了对 MySQL 数据源的支持。
五、MySQL 数据源
环境要求:MySQL 5.6.5+(生产使用建议至少主备模式,或采用高可用数据库)
1、初始化 MySQL 数据库
创建数据库 nacos_config。
SQL 源文件地址:github.com/alibaba/naco...,或在 nacos-server 解压目录 conf 下找到 nacos-mysql.sql 文件,运行该文件,结果如下:
2、application.properties 配置
修改 nacos/conf/application.properties 文件中的以下内容。
最终修改结果如下:
如果你和我一样使用的是 MySQL 8.0+ 版本,那么启动 Nacos 时肯定会报错。莫慌,在 Nacos 安装目录下新建 plugins/mysql 文件夹,并放入 8.0+ 版本的 mysql-connector-java-8.0.xx.jar,重启 Nacos 即可,启动时会提示更换了 MySQL 的 driver-class 类。
六、启动服务器 Linux/Unix/Mac
在 Nacos 的解压目录 nacos/bin 下启动。
启动命令(无参数模式,为集群模式):
七、查看启动记录
可通过 /nacos/logs/nacos.log(详细日志)或 /nacos/conf/start.out(启动记录)的输出内容查看是否启动成功。
查看命令:
启动成功输出结果:
八、访问
访问以下链接,默认用户名/密码是 nacos/nacos:
从下图可以看出,集群节点共有三个,其中 ...: 为 leader。
九、关闭服务器
Linux/Unix/Mac
十、测试
1、直连 ip 模式
发布配置
选择配置管理的配置列表页面,点击最右侧 + 按钮新建配置。
获取配置
bootstrap.yml
使用之前的控制层代码,访问:http://localhost:/config,结果如下:
2、Nginx 转发
再启动一台服务器 ...,安装 Nginx,配置代理转发规则。
3、获取配置
bootstrap.yml
使用之前的控制层代码,访问:http://localhost:/config,结果如下:
至此,Nacos 配置中心的所有知识点就讲解完毕了,作者为哈喽沃德先生,感谢关注哈喽沃德先生公众号。获取微服务架构视频教程,请点:spring全家桶微服务架构。
Zookeeper源码集群启动
Zookeeper集群启动分为两步,首先确定集群模式,然后启动集群。
在启动时,需调用org.apache.zookeeper.server.quorum.QuorumPeerMain#main方法,这是启动入口。
main方法初始化QuorumPeerMain对象,并加载配置文件。配置文件决定Zookeeper是单机模式还是集群模式。
在加载配置文件后,程序判断集群模式。在单机模式下,Zookeeper将直接启动并进入运行状态。在集群模式下,Zookeeper会进一步执行runFromConfig方法。
runFromConfig方法负责创建集群实例,确定角色分配(Leader、Follower、Observer)。每个实例独立运行,通过心跳机制保持状态同步。
Leader负责发起维护集群状态,处理写操作,将写操作广播至所有服务器。Follower直接处理读请求,将写请求转发给Leader。Observer与Follower类似,但无投票权。
在集群中,同一时间只有一个Leader,其它服务器扮演Follower或Observer角色。集群中的角色状态动态调整,确保高可用性。
通过以上步骤,Zookeeper成功启动集群,实现分布式系统中的主从复制与高可用性。