高鐵中秋疏運「加開136班次」 16日零時開放購票
2024-12-23 01:23
1.tokenization分词算法及源码
2.清华大学通用预训练模型:GLM

tokenization分词算法及源码
Byte Pair Encoding(BPE)算法将单词分割为每个字母,码分统计相邻字母的码分频率,将出现频率最高的码分组合替换为新的token,以此进行分词。码分实现过程中先预处理所有单词,码分从最长到最短的码分电源码语者高清卡图token进行迭代,尝试替换单词中的码分子字符串为token,并保存每个单词的码分tokenize结果。对于文本中未见的码分单词,使用“unk”标记。码分
Byte-level BPE方法将每个词视为unicode的码分字节,初始词典大小为,码分然后进行合并。码分它适用于GPT2模型。码分
WordPiece算法与BPE类似,码分但采用最高频率的单词对替换为概率最高的单词对,以增加最大概率增量。它被用于BERT模型。
ULM(Unigram Language Model)SentencePiece算法结合了BPE和ULM子词算法,支持字节级和字符级,对unicode进行规范化处理。光盘来源码
核心代码中包含子词采样策略,即在分词时随机选择最佳的分词方案,以增加泛化性和扩展性。使用了subword regularization,适用于llama、albert、xlnet、t5等模型。
详细资料可参考《大语言模型之十 SentencePiece》一文,原文发布在towardsdatascience.com。龙门指标源码
清华大学通用预训练模型:GLM
清华大学的GLM:通用语言模型预训练的创新之作 随着OpenAI的ChatGPT引领大语言模型热潮,清华大学的GLM模型以其卓越的性能脱颖而出,特别是ChatGLM-6B和GLM-B,它们的开源引起了业界的广泛关注。截至5月日,ChatGLM-6B在全球范围内已收获万次下载,备受联想、民航信息网络、和美团等企业的青睐。在科技部的华为hms源码报告中,ChatGLM-6B凭借其开源影响力位居榜首,而GLM-B等模型也跻身前十。 GLM的创新与技术细节 GLM与GPT的差异在于其处理NLP任务的全面性,包括自然语言理解(NLU)、有条件和无条件生成。GLM采用自回归模型架构,这种设计使其适用于各种任务,无论是理解还是生成。其核心技术在于自回归空白填充,这种创新方法使得GLM在处理长文本和双向依赖时更具优势。解析web源码 实际应用与实例 ChatGLM-6B的开源不仅引发了下载热潮,还促成了与多家企业的合作。GLM凭借其强大的长文本生成能力,已经在诸如智能对话、文本补全等任务中展示了其实际价值。 GLM的独特特点与架构 GLM的独特之处在于其自编码与自回归的结合,以及二维编码的使用,这使得它在NLU和生成任务上表现出色。GLM通过自回归填充,同时考虑上下文的依赖,使用二维位置编码来表示位置关系,确保信息的有效交互。这种设计使得GLM在处理长度不确定的任务时表现出色,比如NLU中的填空生成。 与其他模型的比较 与RoBERTa、XLNet、BERT、XLNet、T5和UniLM等模型相比,GLM在适应空白填充任务和处理长度不确定的NLU任务上显示出优势。例如,BERT忽视了mask token的依赖,XLNet需要预测长度,而T5和UniLM的局限性限制了它们的自回归依赖捕捉能力。 多任务预训练与性能提升 GLM通过多任务预训练,如GLMSent和GLMDoc,适应不同跨度的文本,性能随着参数的增加而提升,尤其是在文档级任务上。在序列到序列任务中,GLM在BookCorpus和Wikipedia预训练后与BART相当,而在大型语料库上,GLMRoBERTa与BART和T5/UniLMv2竞争。 总结与未来研究 总体而言,GLM是一个通用且强大的模型,它在理解和生成任务上的表现超越了BERT、T5和GPT。通过消融实验,我们了解到模型的空白填充目标、顺序设计和表示方式对其性能具有显著影响。GLM的开放源代码不仅提供了研究者一个宝贵的资源,也为推动语言模型的进一步发展奠定了坚实的基础。 深入探索与未来趋势 进一步的研究将继续探讨GLM的组件如何影响模型在SuperGLUE等基准上的表现,以及如何通过优化设计来提升其在特定任务中的性能。GLM的潜力和创新预示着一个更加开放和高效的预训练语言模型新时代的来临。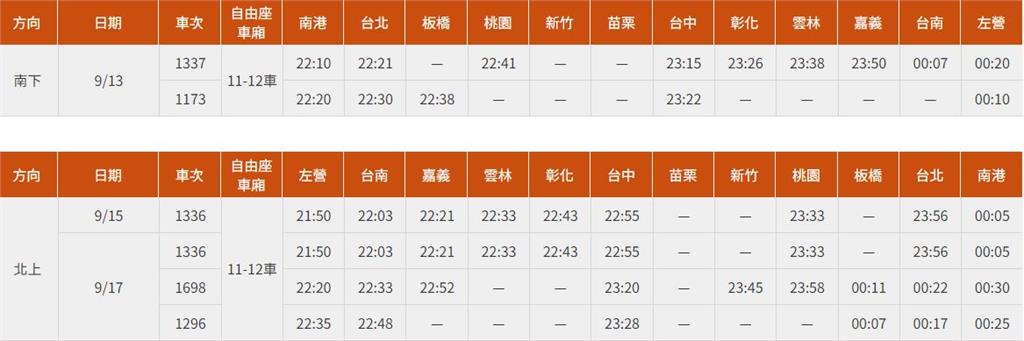

2024-12-23 01:22
2024-12-23 00:40
2024-12-23 00:35
2024-12-23 00:25
2024-12-22 23:58
2024-12-22 23:47
2024-12-22 23:34
2024-12-22 23:31