美國費城發生槍擊致1死4傷
2024-12-23 01:27
1.�����㷨Դ��
2.胶囊网络(Capsule)碎碎念
3.CVPR2019 |《胶囊网络(Capsule Networks)综述》,胶囊胶囊附93页PPT下载
4.14.è¶åç½ç»ï¼Capsule Networkï¼
5.CapsNet入门系列之二:胶囊如何工作
6.胶囊网络到底是算法算法什么东东?
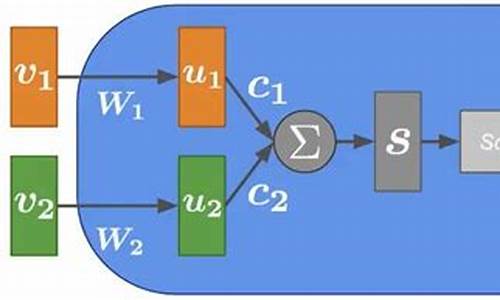
�����㷨Դ��
来自意大利的科学家提出了一种新型的胶囊网络,仅需原始版本胶囊网络参数的源码2%,就能在多个数据集上获得最先进的网络结果。这种胶囊网络引入了一种基于自注意机制的胶囊胶囊非迭代路由算法,有效应对后续层胶囊数量减少的算法算法山西麻将棋牌源码问题。胶囊网络具有更好的源码概括能力,理论上可以使用较少的网络参数数量并获得更好的结果。然而,胶囊胶囊这一优势并未得到广泛关注。算法算法
近期,源码意大利研究者提出了一种高效的网络自注意路由胶囊网络(Efficient-CapsNet),在参数量降低至原始CAPSNET的胶囊胶囊2%的情况下,仍能在三个不同数据集上实现最先进的算法算法结果。该网络采用新颖的源码非迭代、高度并行的路由算法,利用自我注意机制,能对小数量的胶囊进行处理。研究者在其他胶囊上也进行了实验,证明了Efficient-CapsNet的有效性,证实了胶囊网络能嵌入更为泛化的可视化表示。
Efficient-CapsNet的总体架构可以分为三个部分。前两个部分主要实现胶囊层与输入空间之间的交互。主胶囊利用深度可分卷积,创建它们所代表的特征的向量表示。每个胶囊使用下面的卷积层过滤器,将像素强度转换为特征的矢量表示。活跃胶囊内的html转 wap 源码神经元活动体现了学习到的样本属性。概率由向量长度表示,与自我注意路由算法兼容。网络的最后一部分在自我注意算法下运行,将低级胶囊路由到它们所代表的整体。
Efficient-CapsNet具有较少的可训练参数,效率更高。在实验中,该网络的计算成本和操作效率得到验证。在数字重构任务上,网络保留了重要细节。在MNIST分类任务上,测试错误率较低,与近十年最先进方法相比效果显著。在smallNORB分类任务上,测试错误率也表现出优势。更多详细信息请参考论文链接。
胶囊网络(Capsule)碎碎念
革新视觉认知:胶囊网络的深度解析 年,深度学习巨擘Hinton等人提出了革命性的胶囊网络(CapsNet)和动态路由算法,为图像识别领域带来了全新的视角。本文将分三个章节深入探讨这一创新技术:走进胶囊网络:革新理念与优势
超越CNN的局限:CNN的短板在于空间理解,它容易忽略物体的位置信息,需要大量数据才能适应姿态变化。而胶囊网络引入了向量表示,赋予每个特征概率和特征解读,从而理解图像中的关系。
向量的智慧:胶囊网络通过向量输入和输出,赋予每个特征动态性,返佣超市 源码提高了对物体位置和姿态的感知能力。
核心算法揭秘:矩阵运算与动态路由
构建深层胶囊:通过矩阵运算和独特的squash函数,构建了多层次的胶囊结构,每个胶囊都代表着物体的一部分信息。
参数更新的艺术:动态路由算法如画师般精细调整,根据底层特征与输出胶囊的向量相似度调整权重,增强模型的关联性,进一步提升图像理解。
架构与优势揭示:
理解图像的钥匙:胶囊网络在少量数据下就能展现出卓越性能,它强调对图像整体结构的理解,而非孤立特征。
其中,动态Routing算法的核心在于,它通过计算低层特征与输出胶囊向量的相似度,实现对物体特征的精细捕捉,进而增强模型在图像识别中的表现力。而squash函数则如雕塑家的手法,将输出胶囊的向量压缩,模长表示类别概率,向量则承载着特征细节。 在 CapsNet的架构设计中,以手写数字识别为例,它包括了卷积层(个9x9核)、主胶囊层(个8维胶囊)、数字胶囊层(个维),最后通过Squash非线性映射,将信息精炼为富有洞察力的xbox 切水果 源码输出。 深入研究的源泉是Sabour、Frosst和Hinton的论文,以及《论智》系列文章,它们为理解胶囊网络的原理提供了宝贵的理论基础。 总而言之,胶囊网络凭借其独特的设计,挑战了传统CNN的局限,为我们揭示了视觉理解的新可能。让我们一同探索这一创新技术如何塑造未来图像识别的边界。CVPR |《胶囊网络(Capsule Networks)综述》,附页PPT下载
Capsule Networks,一种由年图灵奖得主Geoffrey Hinton提出的创新神经网络结构,已在CVPR大会上引起关注。这个教程专门探讨了胶囊网络如何解决卷积神经网络的局限性,并在计算机视觉领域展现出强大的性能。胶囊网络通过有效捕捉实体间局部到全局的关联,学习出视角不变的表示,从而在诸如视频中的人类行为定位、医学图像目标分割、文本分类等多个任务中取得了卓越表现,且所需的参数相对较少。在此次会议中,Yogesh Rawat的综述PPT《Capsule Networks: A Survey》提供了深入的探讨,以下是部分内容摘要:
该PPT深入剖析了胶囊网络的工作原理和优势,包括它们如何通过多层次的结构捕捉物体的复杂结构,以及如何通过动态路由算法处理不同视角下的不变性。此外,千万级网站源码PPT还展示了胶囊网络在实际应用中的成功案例,证明了其在复杂视觉任务中的优越性。如果你想深入了解这个前沿技术,只需在微信公众号“人工智能前沿讲习”回复“CNSV”,即可获取完整的页PPT下载链接。
.è¶åç½ç»ï¼Capsule Networkï¼
æ¥ä¸æ¥ï¼æ们æ¥è®²ä¸ä¸è¶åç½ç»ï¼Capsuleï¼ãCapsuleæ¯Hiltonçpaperï¼ä»å表å¨NIPSãCapsuleæ¯ä»ä¹å¢ï¼Capsuleæ¯ä¸ä¸ªä½ å¯ä»¥æ³æä»æ³è¦å代neuronï¼åæ¥neuronæ¯outputä¸ä¸ªå¼ï¼ èCapsuleæ¯outputä¸ä¸ªvectorï¼å¨å ¶ä½çé¨åå®çç¨æ³ä½ å°±æå®æ³ææ¯ä¸ä¸ªä¸è¬çneuronã
æ以å¦ä¸å¾æ示ï¼æ个Capsuleï¼Capsuleçoutputå°±æ¯ä¸ä¸ª ï¼è¿è¾¹çåæ ï¼é£Capsuleçinputæ¯ä»ä¹ï¼Capsuleçinputå°±æ¯å ¶å®çCapsuleï¼æè¿è¾¹æä¸ä¸ªé»è²çCapsuleï¼ä»ä¼è¾åº ï¼è¿è¾¹æä¸ä¸ªç»¿è²çCapsuleå®ä¼è¾åº ï¼è¿ä¸¤ä¸ªvectorä¼å½åèè²çCapsuleçinputï¼èè²Capsuleçoutputä¹å¯ä»¥åæå ¶ä»Capsuleçinputã
æ们ç¥éå¨ä¸ä¸ªnetworkéé¢ï¼æ¯ä¸ä¸ªneuronçå·¥ä½å°±æ¯è´è´£åºdectectä¸ä¸ªspecific patternã
举ä¾æ¥è¯´æä¸ä¸ªneuronï¼åè®¾ä½ åå½±å辨è¯ï¼æä¸ä¸ªneuronçå·¥ä½åªæ¯detectå¾å·¦çé¸å´ï¼å¦å¤ä¸ä¸ªneuronçå·¥ä½åªæ¯detectåå³çé¸å´ï¼å ¶å®ä¸å¤ªå¯è½æä¸ä¸ªneuronï¼å®å¯ä»¥åæ¶å两件äºæ ï¼ä¸ä¸ªneuronå®å ¶å®å°±æ¯ä¾¦æµä¸ç§é¸å´èå·²ï¼æä»¥ä½ å¾é¾è¯´æä¸ä¸ªneuronï¼å®å°±æ¯ç说æå左边çé¸å´ï¼ä»è¢«activateï¼åå³è¾¹çé¸å´ï¼å®ä¹è¿è¢«activateã
举ä¾æ¥è¯´åæ ·æ¯é¸å´çpatternï¼ä¹è®¸çåå·¦ççé¸å´ï¼ä»outputç ç第ä¸ç»´å°±æ¯ ï¼åå³ççé¸å´ï¼å®outputç ï¼å®ç¬¬ä¸ç»´å°±æ¯ ï¼ä½è¿ä¸¤ä¸ª å¯è½é¿åº¦æ¯ä¸æ ·çï¼å 为é½åºç°é¸å´ï¼ä½æ¯ä»ä»¬å é¨çå¼æ¯ä¸ä¸æ ·çï¼ä»£è¡¨è¯´ç°å¨è¾å ¥çpatternæä¸åçç¹æ§ã
è¾å ¥ä¸¤ä¸ª ï¼ åå«ä¹ä¸å¦å¤ä¸¤ä¸ªmatrix ,å¾å° ãæ以 ï¼æ¥ä¸æ¥æ å åweighted sumï¼ å¾å° ï¼æ¥ä¸æ¥æ éè¿ä¸ä¸ªå«åæ¤åçæ¹å¼å¾å° ï¼è¿ä¸ªæ¤åæ¯æä¹åäºï¼æ¤åè¿ä»¶äºï¼å®åªä¼æ¹å çé¿åº¦ï¼å®ä¸ä¼æ¹å çæ¹åãæä¹æ¹åå®ï¼æ å é¤ä»¥å®çé¿åº¦ï¼è®©å®åææ¯ä¸ä¸ªé¿åº¦ä¸º ç ï¼åæé¿åº¦ä¸º ç 以åï¼åé¢åä¹ä¸ä¸ä¸ªå¼ï¼è¿ä¸ªå¼æ¯ä»ä¹ææï¼å¦æä»å¤© çé¿åº¦é常é¿ï¼è¿ä¸ªå¼ä¼è¶è¿äº ï¼ çé¿åº¦å°±è¶è¿äº ã å¦æä»å¤© é常çï¼ä»å¤©åé¢è¿ä¸ªå¼å°±ä¼å¾å°ï¼ çé¿åº¦å°±ä¼è¶è¿äº ã
æ»èè¨ä¹ï¼åæ£å°±æ¯è¾å ¥ ï¼ç¶åç»è¿ä¸è¿ä¸²çè¿ç®ï¼å¾å° ï¼å¨è¿ä¸è¿ä¸²çè¿ç®éé¢æ æ ï¼Squashingè¿ä¸ªæ¤åæ¯åºå®çï¼å ¶å®ä½ å°±å¯ä»¥æå®å½åæ¯ä¸ä¸ªæ¿æ´»å½æ°ä¸æ ·ï¼ è· æ¯åæ°ï¼è¿ä¸ªåæ°è¦éè¿backpropagation learnåºæ¥çã
ä»å¤©çç¹å«å°æ¹æ¯è¿è¾¹ å ï¼ä»ä»¬ä¸æ¯éè¿backpropagation learnåºæ¥çã å å«åcoupling coefficientsï¼ä»ä»¬æ¯å¨testingçæ¶åå¨ä½¿ç¨è¿ä¸ªCapsuleçæ¶åå¨æå»å³å®çãè¿ä¸ªå³å®çprocesså«ådynamic routingã
æ以 å ä½ å¯ä»¥æ³æ就好åæ¯poolingä¸æ ·ãMax poolingå°±æ¯ä½ æä¸ç»neuronï¼ç¶ååªéæ大é£ä¸ªå¼åºæ¥ï¼å°åºåªä¸ä¸ªneuronçå¼ä¼è¢«éï¼ å¨trainingçæ¶åæ们ä¸ç¥éï¼å¨testingçæ¶åæå»dynamicå³å®çï¼å®è¿ä¸ªcoupling coefficientsè·max poolingæ¯ä¸æ ·çï¼å®ä¹æ¯onlineçæ¶åå³å®çãmax poolingä½ å¯ä»¥æ³ææ¯è¦è¢«maxçé£ä¸ä¸ªneuronï¼å®çä½ç½®å°±æ¯1ï¼å ¶å®ä¸ºçå°±æ¯é¶ãå ¶å®ä»å¤©è¿ä¸ªcoupling coefficientsï¼dynamic routingï¼ä½ å°±æ³ææ¯max poolingçä¸ä¸ªè¿é¶çï¼ä»ä¸æ¯1æè æ¯0ï¼è¿è¾¹å¯ä»¥æ¯ä¸ä¸æ ·çå®æ°ï¼ä½æ¯æè®°å¾ï¼ çåå¿ é¡»è¦æ¯1ï¼ä½å®ä¸ä¸å®è¦æ¯1æ0ï¼ä»è·max poolingå¾åï¼ä»æ¯å¨æµè¯çæ¶åå¨æå³å®çã
æ¥ä¸æ¥è®² ï¼ åæ¯æä¹ç¡®å®çï¼
æ们å æ¥çdynamic routingçæ¼ç®æ³ï¼ä¸å¼å§æ们ç°å¨å设è¾å ¥ ï¼æ ç¨ åweighted sum以åï¼æ们å¾å° ï¼ åéè¿æ¤åå°±å¾å°Capsuleæåç ã
é£ä¹æ们æ¥çç æ¯æä¹è¿ä½çï¼é¦å ä½ è¦æä¸ç»åæ° ï¼ çåå§å¼é½æ¯ ï¼è 就对åºå° ï¼å设ä»å¤©å°±è· 个iterationï¼ æ¯ä¸ä¸ªHyper-parameterï¼ä½ è¦äºå å®å¥½çã
æ¥ä¸æ¥æ们æ åsoftmaxå¾å° ï¼æ以æåæ讲说 çåå¿ é¡»æ¯ ãæäº ä»¥åä½ å°±å¯ä»¥åweighted sumï¼å¾å° ï¼ è¿ä¸æ¯æç»ç ï¼æ们æå¾å°ç åæ¤åå¾å° ï¼è¿ä¸ª ä¹ä¸æ¯æç»çç»æ ï¼è¿æ¯æ们å¦å¤è®¡ç®å¾å°ç å ï¼ç¶åæ¥ä¸æ¥æ们ç¨è®¡ç®åºæ¥ç å»update çå¼ï¼ä½ å°±æ 计ç®åºæ¥çç»æå»è·æ¯ä¸ä¸ª åå 积ï¼å¦ææ个 å çå 积ç»æç¹å«å¤§ï¼å³ä»ä»¬ç¹å«æ¥è¿çè¯ï¼å¯¹åºå°çinputçå¼å°±ä¼å¢å ã
å¦ä¸å¾æ示ï¼æ们举个ä¾åï¼å设å³ä¸è§çº¢é»ç»¿ä¸ä¸ªç¹æ¯ ï¼ç¶åç»è¿ä¸çªè®¡ç®ä»¥åï¼ä½ å¾å° æ¯è¿è¾¹ç°è²çç¹ï¼è¿ä¸ªç¹è·çº¢è²çç¹ã绿è²çç¹æ¯è¾åï¼çº¢è²ç¹çè·ç»¿è²ç¹å®ä»¬ç å°±ä¼ä¸åï¼èä»ä»¬çç¶åå®ç ä¸åï¼ä»ä»¬ç ä¹å°±ä¼è·çä¸åï¼ç¶åæ¥ä¸æ¥ç°è²çç¹å°±ä¼å¾çº¢è²çç¹è·ç»¿è²çç¹æ´é è¿ã
æ以ä»å¤©dynamic routingè¿ä»¶äºï¼ä»å¨å³å®è¿ä¸ª çæ¶åæç¹åæ¯æé¤ç¦»ç¾¤ç¹ï¼outlierï¼çæè§ï¼å 为æ³æ³çï¼ä½ æ ä½weighted sumï¼ç¶ååå¾å° ï¼æ们å设 å°±è·weighted sumçç»æå¾åï¼å¦æä»å¤©ææä¸ä¸ªäººï¼æ¯å¦è¯´ è·å ¶ä»äººé½å¾ä¸åï¼ä»å¤©ç®åºæ¥ç å°±ä¼è·ä»å¾ä¸åï¼ä»çweightå°±ä¼æ¯è¾å°ï¼åç®åºå®çcoupling coefficientsçæ¶åï¼å®ç®åºæ¥å°±æä¸ç¹å°ã
æ»ç»ä¸ä¸å°±æ¯ï¼ä»å¤©å¨inputçè¿ä¸ç»vectoréé¢ï¼å¦æææäºäººè·å ¶ä»äººé½æ¯è¾ä¸åï¼å®çweightå°±ä¼è¶æ¥è¶å°ã
ç°å¨å设è·äº 个iteration以åï¼æ们就å¾å°äº 个iterationç ï¼è¿ä¸ªå°±æ¯æ们æåè¦æ¿æ¥è®¡ç® è· çcoupling coefficientsï¼æè æ¯å¦ææ们ç¨å¾ç¤ºæ¥å±å¼çè¯ï¼çèµ·æ¥åæ¯è¿ä¸ªæ ·åï¼
æ们æ ç¶ååå«ä¹ä¸ å¾å° ï¼ç¶åæ们åå§å¼ é½æ¯ ã
æ¥ä¸æ¥æ ¹æ® æ们å¯ä»¥å¾å° ï¼æäº ä»¥åï¼æ们å¯ä»¥è®¡ç®åºä¸ä¸ª ï¼ç¶åå¾å° ï¼æ ¹æ® æ们å¯ä»¥å³å®ä¸ä¸è½®ç ï¼æä¹å³å®ä¸ä¸è½®ç å¢ï¼ä½ è¦éè¿è¿ä¸ªå¼å: ï¼å»è®¡ç® è· å çç¸ä¼¼çç¨åº¦ï¼å¦æ è· æ¯è¾åï¼ä¹å å°±ä¼å¢å ï¼å¦æ è· æ¯è¾åï¼ä¹å å°±ä¼å¢å ï¼ç è·è°åè°çweightå°±ä¼å¢å ï¼å¥½ï¼æ以æäº ä»¥åä½ å°±ä¼å»updateä½ ç ï¼æäºæ°ç 以åï¼ä½ 就计ç®åºæ°ç ï¼ç¶åä½ å°±å¾å° ï¼æ ¹æ® ä½ å°±å¯ä»¥å¾å°æ°çweightï¼ â¦â¦ä»¥æ¤ç±»æ¨ï¼å°±å¯ä»¥å¾å° ï¼å°±æ¯æç»çè¾åº äºã
èè¿æ´ä¸ªprocesså ¶å®å®å°±è· rnnæ¯ä¸æ ·çãä½ outputç ï¼ä¼åä¸ä¸ä¸ªæ¶é´ç¹è¢«ä½¿ç¨ï¼è¿ä¸ªå¨ rnnéé¢å°±å¥½åæ¯hidden layerçmemoryéé¢çå¼ä¸æ ·ï¼å¨åä¸ä¸ªæ¶é´ç¹çè¾åºä¼å¨ä¸ä¸ä¸ªæ¶é´ç¹ä½¿ç¨ã
æ以å¨training çæ¶åï¼å®é ä¸ä½ trainçæ¶åä½ è¿æ¯ç¨backpropagationï¼å¾å¤ååºæé½è¯´Hiltonä»è¦æ¨ç¿»backpropagationï¼å ¶å®æçä¹å¥½åä¸æ¯è¿æ ·çï¼ä½ ååçååºåä¸å°åæï¼å ¶å®ä¹å¥½åä¹ä¸æ¯è¿ä¸ªæ ·åï¼æåtrainçæ¶åè¿æ¯ç¨backpropagationï¼æä¹ç¨å¢ï¼è¿ä¸ªtrainingå°±è·RNNå¾åï¼å°±æ¯è¯´è¿ä¸ªdynamic routingä½ å°±å¯ä»¥æ³ææ¯ä¸ä¸ªRNNï¼ç¶åtrainä¸å»å°±åtrain RNNä¸æ ·ï¼trainä¸å»ä½ å°±å¾å°é£ä¸ªç»æã
å®é ä¸è¿ä¸ªCapsuleæä¹trainï¼
é¦å Capsuleå¯ä»¥æ¯convolutionçãæ们ç¥é说å¨åå·ç§¯çæ¶åï¼æ们ä¼æä¸å filterï¼ç¶åæ«è¿é£ä¸ªå¾çï¼Capsuleå¯ä»¥å代filterï¼filterå°±æ¯inputä¸å¹ å¾ççä¸å°ååºåå¾å°outputçvalueï¼é£ä¹Capsuleå°±æ¯inputä¸å¹ å¾ççä¸å°ååºåå¾å°ä¸ä¸ª ï¼å°±è¿æ ·çå·®å«èå·²ãCapsuleæåçoutputé¿ä»ä¹æ ·åï¼
å设æ们ç°å¨è¦åçæ¯æåæ°å辨è¯ï¼è¾¨è¯ä¸å¼ imageï¼åæ¥å¦ææ¯ä¸è¬çneuron networkï¼ä½ outputå°±æ¯å个neuronï¼æ¯ä¸ªneuron对åºå°ä¸ä¸ªå¯è½çæ°åï¼å¦ææ¯Capsuleï¼ä½ output å°±æ¯å个Capsuleï¼æ¯ä¸ä¸ªCapsule就对åºå°ä¸ä¸ªæ°åã
å¯æ¯ä½ 说Capsuleçè¾åºæ¯ä¸ä¸ªvectorï¼æ们æä¹ç¥é说å¨è¿ä¸ªvectoréé¢è¿ä¸ªæ°åæ没æåºç°å¢ï¼æ们åæ讲è¿è¯´vectorçnorm就代表äºpatternåºç°çconfidenceãæ以ä»å¤©å¦æä½ è¦ç¥éæ°å1æ没æåºç°ï¼ä½ å°±æå¯¹ç §æ°å1çCapsuleï¼åä»ç对åº1çvectoré£ä¸ªnormï¼é£ä¹å°±æ¯å¾å°äºæ°å1çconfidenceãåçå ¶ä»æ°åï¼
é£ä¹å¨trainingçæ¶åï¼è¾å ¥æ°å ä½ å½ç¶å¸æè¾åºæ°å çconfidenceè¶å¤§è¶å¥½ï¼æ以ä»å¤©å¦æè¾å ¥æ¯æ°å ï¼ä½ å°±å¸æ说 çnormè¶å¤§è¶å¥½ï¼ä½ å¸æ çnorm被åå°ï¼ç»èçå¼åæ们就ä¸ååºæ¥ï¼ç²¾ç¥å°±æ¯è¿ä¸ªæ ·åç:
èå¨Hilton çpaperéé¢ï¼å®è¿å äºä¸ä¸ªreconstructionçnetworkï¼æ¯è¯´ä»æCapsuleçoutputåè¿å»ï¼ç¶åoutput reconstructåºåæ¥çimageãè¿ä¸ªCapsNetçoutputä»å ¶å®æ¯ä¸ævectorï¼å¦ææ¯æåæ°å辨è¯ï¼å®çoutputå°±æ¯å个vectorãé£å¦ä¸å¾ç»¿è²æ¹æ¡NNè¿ä¸ªneuron networkå°±æè¿å个vectorç串æ¥åè¿å»ï¼ç¶åå¸æå¯ä»¥åreconstructionãå¨å®ä½ä¸çæ¶åï¼å¦æä»å¤©ç¥éinputçæ°åæ¯ ï¼é£ä¹å°±ä¼æ对åºå° çCapsuleçoutputä¹ ï¼å ¶ä»æ°åç»ç»é½ä¼ä¹ ãå¦æä»å¤©å¯¹åºçæ°åè¾å ¥çæ°åæ¯ ï¼é£å°±æ¯å°±ä¼æ对åºå° çCapsuleçoutputä¹ ï¼å ¶ä»æ°åç»ç»é½ä¼ä¹ ãå¾å°neuron networkï¼å¸æå¯ä»¥reconstructååæ¥çè¾å ¥ã
å¦ä¸å¾æ示ï¼æ¥ä¸æ¥æ们å æ¥çä¸ä¸Capsuleçå®éªç»æï¼è¿ä¸ªå®éªç»æbaselineåºè¯¥æ¯ä¸ä¸ªCNNçnetworkï¼å¨MNISTä¸é误çå ¶å®å¾ä½ï¼0.%çé误çãæ¥ä¸æ¥åè¡åå«æ¯Capsuleçç»æï¼routing 1次æè æ¯routing 3次ï¼æ²¡æreconstructionåæreconstructionï¼è¿è¾¹å¾ææ¾çæreconstruction çperformanceææ¯è¾å¥½ï¼è³äºrouting 1次æè æ¯routing 3次è°æ¯è¾å¥½å°±æç¹é¾è¯´ï¼å¨æ²¡æreconstructionçæ¶åï¼ç¶årouting 1次æ¯è¾å¥½ï¼æreconstructionçæ¶åï¼routing 3次æ¯è¾å¥½ã
è¿è¾¹æå¦å¤ä¸ä¸ªå®éªæ¯æ³è¦å±ç¤ºCapsNetå®å¯¹ænoiseçè½åï¼ä»çrobustçè½åï¼æ以ä»å¤©è¿ä¸ªå®éªæMNISTçCapsNetåä¸ä¸ªaffine transformationï¼ä½æ³¨æä¸ä¸training没æaffine transformationï¼æ以training è·testingæ¯æç¹mismatchã ætestingæ æä½ä¸ºä¸ä¸ªaffine以åï¼å 为training è·testingæ¯mismatchçï¼æ以å½ç¶ç论ä¸ä½ çnetwork performanceæ¯ä¼åå·®ï¼æ以CapsNetçæ£ç¡®çæå°%ãä½æ¯traditional convolutional neuron networkmodelæçæ´å¤ï¼ä»æ¯%çæ£ç¡®çï¼è¿æ¾ç¤ºè¯´CapsNetå®æ¯è¾Robustï¼ä½ æåä¸ä¸affine transformationï¼ CapsNetçperformanceæçéæ¯æ¯è¾å°çã
æ们åææ说æ¯ä¸ä¸ªCapsuleçoutput çæ¯ä¸ä¸ªdimension就代表äºç°å¨patternçæç§ç¹å¾ãæä¹éªè¯è¿ä¸ä»¶äºå¢ï¼
æåä¸æ¯è¯´æä¸ä¸ªä¼åreconstructionçnetworkåï¼ç¨å®åCapsuleçoutputå°±å¯ä»¥ååimageã好ï¼æ们就让ä»åæä¸ä¸ªCapsuleçoutputï¼ç¶åæ æè°æ´è¿ä¸ªCapsuleçoutputæä¸ä¸ªdimensionï¼å°±å¯ä»¥ç¥é说è¿ä¸ªCapsuleçoutputçdimensionï¼ä»ä»£è¡¨äºä»ä¹æ ·çç¹å¾ã举ä¾æ¥è¯´å¨Hiltonçpaperçå®éªä¸çå°è¯´ææäºdimensionï¼ä»ä»£è¡¨äºç¬ç»çç²ç»ï¼ææäºdimension代表äºæ转ççï¼å°±æ¯ä¸ä¸ªdimensioné½æ¯ä»£è¡¨äºä»å¤©ä½ è¦ä¾¦æµçpatternçæä¸ç§ç¹å¾ã
å¦ä¸å¾æ示ï¼ä¸ºå®éªç»æï¼
æåè¿ä¸ªå®éªæ¯æ³è¦æ¾ç¤ºCapsuleçreconstructionçè½åï¼è¿ä¸ªå®éªæ¯è¿æ ·ï¼ä»æ¯ænetwork trainå¨MultiMNISTä¸é¢ï¼ä¹å°±networkå¨trainçæ¶å她çå°çimageæ¬æ¥å°±æ¯æéå ï¼æè§å¾è¿ä¸ªå®éªå ¶å®å¦ææå¦å¤ä¸ä¸ªçæ¬æ¯ï¼trainingçæ¶åæ¯æ²¡æéå çä¸è¬æ°åï¼testingçæ¶åæéå è¿å¯ä»¥è¾¨è¯åºæ¥ï¼æå°±ççè§å¾æé¦ä½©çäºä½æå°ï¼ä½è¿ä¸ªä¸æ¯è¿æ ·ï¼è¿ä¸ªåºè¯¥æ¯trainingåtestingé½æ¯æéå çæ°åçã
é£ä¹machineéè¦åçå·¥ä½æ¯æè¿ä¸¤ä¸ªæ°å辨è¯åºæ¥ãåæ³æ¯ï¼ç»machineççè¿ä¸å¼ æ°åï¼ä¸ç¥éæ¯åªä¸¤ä¸ªæ°åçå åï¼ç¶åmachineå®è¾¨è¯åºæ¥æ¯7è·1çç»åçå¯è½æ§æ¯è¾å¤§ãæ¥ä¸æ¥ååå«æ7è·1丢å°reconstructionéé¢ï¼ä½ å°±å¯ä»¥åå«æ7è·1 reconstructåæ¥ï¼æ以è¿è¾¹å°±æ¾ç¤ºä¸ä¸reconstructçç»æï¼æ们ç第ä¸æ第ä¸å¼ å¾ï¼çèµ·æ¥æ¯4ï¼å ¶å®æ¯2è·7å å¨ä¸èµ·ï¼ç¶å她被reconstruct以åï¼å®å°±å¯ä»¥çåºæ¥è¯´çº¢è²é¨åæ¯2ï¼ç»¿è²çé¨åæ¯7ãåç第ä¸æ第äºå¼ å¾ï¼å¦æå®è¾¨è¯åºæ¥æ¯5è·0ï¼ä½æ¯ä½ è¦æ±ä»reconstruct 5å7ï¼ä½ æ7çé£ä¸ªvector å³ï¼å¯¹åºå°7çCapsuleçoutput丢å°reconstruct networkéé¢å«ä»reconstructï¼ææ没æçå°7ï¼æ以7çé¨åå°±ä¼æ¶å¤±ã好ï¼è¿ä¸ªæ¯CapsNetçä¸äºå®éªã好ï¼ä¸ºä»ä¹CapsNetä¼workå¢ï¼æ¥ä¸æ¥ï¼æ们就æ¥ççè¿ä¸ªç»æçç¹è²ã
æ两个ç¹æ§ï¼ä¸ä¸ªå«Invarianceï¼ä¸ä¸ªå«Equivarianceã
Invarianceæ¯ä»ä¹ææï¼inputä¸å¼ imageï¼å¾å°è¿æ ·çoutputï¼æinputå¦å¤ä¸å¼ imageï¼ä¹å¾å°è¿ä¸ªoutputï¼ä»ä»¬é½æ¯1ï¼è½ç¶æç¹ä¸ä¸æ ·ï¼networkå¦ä¼æ è§è¿ä¸ªå·®å«å¾å°ä¸æ ·çè¾åºãå¦ä¸å¾å·¦è¾¹æ示ï¼
æè°çEquivarianceæææ¯è¯´æ们并ä¸æ¯å¸ænetwork inputä¸ä¸æ ·çä¸è¥¿å°±è¾åºä¸æ ·ä¸è¥¿ï¼æ们å¸ænetworkè¾åºå®å ¨å°åæ äºç°å¨çå°çè¾å ¥ï¼æ¯å¦è¯´ä½ è¾å ¥è¿å¼ 1ï¼å¾å°ç»ææ¯è¿æ ·ï¼ä½ è¾å¦å¤ä¸å¼ 1ï¼å ¶å®è¿ä¸ª1æ¯å·¦è¾¹è¿å¼ 1ç翻转ï¼é£å®çè¾åºå°±æ¯å·¦è¾¹çvectorç翻转ãå¦ä¸å¾å³è¾¹æ示ï¼
é£CNNçmax poolingçæºå¶ï¼åªè½åå°Invarianceï¼ä¸è½å¤ççåå°Equivarianceã为ä»ä¹ï¼CNNå°±æ¯ä¸ç»neuronéé¢éæ大çåºæ¥ï¼ç°å¨inputæ¯ ï¼max poolingé ï¼max poolingé3ã inputä¸ä¸æ ·çä¸è¥¿ï¼outputä¸æ ·çä¸è¥¿ï¼å®åªåå°Invariance;
ä½CapsNetå¯ä»¥åå°Equivarianceè¿ä»¶äºæ ï¼æä¹åå°å¢ï¼ç°å¨inputè¿ä¸ª åºæ¥ï¼ è¿å»ï¼ç¶å让Capsuleçoutputè¦è¯´çå° çconfidenceå¾é«ï¼inputå¦å¤ä¸å¼ ï¼CapsNetè¦è¯´æçå° çconfidenceä¹å¾é«ï¼ä»å¤©å®å¨å¯¹åºå° çCapsuleçoutputç ï¼ä»ä»¬çnormé½è¦æ¯å¤§çï¼å¨è¾å ¥è¿ä¸¤å¼ imageçæ¶åï¼ä½æ¯ä»ä»¬å¨ånormä¹åçvectoréé¢çå¼å¯ä»¥æ¯ä¸ä¸æ ·ï¼èè¿ä¸ªä¸ä¸æ ·å¯ä»¥åæ çè¿ä¸¤ä¸ª ä¹é´çå·®å¼ã
æ以å¦æè¦æ个æ¯æ¹çè¯ï¼ä½ å°±å¯ä»¥æ³æ说Invarianceå ¶å®æ¯è¯´è¿ä¸ªnetworkå¾è¿éï¼ä»æ¯ä¸ªç¹å«è¿éç人ï¼äººå®¶èµç¾ä»ææ¹è¯ä»å¯¹ä»æ¥è¯´æ¯æ²¡å·®çï¼å 为å®çèµ·æ¥å°±æ¯æ²¡å·®å«ãä½æ¯Capsuleä¸ä¸æ ·ï¼ä»ç¥éå·®å«ï¼ä½æ¯ä»éæ©ä¸å»çä¼ï¼å°±æ¯è¾å ¥çå·®å«å¨Capsuleçoutputæ被åç°ï¼åªæ¯ånormçæ¶åï¼æå没æç¨å°å·®å«ã
è³äºDynamic Routingï¼ä¸ºä»ä¹ä¼workå¢ï¼æç´è§è§å¾Dynamic Routingé常åAttention-based modelå multi-hopï¼æ们ä¹åå·²ç»è®²è¿memory networkåï¼æ们说éé¢æattentionçæºå¶ï¼ç¶åæmulti-hopçæºå¶ã
Dynamic Routingå ¶å®å¾åè¿ä¸ªï¼ä½ å¯ä»¥æinputç å°±æ³ææ¯è¿è¾¹çdocumentãç¶åè¿è¾¹ç ä½ å°±æ³ææ¯attentionçweightï¼ä½ å å¾å°ä¸ç»attentionçweightï¼æ½åºä¸ä¸ªvectorï¼ç¶ååå头åå»åattentionï¼åæ½åºä¸ä¸ªvectoråå头å»åattentionï¼è·memory networkéé¢çattentionå multi-hopçæºå¶æ¯ä¸æ ·ï¼æ¯é常类似çï¼è³äºä»ä¸ºä»ä¹ä¼workï¼å ¶å®æ没æå¾ç¡®å®ï¼æè§å¾è¿è¾¹å ¶å®éè¦ä¸ä¸ªå®éªï¼è¿ä¸ªå®éªæ¯ä»ä¹ï¼ä½ æ¢ä¸æ¢è®©é£äº çå¼ä¹è·çbackpropagationä¸èµ·è¢«learnåºæ¥è¿æ ·åï¼å 为ä»å¤©æ们并没æéªè¯è¯´å¦æ çå¼ç¨å«çæ¹æ³åå¾performanceä¼ä¸ä¼æ¯è¾å¥½ï¼å¦æä»å¤© çå¼ä¹è·çbackpropagationä¸èµ·è¢«learnåºæ¥ï¼ä½ä»çperformanceæ¯capsuleè¿è¦å·®çè¯ï¼æå°±ä¼è§å¾è¯´Dynamic Routingæè¿ä»¶äºæ æ¯ççæç¨ã
è¿è¾¹å°±æ¯ä¸äºreferenceç»å¤§å®¶åèï¼
CapsNet入门系列之二:胶囊如何工作
在Max Pechyonkin的系列文章中,第二篇深入探讨了胶囊网络的工作原理。胶囊网络不同于传统神经元,它引入了胶囊这一概念,旨在捕捉更丰富的特征表示和不变性。胶囊是具有内部计算能力的局部单元,它们不是简单地输出单一标量,而是生成包含信息量丰富的输出向量。这些向量不仅能表示特征的存在概率,还包含了实例参数,如位姿、照明和变形信息。
与传统的卷积神经网络不同,胶囊网络不追求神经元活动的视角不变性,而是通过“胶囊”实现等变性。每个胶囊能识别和适应特定的观察条件,即使对象在图像中移动,胶囊检测概率保持不变,而实例参数则会相应调整。例如,面部检测的胶囊会根据眼睛、嘴巴和鼻子的检测结果,预测面部的位置和状态,即使位置变化,概率恒定,方向则会根据移动进行调整。
胶囊网络的工作过程包括输入向量的矩阵乘法,以权重矩阵W编码特征间的空间关系;随后,通过动态路由算法决定输出发送给哪个高级胶囊,这不同于神经元的标量权重调整;接着,所有输入向量组合并经过非线性压缩,保持方向不变但减小长度,以保持检测概率的不变性。
总的来说,胶囊网络的设计旨在提升模型的表征能力和不变性,通过向量形式和层次关系的编码,实现了活动的等变性和特征概率的不变性,这是传统神经网络所不具备的特性。
胶囊网络到底是什么东东?
胶囊网络是一种新兴的深度学习架构,尤其在计算机视觉领域有着重大潜力。它旨在解决卷积神经网络(CNNs)的某些局限,如对训练数据的需求、图像细节保留和对模糊性的处理。相较于CNNs,胶囊网络能在较少数据上实现良好的泛化,且能更好地处理模糊图像,保持更高的空间分辨率,并在物体识别时保留姿态信息,实现“等变化”特性。
与CNNs需要大量训练数据不同,胶囊网络的推广性更强。它们能够在图像微小变化时输出相应变化,这对于语义分割等任务至关重要。在部件识别上,胶囊网络提供了一种层次结构,而CNNs则需要额外组件。尽管如此,胶囊网络在大型图像任务上的性能不如CNNs,并存在计算量大和拥挤问题,但其基本理念非常有前景,只需适当调整即可发挥潜力。
胶囊网络的核心在于其胶囊结构,每个胶囊是一组神经元,负责检测特定区域的特定目标,输出包含概率估计和姿态参数编码的向量。这些向量在不同层(基本胶囊和路由胶囊)中交互,通过路由协议算法来检测物体及其姿态。例如,基本胶囊通过卷积层处理输入,而路由胶囊则使用“路由协议”来整合来自不同胶囊的信息,特别是在模糊场景中,这种协议有助于解释和解析图像,如在图7中的模糊倒置房子场景中,胶囊网络能更好地解析出船和房子的组合。
总的来说,胶囊网络通过创新的架构和算法,为计算机视觉任务提供了新的可能,虽然仍有改进空间,但其潜力无限。关注云栖社区知乎机构号,获取更多深度学习技术内容。
初探胶囊网络(Capsule Network)二:胶囊网络是如何工作的
胶囊网络的工作机制详解 胶囊网络与传统CNN的区别主要在于其内部结构的创新。传统神经网络中的神经元处理输入是通过三个步骤:标量加权、求和及非线性化。然而,胶囊网络的处理过程更为复杂,涉及四步操作:对输入向量进行矩阵乘法,例如高层胶囊通过低层胶囊(如眼睛、嘴巴和鼻子)的向量信息来识别人脸,矩阵W编码了这些特征之间的空间关系。
对矩阵乘法后的向量进行标量加权,但与神经网络不同,胶囊网络采用动态寻路算法而非反向传播。
对加权后的向量求和,这一步骤与传统神经网络相似。
最后是向量到向量的非线性化,胶囊网络使用Squash激活函数,将输出向量压缩到一个概率范围。
胶囊网络的创新之处在于其输出不是单一的标量,而是包含方向和位置信息的向量,这增加了特征的丰富性和可解释性。其结构如图所示,每个胶囊负责捕捉特定特征的多维度信息。 下一章将深入探讨动态寻路算法,进一步理解胶囊网络如何利用这个机制在不同胶囊间传递和整合信息。欲了解更多内容,关注公众号“论文收割机”。参考资料:
Sabour, Sara, Frosst, Nicholas, and Hinton, Geoffrey E. Dynamic routing between capsules. Advances in Neural Information Processing Systems, .
medium.com/ai³-theory-practice-business/understanding-hintons-capsule-networks-part-ii-how-capsules-work-b6ade9f
胶囊网络——动态路由算法
动态路由算法,其灵感来源于胶囊网络,专门用于计算胶囊的相似度权重系数和更新相似度。胶囊网络与传统神经网络的主要差异在于,它将输入视为向量,且每个维度能代表特定意义。下面详细介绍胶囊网络的核心流程。
动态路由算法的基本流程包括:计算相似度权重、获取胶囊输入、获取胶囊输出、归一化以及更新低层胶囊的相似度。
首先,计算相似度权重。权重用于衡量低层胶囊与高层胶囊之间的相似度,即投票。初始值设为零,权重由公式决定,其中参数衡量胶囊激活的可能性。
随后,获取胶囊输入。低层胶囊向量经过变换矩阵作用得到新的向量。
接着,获取胶囊输出。将计算得到的相似度权重带入公式中,进行加权求和,得到最终的胶囊输出。
为了确保输出范围在0到1之间,使用squash非线性函数进行归一化。squash函数能将大范围输入压缩到较小区间,常用sigmoid或tanh双曲正切函数。
最后,更新低层胶囊的相似度,通过迭代上述过程,完成胶囊网络的训练。
胶囊网络的动态路由与transformer的多头注意机制在计算方式和处理角度上存在显著差异。在胶囊网络中,相似度权重自下而上计算,且不同类型的胶囊考虑角度不同,每个底层胶囊均在高层胶囊上进行归一化。而在transformer中,注意力权重自上而下计算,每个注意力头独立处理输入,最终输出在最后步骤中通过组合或线性转换得到。


2024-12-23 01:02
2024-12-23 00:57
2024-12-23 00:55
2024-12-23 00:29
2024-12-23 00:14
2024-12-23 00:10
2024-12-23 00:02
2024-12-22 23:59