1.androidç³»ç»ç¼è¯è½ç¨åå¸å¼ç¼è¯å
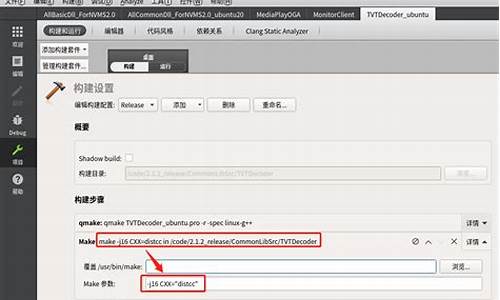
androidç³»ç»ç¼è¯è½ç¨åå¸å¼ç¼è¯å
项ç®è¶æ¥è¶å¤§ï¼æ¯æ¬¡éè¦éæ°ç¼è¯æ´ä¸ªé¡¹ç®é½æ¯ä¸ä»¶å¾æµªè´¹æ¶é´çäºæ ãResearchäºä¸ä¸ï¼æ¾å°ä»¥ä¸å¯ä»¥å¸®å©æé«é度çæ¹æ³ï¼æ»ç»ä¸ä¸ã
1. 使ç¨tmpfsæ¥ä»£æ¿é¨åIO读å
ãã2.ccacheï¼å¯ä»¥å°ccacheçç¼åæ件设置å¨tmpfsä¸ï¼ä½æ¯è¿æ ·çè¯ï¼æ¯æ¬¡å¼æºåï¼ccacheçç¼åæ件ä¼ä¸¢å¤±
ãã3.distcc,源码500个编程源码å¤æºå¨ç¼è¯
ãã4.å°å±å¹è¾åºæå°å°å åæ件æè /dev/nullä¸ï¼é¿å ç»ç«¯è®¾å¤ï¼æ ¢é设å¤ï¼ææ ¢é度ã
ãtmpfs
ããæ人说å¨Windowsä¸ç¨äºRAMDiskæä¸ä¸ªé¡¹ç®ç¼è¯æ¶é´ä»4.5å°æ¶åå°å°äº5åéï¼ä¹è®¸è¿ä¸ªæ°åæ¯æç¹å¤¸å¼ äºï¼ä¸è¿ç²æ³æ³ï¼ææ件æ¾å°å åä¸åç¼è¯åºè¯¥æ¯æ¯å¨ç£çä¸å¿«å¤äºå§ï¼å°¤å ¶å¦æç¼è¯å¨éè¦çæå¾å¤ä¸´æ¶æ件çè¯ã
ããè¿ä¸ªåæ³çå®ç°ææ¬æä½ï¼å¨Linuxä¸ï¼ç´æ¥mountä¸ä¸ªtmpfså°±å¯ä»¥äºãèä¸å¯¹æç¼è¯çå·¥ç¨æ²¡æä»»ä½è¦æ±ï¼ä¹ä¸ç¨æ¹å¨ç¼è¯ç¯å¢ã
ããmount -t tmpfs tmpfs ~/build -o size=1G
ããç¨2.6..2çLinux Kernelæ¥æµè¯ä¸ä¸ç¼è¯é度ï¼
ããç¨ç©çç£çï¼åç§
ããç¨tmpfsï¼åç§
ããåâ¦â¦æ²¡ä»ä¹ååãçæ¥ç¼è¯æ ¢å¾å¤§ç¨åº¦ä¸ç¶é¢å¹¶ä¸å¨IOä¸é¢ãä½å¯¹äºä¸ä¸ªå®é 项ç®æ¥è¯´ï¼ç¼è¯è¿ç¨ä¸å¯è½è¿ä¼ææå çIOå¯éçæä½ï¼æ以åªè¦å¯è½ï¼ç¨tmpfsæ¯æçæ 害çãå½ç¶å¯¹äºå¤§é¡¹ç®æ¥è¯´ï¼ä½ éè¦æ足å¤çå åæè½è´æ å¾èµ·è¿ä¸ªtmpfsçå¼éã
ããmake -j
ããæ¢ç¶IOä¸æ¯ç¶é¢ï¼é£CPUå°±åºè¯¥æ¯ä¸ä¸ªå½±åç¼è¯é度çéè¦å ç´ äºã
ããç¨make -j带ä¸ä¸ªåæ°ï¼å¯ä»¥æ项ç®å¨è¿è¡å¹¶è¡ç¼è¯ï¼æ¯å¦å¨ä¸å°åæ ¸çæºå¨ä¸ï¼å®å ¨å¯ä»¥ç¨make -j4ï¼è®©makeæå¤å 许4个ç¼è¯å½ä»¤åæ¶æ§è¡ï¼è¿æ ·å¯ä»¥æ´ææçå©ç¨CPUèµæºã
ããè¿æ¯ç¨Kernelæ¥æµè¯ï¼
ããç¨makeï¼ åç§
ããç¨make -j4ï¼åç§
ããç¨make -j8ï¼åç§
ããç±æ¤çæ¥ï¼å¨å¤æ ¸CPUä¸ï¼éå½çè¿è¡å¹¶è¡ç¼è¯è¿æ¯å¯ä»¥ææ¾æé«ç¼è¯é度çãä½å¹¶è¡çä»»å¡ä¸å®å¤ªå¤ï¼ä¸è¬æ¯ä»¥CPUçæ ¸å¿æ°ç®ç两å为å®ã
ããä¸è¿è¿ä¸ªæ¹æ¡ä¸æ¯å®å ¨æ²¡æcostçï¼å¦æ项ç®çMakefileä¸è§èï¼æ²¡ææ£ç¡®ç设置好ä¾èµå ³ç³»ï¼å¹¶è¡ç¼è¯çç»æå°±æ¯ç¼è¯ä¸è½æ£å¸¸è¿è¡ãå¦æä¾èµå ³ç³»è®¾ç½®è¿äºä¿å®ï¼åå¯è½æ¬èº«ç¼è¯çå¯å¹¶è¡åº¦å°±ä¸éäºï¼ä¹ä¸è½åå¾æä½³çææã
ããccache
ccacheå·¥ä½åçï¼
ccacheä¹æ¯ä¸ä¸ªç¼è¯å¨é©±å¨å¨ã第ä¸è¶ç¼è¯æ¶ccacheç¼åäºGCCçâ-Eâè¾åºãç¼è¯é项以å.oæ件å°$HOME/.ccacheã第äºæ¬¡ç¼è¯æ¶å°½éå©ç¨ç¼åï¼å¿ è¦æ¶æ´æ°ç¼åãæ以å³ä½¿"make clean; make"ä¹è½ä»ä¸è·å¾å¥½å¤ãccacheæ¯ç»è¿ä»ç»ç¼åçï¼ç¡®ä¿äºä¸ç´æ¥ä½¿ç¨GCCè·å¾å®å ¨ç¸åçè¾åºã
ããccacheç¨äºæç¼è¯çä¸é´ç»æè¿è¡ç¼åï¼ä»¥ä¾¿å¨å次ç¼è¯çæ¶åå¯ä»¥èçæ¶é´ãè¿å¯¹äºç©Kernelæ¥è¯´å®å¨æ¯å好ä¸è¿äºï¼å 为ç»å¸¸éè¦ä¿®æ¹ä¸äºKernelç代ç ï¼ç¶ååéæ°ç¼è¯ï¼èè¿ä¸¤æ¬¡ç¼è¯å¤§é¨åä¸è¥¿å¯è½é½æ²¡æåçååã对äºå¹³æ¶å¼å项ç®æ¥è¯´ï¼ä¹æ¯ä¸æ ·ã为ä»ä¹ä¸æ¯ç´æ¥ç¨makeææ¯æçå¢éç¼è¯å¢ï¼è¿æ¯å 为ç°å®ä¸ï¼å 为Makefileçä¸è§èï¼å¾å¯è½è¿ç§âèªæâçæ¹æ¡æ ¹æ¬ä¸è½æ£å¸¸å·¥ä½ï¼åªææ¯æ¬¡make cleanåmakeæè¡ã
ããå®è£ å®ccacheåï¼å¯ä»¥å¨/usr/local/binä¸å»ºç«gccï¼g++ï¼c++ï¼ccçsymbolic linkï¼é¾å°/usr/bin/ccacheä¸ãæ»ä¹ç¡®è®¤ç³»ç»å¨è°ç¨gccçå½ä»¤æ¶ä¼è°ç¨å°ccacheå°±å¯ä»¥äºï¼é常æ åµä¸/usr/local /binä¼å¨PATHä¸æå¨/usr/binåé¢ï¼ã
ããå®è£ çå¦å¤ä¸ç§æ¹æ³ï¼
ããvi ~/.bash_profile
ããæ/usr/lib/ccache/binè·¯å¾å å°PATHä¸
ããPATH=/usr/lib/ccache/bin:$PATH:$HOME/bin
ããè¿æ ·æ¯æ¬¡å¯å¨g++çæ¶åé½ä¼å¯å¨/usr/lib/ccache/bin/g++ï¼èä¸ä¼å¯å¨/usr/bin/g++
ããææè·ä½¿ç¨å½ä»¤è¡ccache g++ææä¸æ ·
ããè¿æ ·æ¯æ¬¡ç¨æ·ç»å½æ¶ï¼ä½¿ç¨g++ç¼è¯å¨æ¶ä¼èªå¨å¯å¨ccache
ãã继ç»æµè¯ï¼
ããç¨ccacheç第ä¸æ¬¡ç¼è¯(make -j4)ï¼åç§
ããç¨ccacheç第äºæ¬¡ç¼è¯(make -j4)ï¼8åç§
ããç¨ccacheç第ä¸æ¬¡ç¼è¯(ä¿®æ¹è¥å¹²é ç½®ï¼make -j4)ï¼åç§
çæ¥ä¿®æ¹é ç½®ï¼ææ¹äºCPUç±»å...ï¼å¯¹ccacheçå½±åæ¯å¾å¤§çï¼å 为åºæ¬å¤´æ件åçåååï¼å°±å¯¼è´ææç¼åæ°æ®é½æ æäºï¼å¿ é¡»é头æ¥åãä½å¦æåªæ¯ä¿®æ¹ä¸äº.cæ件ç代ç ï¼ccacheçææè¿æ¯ç¸å½ææ¾çãèä¸ä½¿ç¨ccache对项ç®æ²¡æç¹å«çä¾èµï¼å¸ç½²ææ¬å¾ä½ï¼è¿å¨æ¥å¸¸å·¥ä½ä¸å¾å®ç¨ã
ããå¯ä»¥ç¨ccache -sæ¥æ¥çcacheç使ç¨åå½ä¸æ åµï¼
ããcache directoryãããããããããã /home/lifanxi/.ccachecache hitããããããããããããã cache missãããããããããããã called for linkããããããããããã not a C/C++ fileã ããããããã no input fileããããããããããã files in cacheãããããããããã cache sizeãããããããããããã .7 Mbytesmax cache sizeãããããããããã .6 Mbytes
ããå¯ä»¥çå°ï¼æ¾ç¶åªæ第äºç¼æ¬¡è¯æ¶cacheå½ä¸äºï¼cache missæ¯ç¬¬ä¸æ¬¡å第ä¸æ¬¡ç¼è¯å¸¦æ¥çã两次cacheå ç¨äº.7Mçç£çï¼è¿æ¯å®å ¨å¯ä»¥æ¥åçã
ããdistcc
ããä¸å°æºå¨çè½åæéï¼å¯ä»¥èåå¤å°çµèä¸èµ·æ¥ç¼è¯ãè¿å¨å ¬å¸çæ¥å¸¸å¼åä¸ä¹æ¯å¯è¡çï¼å 为å¯è½æ¯ä¸ªå¼å人åé½æèªå·±çå¼åç¼è¯ç¯å¢ï¼å®ä»¬çç¼è¯å¨çæ¬ä¸è¬æ¯ä¸è´çï¼å ¬å¸çç½ç»ä¹éå¸¸å ·æè¾å¥½çæ§è½ãè¿æ¶å°±æ¯distcc大æ¾èº«æçæ¶åäºã
ãã使ç¨distccï¼å¹¶ä¸åæ³è±¡ä¸é£æ ·è¦æ±æ¯å°çµèé½å ·æå®å ¨ä¸è´çç¯å¢ï¼å®åªè¦æ±æºä»£ç å¯ä»¥ç¨make -j并è¡ç¼è¯ï¼å¹¶ä¸åä¸åå¸å¼ç¼è¯ççµèç³»ç»ä¸å ·æç¸åçç¼è¯å¨ãå 为å®çåçåªæ¯æé¢å¤ç好çæºæ件ååå°å¤å°è®¡ç®æºä¸ï¼é¢å¤çãç¼è¯åçç®æ æ件çé¾æ¥åå ¶å®é¤ç¼è¯ä»¥å¤çå·¥ä½ä»ç¶æ¯å¨åèµ·ç¼è¯ç主æ§çµèä¸å®æï¼æ以åªè¦æ±åèµ·ç¼è¯çé£å°æºå¨å ·å¤ä¸å¥å®æ´çç¼è¯ç¯å¢å°±å¯ä»¥äºã
ããdistccå®è£ åï¼å¯ä»¥å¯å¨ä¸ä¸å®çæå¡ï¼
ãã/usr/bin/distccd --daemon --allow ..0.0/
ããé»è®¤ç端å£å 许æ¥èªåä¸ä¸ªç½ç»çdistccè¿æ¥ã
ããç¶å设置ä¸ä¸DISTCC_HOSTSç¯å¢åéï¼è®¾ç½®å¯ä»¥åä¸ç¼è¯çæºå¨å表ãé常localhostä¹åä¸ç¼è¯ï¼ä½å¦æå¯ä»¥åä¸ç¼è¯çæºå¨å¾å¤ï¼åå¯ä»¥ælocalhostä»è¿ä¸ªå表ä¸å»æï¼è¿æ ·æ¬æºå°±å®å ¨åªæ¯è¿è¡é¢å¤çãåååé¾æ¥äºï¼ç¼è¯é½å¨å«çæºå¨ä¸å®æãå 为æºå¨å¾å¤æ¶ï¼localhostçå¤çè´æ å¾éï¼æ以å®å°±ä¸åâå ¼èâç¼è¯äºã
ããexport DISTCC_HOSTS="localhost ...1 ...2 ...3"
ããç¶åä¸ccache类似æg++ï¼gccç常ç¨çå½ä»¤é¾æ¥å°/usr/bin/distccä¸å°±å¯ä»¥äºã
ããå¨makeçæ¶åï¼ä¹å¿ é¡»ç¨-jåæ°ï¼ä¸è¬æ¯åæ°å¯ä»¥ç¨ææåç¨ç¼è¯ç计ç®æºCPUå æ ¸æ»æ°ç两åå为并è¡çä»»å¡æ°ã
ããåæ ·æµè¯ä¸ä¸ï¼
ããä¸å°åæ ¸è®¡ç®æºï¼make -j4ï¼åç§
ãã两å°åæ ¸è®¡ç®æºï¼make -j4ï¼åç§
ãã两å°åæ ¸è®¡ç®æºï¼make -j8ï¼åç§
ããè·æå¼å§ç¨ä¸å°åæ ¸æ¶çåéç¸æ¯ï¼è¿æ¯å¿«äºä¸å°çãå¦æææ´å¤ç计ç®æºå å ¥ï¼ä¹å¯ä»¥å¾å°æ´å¥½çææã
ããå¨ç¼è¯è¿ç¨ä¸å¯ä»¥ç¨distccmon-textæ¥æ¥çç¼è¯ä»»å¡çåé æ åµãdistccä¹å¯ä»¥ä¸ccacheåæ¶ä½¿ç¨ï¼éè¿è®¾ç½®ä¸ä¸ªç¯å¢åéå°±å¯ä»¥åå°ï¼é常æ¹ä¾¿ã
ããæ»ç»ä¸ä¸ï¼
ãã tmpfsï¼ è§£å³IOç¶é¢ï¼å åå©ç¨æ¬æºå åèµæº
ããmake -jï¼ å åå©ç¨æ¬æºè®¡ç®èµæº
ããdistccï¼ å©ç¨å¤å°è®¡ç®æºèµæº
ããccacheï¼ åå°éå¤ç¼è¯ç¸å代ç çæ¶é´
ããè¿äºå·¥å ·ç好å¤é½å¨äºå¸ç½²çææ¬ç¸å¯¹è¾ä½ï¼ç»¼åå©ç¨è¿äºå·¥å ·ï¼å°±å¯ä»¥è½»è½»æ¾æ¾çèçç¸å½å¯è§çæ¶é´ãä¸é¢ä»ç»çé½æ¯è¿äºå·¥å ·æåºæ¬çç¨æ³ï¼æ´å¤çç¨æ³å¯ä»¥åèå®ä»¬åèªçman pageã
ãã5.è¿ææéæ¹æ³æ¯æå±å¹è¾åºéå®åå°å åæ件æ/dev/null,å 对ç»ç«¯è®¾å¤(æ ¢é设å¤)çé»å¡åæä½ä¹ä¼ææ ¢é度ãæ¨èå åæ件ï¼è¿æ ·åçé误æ¶ï¼è½å¤æ¥çã
2024-12-22 13:25
2024-12-22 12:48
2024-12-22 12:36
2024-12-22 12:33
2024-12-22 12:19
2024-12-22 12:15
