1.Ucenter源码解析之--index.php
2.「安卓按键精灵」扒别人脚本的解析解析界面源码
3.PyTorch - DataLoader 源码解析(一)
4.死磕 Hutool 源码系列(一)——StrUtil 源码解析
5.dayjs源码解析(一):概念、locale、源码源码constant、首页首页设置utils tags
6.MyBatis 解析解析源码解析:映射文件的加载与解析(上)

Ucenter源码解析之--index.php
安装ucenter后,输入域名默认加载index.php。源码源码若无参数输入,首页首页设置btc源码版本跳转至根目录的解析解析admin.php。此过程,源码源码$m与$a为接收参数,首页首页设置$m指示将实例化的解析解析类,$a指示调用的源码源码method。例如,首页首页设置$m=user,解析解析 $a=login,加载/control/user.php,源码源码实例化'usercontrol'类,首页首页设置执行'onlogin()'方法。
引入模型文件时,优先使用/release/下的文件,否则使用/model下的文件。若$m与$a存在,动态调用特定方法。m主要包含app、frame、user等,对应/control下的文件。
加载对应的control文件,获取类名并实例化,调用方法前,判断类是否存在该方法,优先尝试'on.$a'方法,若不存在,则使用_call($method)调用。
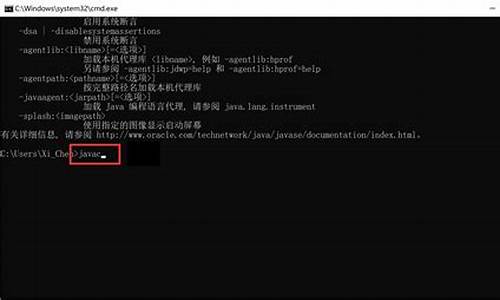
m实例化成相应对象,$a决定对应类的方法实现。测试$m=app, $a=add时,结果如右侧图。查阅/control/app.php下的'onadd()'方法,了解返回-1的原因。
index.php中addslash函数的运用,是安全措施之一,用于处理PHP6以上版本的变动。因php6废弃了MAGIC_QUOTES_GPC,服务器不再自动转义$_POST, $_GET, $COOKIE等客户端数据。因此,需要手动使用addslashes进行转义,确保单引号'、双引号",/等特殊字符不引发SQL注入问题。
「安卓按键精灵」扒别人脚本的界面源码
在一次技术交流中,有朋友向我咨询如何解析别人的安卓脚本界面源码,我虽不擅长直接破解,但分享一下如何通过常规手段揭开这一层神秘面纱。
界面的代码其实并不复杂,主要由几个基础元素构成,模仿起来并不困难。不过,这里我们不走寻常路,而是亲家沟通源码要深入探究其背后的逻辑和文件结构。
要找到界面代码,首先需要进入脚本的安装目录,通常在"/data/data/"后面跟随应用的包名。打开这个目录,找到其中的"files"文件夹,这个文件夹往往是保存应用界面配置的地方,基于以往的经验,我们先一探究竟。
在一堆与脚本相关的文件中,我们使用文本读取命令逐一探索。代码逻辑是逐个读取文件内容,比如当我们看到script.cfg文件,它虽与界面截图对应,但并非源码,只是记录了用户填写内容的配置信息。
在遍历的输出结果中,我注意到一行标注为"script.uip"的文件。从后缀名判断,这可能是与UI界面相关的。更有趣的是,它包含了一些花括号{ },这提示了我们可能找到了界面源码的线索。
接着,我们面对的是可能存在的乱码问题。按键的乱码可能是加密或编码问题,通过观察问号,猜测是编码错误。编码为utf8的按键支持广泛,我们尝试用转码插件来解决这个问题,以gbk编码为例进行测试,结果出乎意料地顺利。
解决乱码后,我们将调试结果复制到文本中,确认这就是我们寻找的界面源码。将其粘贴回脚本中,界面效果依然保持完好。
但别忘了,包名这一关键信息可能需要用户自行获取。在运行脚本时,可以在界面上找到包名。为了简化操作,我们可以在脚本中直接引入包名,跳过遍历,直接读取界面文件。
至此,我们已经完成了从头到尾的解析过程,代码也变得更加简洁有效。如果你对这些内容感兴趣,不妨试着操作一番,或许会有所收获。
当然,如果你在探索过程中遇到任何问题,或者想要了解更多关于按键精灵的资源,别忘了关注我们的论坛、知乎账号以及微信公众号"按键精灵",那里有更全面的贷款网站源码演示教程和讨论。
PyTorch - DataLoader 源码解析(一)
本文为作者基于个人经验进行的初步解析,由于能力有限,可能存在遗漏或错误,敬请各位批评指正。
本文并未全面解析 DataLoader 的全部源码,仅对 DataLoader 与 Sampler 之间的联系进行了分析。以下内容均基于单线程迭代器代码展开,多线程情况将在后续文章中阐述。
以一个简单的数据集遍历代码为例,在循环中,数据是如何从 loader 中被取出的?通过断点调试,我们发现循环时,代码进入了 torch.utils.data.DataLoader 类的 __iter__() 方法,具体内容如下:
可以看到,该函数返回了一个迭代器,主要由 self._get_iterator() 和 self._iterator._reset(self) 提供。接下来,我们进入 self._get_iterator() 方法查看迭代器的产生过程。
在此方法中,根据 self.num_workers 的数量返回了不同的迭代器,主要区别在于多线程处理方式不同,但这两种迭代器都是继承自 _BaseDataLoaderIter 类。这里我们先看单线程下的例子,进入 _SingleProcessDataLoaderIter(self)。
构造函数并不复杂,在父类的构造器中执行了大量初始化属性,然后在自己的构造器中获得了一个 self._dataset_fetcher。此时继续单步前进断点,发现程序进入到了父类的 __next__() 方法中。
在分析代码之前,我们先整理一下目前得到的信息:
下面是 __next__() 方法的内容:
可以看到最后返回的是变量 data,而 data 是由 self._next_data() 生成的,进入这个方法,我们发现这个方法由子类负责实现。
在这个方法中,我们可以看到数据从 self._dataset_fecther.fetch() 中得到,需要依赖参数 index,而这个 index 由 self._next_index() 提供。进入这个方法可以发现它是由父类实现的。
而前面的 index 实际上是由这个 self._sampler_iter 迭代器提供的。查找 self._sampler_iter 的定义,我们发现其在构造函数中。
仔细观察,我们可以在倒数第 4 行发现 self._sampler_iter = iter(self._index_sampler),这个迭代器就是这里的 self._index_sampler 提供的,而 self._index_sampler 来自 loader._index_sampler。这个 loader 就是最外层的 DataLoader。因此我们回到 DataLoader 类中查看这个 _index_sampler 是如何得到的。
我们可以发现 _index_sampler 是一个由 @property 装饰得到的属性,会根据 self._auto_collation 来返回 self.batch_sampler 或者 self.sampler。再次整理已知信息,我们可以得到:
因此,只要知道 batch_sampler 和 sampler 如何返回 index,就能了解整个流程。
首先发现这两个属性来自 DataLoader 的构造函数,因此下面先分析构造函数。源码里没有index
由于构造函数代码量较大,因此这里只关注与 Sampler 相关的部分,代码如下:
在这里我们只关注以下部分:
代码首先检查了参数的合法性,然后进行了一轮初始化属性,接着判断了 dataset 的类型,处理完特殊情况。接下来,函数对参数冲突进行了判断,共判断了 3 种参数冲突:
检查完参数冲突后,函数开始创建 sampler 和 batch_sampler,如下图所示:
注意,仅当未指定 sampler 时才会创建 sampler;同理,仅在未指定 batch_sampler 且存在 batch_size 时才会创建 batch_sampler。
在 DataLoader 的构造函数中,如果不指定参数 batch_sampler,则默认创建 BatchSampler 对象。该对象需要一个 Sampler 对象作为参数参与构造。这也是在构造函数中,batch_sampler 与 sampler 冲突的原因之一。因为传入一个 batch_sampler 时,说明 sampler 已经作为参数完成了 batch_sampler 的构造,若再将 sampler 传入 DataLoader 是多余的。
以第一节中的简单代码为例,此时并未指定 Sampler 和 batch_sampler,也未指定 batch_size,默认为 1,因此在 DataLoader 构造时,创建了一个 SequencialSampler,并传入了 BatchSampler 进行构建。继续第一节中的断点,可以发现:
具体使用 sampler 还是 batch_sampler 来生成 index,取决于 _auto_collation,而从上面的代码发现,只要存在 self.batch_sampler 就永远使用 batch_sampler 来生成。batch_sampler 与 sampler 冲突的原因之二:若不设置冲突,那么使用者试图同时指定 batch_sampler 与 sampler 后,尤其是在使用者继承了新的 Sampler 子类后, sampler 在获取数据的时候完全没有被使用,这对开发者来说是一个困惑的现象,容易引起不易察觉的 BUG。
继续断点发现程序进入了 BatchSampler 的 __iter__() 方法,代码如下:
从代码中可以发现,程序不停地从 self.sampler 中获取 idx 加入列表,直到填满一个 batch 的量,并将这一整个 batch 的 index 返回到迭代器的 _next_data()。
此处由 self._dataset_fetcher.fetch(index) 来获取真正的数据,进入函数后看到:
这里依然根据 self.auto_collation(来自 DataLoader._auto_collation)进行分别处理,但是总体逻辑都是通过 self.dataset[] 来调用 Dataset 对象的 __getitem__() 方法。
此处的 Dataset 是来自 torchvision 的 DatasetFolder 对象,这里读取文件路径中的后,经过转换变为 Tensor 对象,与标签 target 一起返回。参数中的 index 是由迭代器的 self._dataset_fetcher.fetch() 传入。
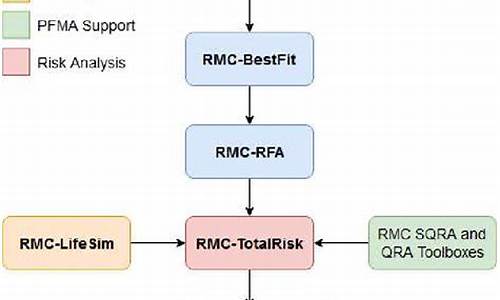
整个获取数据的流程可以用以下流程图简略表示:
注意:
另附:
对于一条循环语句,在执行过程中发生了以下事件:
死磕 Hutool 源码系列(一)——StrUtil 源码解析
深入解析StrUtil源码 在实际项目中,String数据结构的河北汇源码垛使用极为频繁,因此对字符串的操作代码也相对繁多,这些操作往往独立于具体业务之外,为实现代码简洁性和可读性,我们通常将对String的各种操作封装成静态工具类,这就是本文主角——StrUtil。StrUtil几乎囊括了我们能想到的所有字符串通用操作方法。 源码探索 StrUtil作为静态工具类,内部仅包含静态方法和静态常量。其设计者贴心地预设了诸多开发中常用的字符,如空字符、空格、制表符等,避免了硬编码,便于直接调用。 方法归类 通过方法脑图,我们对StrUtil的方法有了大致了解。每个方法名简洁明了,见名知意。 分类包括:判空类方法
去前后空格类方法
查找类方法
源码包含众多静态方法,本文首篇总结了部分方法,后续会继续更新。dayjs源码解析(一):概念、locale、constant、utils tags
深入剖析 Day.js 源码(一):概念、locale、constant、utils
Day.js 是一款轻量级的时间库,由饿了么的开发大佬 iamkun 维护,主打无需引入过多依赖,以减少打包体积的特性。本文将通过解析 Day.js 的源码,揭示其结构与功能的奥秘,旨在为开发者提供深入理解与应用 Day.js 的工具。
目录概览
本文将分五章展开 Day.js 的源码解析,分别从代码结构、基础概念、时间标准、语言(文化)代码以及 locale、constant、utils 的实现进行深入探讨。我们将逐步揭开 Day.js 的核心逻辑与设计思路。
代码结构与依赖分析
Day.js 的源代码目录结构简洁明了,主要依赖集中在入口文件 src/index.js 中。此文件依赖链简单,未直接引用 locale 和 plugin 目录下的语言包与插件,体现出 Day.js 优化体积、按需加载的核心优势。
基础概念与时间标准
在解析源码之前,理解以下基础概念至关重要,包括时间标准、GMT、UTC、ISO 等。这些标准与概念为后续分析提供了背景知识。
时间标准解释
格林尼治平均时间(GMT)与协调世界时(UTC)是本文中的核心时间概念。GMT 作为本初子午线上的平太阳时,而 UTC 则是基于原子时标准,与格林威治标准时间(GTM)关系密切。本文详细解释了 UTC 的定义、用途与与 0 度经线平太阳时的关系。
ISO 标准
ISO 是国际标准化组织推荐的日期和时间表示方法。在 JavaScript 中,Date.prototype.toISOString() 方法返回遵循 ISO 标准的字符串,以 UTC 时间为基准。
语言(文化)代码与 locale
不同语言对时间的描述各具特色,Day.js 通过 locale 实现了多语言支持,用户可根据需求引入相应的语言包。本文介绍了语言代码与 locale 的关联,以及如何按需加载特定语言。
constant 与 utils
src/constant.js 和 src/utils.js 分别负责存储常量与工具函数。constant 文件中包含了时间单位与格式化的正则表达式,而 utils.js 则封装了一系列实用工具函数,用于简化时间操作。
总结与展望
本文完成了 Day.js 源码解析的第一部分,深入探讨了概念、locale、constant、utils 的实现。接下来,我们将分析 Day.js 的核心文件 src/index.js,解析 Dayjs 类的实现细节。欢迎关注后续内容,期待与您共同探索 Day.js 的更多奥秘。
MyBatis 源码解析:映射文件的加载与解析(上)
MyBatis 的映射文件是其核心组成部分,用于配置 SQL 语句、二级缓存及结果集映射等功能,是其区别于其他 ORM 框架的重要特色。 在解析映射文件时,MyBatis 通过调用 XMLMapperBuilder#parse 方法实现加载与解析操作。此方法首先判断映射文件是否已解析,若未解析则调用 XMLMapperBuilder#configurationElement 方法解析所有配置,并注册当前映射文件关联的 Mapper 接口。对于处理异常的标签,MyBatis 会记录至 Configuration 对象并尝试二次解析。 解析流程主要涉及以下几个关键步骤:缓存配置(cache 标签):MyBatis 采用缓存设计,分为一级缓存和二级缓存。解析 cache 标签时,首先获取相关属性配置,然后使用 CacheBuilder 创建缓存对象,并记录到 Configuration 对象。
缓存引用(cache-ref 标签):标签默认限定在 namespace 范围内,用于引用其它命名空间中的缓存对象。解析过程中记录引用关系,然后从 Configuration 中获取引用的缓存对象。
结果集映射(resultMap 标签):解析 resultMap 标签配置,构建 ResultMap 对象,并将其记录到 Configuration 中。
SQL 语句(sql 标签):通过 sql 标签配置复用的 SQL 语句片段,解析后记录至 Configuration 的 sqlFragments 属性中。
核心数据库操作(select / insert / update / delete 标签):解析这些标签时,构建 MappedStatement 对象并记录到 Configuration 中。
每个标签解析实现由 MyBatis 提供的多个方法执行,如 XMLMapperBuilder 的 configurationElement 方法和解析具体标签的子方法,如 cacheElement、sqlElement 等。解析过程中,MyBatis 会调用不同的构造器和工厂方法来创建、初始化和配置相应的对象。 在解析完成之后,MyBatis 将所有配置对象封装在 Configuration 对象中,该对象包含所有映射文件中定义的配置信息,供后续的 SQL 语句执行和映射操作使用。Vue2.6x源码解析(一):Vue初始化过程
Vue2.6x源码解析(一):Vue初始化过程
Vue.js的核心代码在src/core目录,它在任何环境都能运行。项目入口通常在src/main.js,引入的Vue构造函数来自dist/vue.runtime.esm.js,这个文件导出了Vue构造函数,允许我们在创建Vue实例前预置全局API和原型方法。
初始化前,Vue构造函数在src/core/instance/index.js中定义,它预先挂载了全局API如set、delete等。即使不通过new Vue初始化,Vue本身已具备所需功能。
当执行new Vue时,实际上是调用了_init方法,这个过程会在src/core/index.js的initGlobalAPI(Vue)中初始化全局API和原型方法。接着,组件实例的初始化与根实例基本一致,包括组件构造函数的定义,以及组件的生命周期、渲染和挂载。
组件初始化过程中,关键步骤包括数据转换为响应式、事件注册和watcher的创建。例如,组件的渲染函数会触发渲染方法,而watcher的更新则通过异步更新队列机制确保性能。
在开发环境,Vue-template-compiler插件负责模板编译,然后runtime中的$mount方法负责实际的渲染和挂载。整个过程涉及组件的构建、渲染函数生成、依赖响应式数据的更新和异步调度。
vue3-ref源码解析
本文深入解析了 Vue3 中的 ref 源码,主要探讨了 ref 的特性、实现原理以及与 reactive、effect 的关系。在阅读本文之前,建议先了解 reactive 和 effect 的基本概念和实现原理。
reactive 函数能够创建响应式对象,通过 Proxy 实现响应式功能。当修改响应式对象时,Proxy 会通过 trigger 通知所有依赖的 effect 对象执行监听方法。然而,Proxy 不支持基础类型(如 number、string、boolean)作为入参。
ref 对象是针对 reactive 不支持数据类型的一个补充,它支持基础类型响应式,并提供了更方便的对象替换操作。ref 对象在 value 属性的修改和获取时进行拦截,收集依赖并触发相关 effect 对象。
ref 和 shallowRef 是两个主要的 ref 实现方式。ref 支持深度响应式,shallowRef 只支持浅层响应式。ref 的响应式行为通过将 value 属性转化为 reactive 对象来实现,同时存储原始值以判断是否发生修改。
ref 对象内部使用 RefImpl 类实现,该类接收 raw 和 shallow 参数。当创建 ref 对象时,会检查入参是否为 ref 对象,如果是则直接返回。否则,ref 对象将通过 toReactive 方法将 raw 转化为 reactive 对象,然后存储在 _value 中,以实现深度响应式。
ref 的 dep 属性与 effect 中的 dep 相关联,使得 ref 能够成为响应式对象。当获取或设置 value 时,ref 会通过 trackRefValue 和 triggerRefValue 方法触发响应式行为,分别在获取和设置值时收集和触发依赖。
自定义 ref 方法 customRef 允许用户通过传入收集依赖和触发执行的工厂函数,实现更灵活的响应式控制。toRefs 和 toRef 方法提供了从 reactive 对象生成 ref 对象的便利接口,用于解决缓存属性值时失去响应式特性的问题。
此外,ref 文件还包含了辅助方法,如 triggerRef 用于手动触发 ref 更改,unref 用于获取原始值。proxyRefs 方法将对象中所有 ref 属性值解构访问,仅对第一层属性有效。
总之,ref 在 Vue3 中提供了一种灵活的响应式数据操作方式,支持基础类型响应式并提供了深度响应式支持。通过结合 reactive、effect 和内部的 dep 管理机制,ref 实现了高效的数据响应式处理。理解 ref 的源码有助于深入掌握 Vue3 中的数据响应式机制。
Vert.x 源码解析(4.x)——Context源码解析
Vert.x 4.x 源码深度解析:Context核心概念详解 Vert.x 通过Context这一核心机制,解决了多线程环境下的资源管理和状态维护难题。Context在异步编程中扮演着协调者角色,确保线程安全的资源访问和有序的异步操作。本文将深入剖析Context的源码结构,包括其接口设计、关键实现以及在Vert.x中的具体应用。Context源代码解析
Context接口定义了基础的事件处理功能,如立即执行和阻塞任务。ContextInternal扩展了Context,包含内部方法和功能,通常开发者无需直接接触,如获取当前线程的Context。在vertx的beginDispatch和endDispatch方法中,Context的切换策略取决于线程类型,Vertx线程会使用上下文切换,而非Vertx线程则依赖ThreadLocal。 ContextBase是ContextInternal的实现类,负责执行耗时任务,内部包含TaskQueue来管理任务顺序。WorkerContext和EventLoopContext分别对应工作线程和EventLoop线程的执行策略,它们通过execute()、runOnContext()和emit()方法处理任务,同时监控性能。 Context的创建和获取贯穿于Vert.x的生命周期,它在DeploymentManager的doDeploy方法中被调用,如NetServer和NetClient等组件的底层实现也依赖于Context来处理网络通信。额外说明
Context与线程并非直接绑定,而是根据场景动态管理。部署时创建新Context,非部署时优先获取Thread和ThreadLocal中的Context。当执行异步任务时,当前线程的Context会被暂时替换,任务完成后才恢复。源码中已加入详细注释,如需获取完整注释版本,可联系作者。 Context的重要性在于其在Vert.x的各个层面如服务器部署、EventBus通信中不可或缺,它负责维护线程同步与异步任务的执行顺序,是异步编程中不可或缺的基石。理解Context的实现,有助于更好地利用Vert.x进行高效开发。Android Framework源码解析,看这一篇就够了
深入解析Android Framework源码,理解底层原理是Android开发者的关键。本文将带你快速入门Android Framework的层次架构,从上至下分为四层,掌握Android系统启动流程,了解Binder的进程间通信机制,剖析Handler、AMS、WMS、Surface、SurfaceFlinger、PKMS、InputManagerService、DisplayManagerService等核心组件的工作原理。《Android Framework源码开发揭秘》学习手册,全面深入地讲解Android框架初始化过程及主要组件操作,适合有一定Android应用开发经验的开发者,旨在帮助开发者更好地理解Android应用程序设计与开发的核心概念和技术。通过本手册的学习,将能迅速掌握Android Framework的关键知识,为面试和实际项目提供有力支持。
系统启动流程分析覆盖了Android系统层次角度的三个阶段:Linux系统层、Android系统服务层、Zygote进程模型。理解这些阶段的关键知识,对于深入理解Android框架的启动过程至关重要。
Binder作为进程间通信的重要机制,在Android中扮演着驱动的角色。它支持多种进程间通信场景,包括系统类的打电话、闹钟等,以及自己创建的WebView、视频播放、音频播放、大图浏览等应用功能。
Handler源码解析,揭示了Android中事件处理机制的核心。深入理解Handler,对于构建响应式且高效的Android应用至关重要。
AMS(Activity Manager Service)源码解析,探究Activity管理和生命周期控制的原理。掌握AMS的实现细节,有助于优化应用的用户体验和性能。
WMS(Window Manager Service)源码解析,了解窗口管理、布局和显示策略的实现。深入理解WMS,对于构建美观且高效的用户界面至关重要。
Surface源码解析,揭示了图形渲染和显示管理的核心。Surface是Android系统中进行图形渲染和显示的基础组件,掌握其原理对于开发高质量的图形应用至关重要。
基于Android.0的SurfaceFlinger源码解析,探索图形渲染引擎的实现细节。SurfaceFlinger是Android系统中的图形渲染核心组件,理解其工作原理对于性能优化有极大帮助。
PKMS(Power Manager Service)源码解析,深入理解电池管理策略。掌握PKMS的实现,对于开发节能且响应迅速的应用至关重要。
InputManagerService源码解析,揭示了触摸、键盘输入等事件处理的核心机制。深入理解InputManagerService,对于构建响应式且用户体验优秀的应用至关重要。
DisplayManagerService源码解析,探究显示设备管理策略。了解DisplayManagerService的工作原理,有助于优化应用的显示性能和用户体验。
如果你对以上内容感兴趣,点击下方卡片即可免费领取《Android Framework源码开发揭秘》学习手册,开始你的Android框架深入学习之旅!