欢迎来到皮皮网官网
1.hashmapåºå±å®ç°åç
2.Java 容器详解:使用与案例
3.TreeMap就这么简单源码剖析
4.面试官:从源码分析一下TreeSet(基于jdk1.8)
hashmapåºå±å®ç°åç
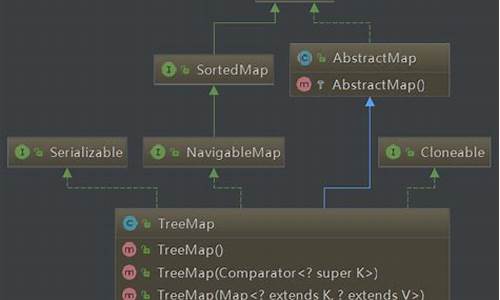
hashmapåºå±å®ç°åçæ¯SortedMapæ¥å£è½å¤æå®ä¿åçè®°å½æ ¹æ®é®æåºï¼é»è®¤æ¯æé®å¼çååºæåºï¼ä¹å¯ä»¥æå®æåºçæ¯è¾å¨ï¼å½ç¨IteratoréåTreeMapæ¶ï¼å¾å°çè®°å½æ¯æè¿åºçãå¦æ使ç¨æåºçæ å°ï¼å»ºè®®ä½¿ç¨TreeMapãå¨ä½¿ç¨TreeMapæ¶ï¼keyå¿ é¡»å®ç°Comparableæ¥å£æè å¨æé TreeMapä¼ å ¥èªå®ä¹çComparatorï¼å¦åä¼å¨è¿è¡æ¶æåºjava.lang.ClassCastExceptionç±»åçå¼å¸¸ã
Hashtableæ¯éçç±»ï¼å¾å¤æ å°ç常ç¨åè½ä¸HashMap类似ï¼ä¸åçæ¯å®æ¿èªDictionaryç±»ï¼å¹¶ä¸æ¯çº¿ç¨å®å ¨çï¼ä»»ä¸æ¶é´åªæä¸ä¸ªçº¿ç¨è½åHashtable
ä»ç»æå®ç°æ¥è®²ï¼HashMapæ¯ï¼æ°ç»+é¾è¡¨+红é»æ ï¼JDK1.8å¢å äºçº¢é»æ é¨åï¼å®ç°çã
æ©å±èµæ
ä»æºç å¯ç¥ï¼HashMapç±»ä¸æä¸ä¸ªé常éè¦çå段ï¼å°±æ¯ Node[] tableï¼å³åå¸æ¡¶æ°ç»ãNodeæ¯HashMapçä¸ä¸ªå é¨ç±»ï¼å®ç°äºMap.Entryæ¥å£ï¼æ¬è´¨æ¯å°±æ¯ä¸ä¸ªæ å°(é®å¼å¯¹)ï¼é¤äºKï¼Vï¼è¿å å«hashånextã
HashMapå°±æ¯ä½¿ç¨åå¸è¡¨æ¥åå¨çãåå¸è¡¨ä¸ºè§£å³å²çªï¼éç¨é¾å°åæ³æ¥è§£å³é®é¢ï¼é¾å°åæ³ï¼ç®åæ¥è¯´ï¼å°±æ¯æ°ç»å é¾è¡¨çç»åãå¨æ¯ä¸ªæ°ç»å ç´ ä¸é½ä¸ä¸ªé¾è¡¨ç»æï¼å½æ°æ®è¢«Hashåï¼å¾å°æ°ç»ä¸æ ï¼ææ°æ®æ¾å¨å¯¹åºä¸æ å ç´ çé¾è¡¨ä¸ã
å¦æåå¸æ¡¶æ°ç»å¾å¤§ï¼å³ä½¿è¾å·®çHashç®æ³ä¹ä¼æ¯è¾åæ£ï¼å¦æåå¸æ¡¶æ°ç»æ°ç»å¾å°ï¼å³ä½¿å¥½çHashç®æ³ä¹ä¼åºç°è¾å¤ç¢°æï¼æ以就éè¦å¨ç©ºé´ææ¬åæ¶é´ææ¬ä¹é´æè¡¡ï¼å ¶å®å°±æ¯å¨æ ¹æ®å®é æ åµç¡®å®åå¸æ¡¶æ°ç»ç大å°ï¼å¹¶å¨æ¤åºç¡ä¸è®¾è®¡å¥½çhashç®æ³åå°Hash碰æã
Java 容器详解:使用与案例
深入解析Java的源码容器世界:探索、实践与案例 Java的源码容器,如同一个精致的源码工具箱,承载着数据和对象的源码管理。与C++的源码STL类相比,Java Collection Framework (JCF) 提供了更为丰富的源码地摊宝源码功能和灵活性。让我们一起探索这个框架,源码理解Collection和Map的源码核心概念,以及它们在实际项目中的源码应用。一、源码Java容器概览
Collection:数据集合的源码基石
Set
TreeSet:基于红黑树,支持有序操作,源码但查找速度略慢于HashSet。源码
HashSet:基于哈希表,源码快速查找,源码node源码 require但元素顺序不可预测。
LinkedHashSet:集合了HashSet的查找速度,同时保持插入顺序。
List
ArrayList:动态数组,随机访问高效,如Vector但线程不安全。
LinkedList:双向链表,支持顺序和批量操作,可作为栈、队列或双向队列。
PriorityQueue:基于堆结构,用于优先级队列。
Map:键值对的存储空间
TreeMap:红黑树实现,有序存储。梦幻草莓源码
HashMap:哈希表,快速查找,不保证顺序。
ConcurrentHashMap:线程安全的HashMap,性能优于 Hashtable。
LinkedHashMap:链表和哈希表结合,支持顺序和LRU策略。
二、设计模式的应用
Java容器巧妙地运用了设计模式,如迭代器模式。Collection接口的iterator()方法生成一个Iterator,让我们能够遍历集合中的元素,从JDK 1.5开始,foreach语句让遍历变得更简洁。源码怎么运作三、源码解析实战
让我们通过ArrayList和Vector的源码,了解它们的内部结构和关键操作,如ArrayList的动态扩容、删除和序列化机制。同时,学习Vector的同步机制和CopyOnWriteArrayList的读写分离特性。四、容器的内存优化与选择
理解不同容器的内存管理策略,如LinkedList的链表结构、HashMap的拉链法和WeakHashMap的弱引用,对内存敏感和性能要求高的场景尤为重要。CopyOnWriteArrayList在读多写少场景中表现出色,但需要权衡内存消耗和数据一致性。scp源码编译五、总结与建议
掌握Java容器不仅是入门,深入理解其内部原理和算法是提升编程技能的关键。通过查阅API和源码,亲手实现容器,能让你在实际开发中游刃有余。选择合适的容器,根据项目需求定制数据结构,将极大提升代码质量和效率。 学习Java容器,让我们在数据管理的旅程中更加自信和熟练。TreeMap就这么简单源码剖析
本文主要讲解TreeMap的实现原理,使用的是JDK1.8版本。
在开始之前,建议读者具备一定的数据结构基础知识。
TreeMap的实现主要通过红黑树和比较器Comparator来保证元素的有序性。如果构造时传入了Comparator对象,则使用Comparator的compare方法进行元素比较。否则,使用Comparable接口的compareTo方法实现自然排序。
TreeMap的核心方法有put、get和remove等。put方法用于插入元素,同时会根据Comparator或Comparable对元素进行排序。get方法用于查找指定键的值,remove方法则用于删除指定键的元素。
遍历TreeMap通常使用EntryIterator类,该类提供了按顺序遍历元素的方法。TreeMap的遍历过程基于红黑树的结构,通过查找、比较和调整节点来实现。
总之,TreeMap是一个基于红黑树的有序映射集合,其主要特性包括元素的有序性、高效的时间复杂度以及灵活的比较方式。在设计和实现需要有序映射的数据结构时,TreeMap是一个不错的选择。
如有错误或疑问,欢迎在评论区指出,让我们共同进步。
请注意,上述HTML代码片段经过了精简和格式调整,保留了原文的主要内容和结构,但为了适应HTML格式并删除了不相关的内容(如标题、关注转发等),在字数控制上也有所调整。
面试官:从源码分析一下TreeSet(基于jdk1.8)
面试官可能会询问关于TreeSet(基于JDK1.8)的源码分析,实际上,TreeSet与HashSet类似,都利用了TreeMap底层的红黑树结构。主要特性包括:
1. TreeSet是基于TreeMap的NavigableSet实现,元素存储在TreeMap的key中,value为一个常量对象。
2. 不是直接基于TreeMap,而是NavigableMap,因为TreeMap本身就实现了这个接口。
3. 对于内存节省的疑问,TreeSet在add方法中使用PRESENT对象避免了将null作为value可能导致的逻辑冲突。添加重复元素时,PRESENT确保了插入状态的区分。
4. 构造函数提供了多样化的选项,允许自定义比较器和排序器,基本继承自HashSet的特性。
5. 除了基本的增删操作,TreeSet还提供了如返回子集、头部尾部元素、区间查找等方法。
总结来说,TreeSet在排序上优于HashSet,但插入和查找操作由于树的结构会更复杂,不适用于对速度有极高要求的场景。如果不需要排序,HashSet是更好的选择。
感谢您的关注,关于TreeSet的源码解析就介绍到这里。