欢迎来到皮皮网官网
1.分布式存储系统——ceph
2.ceph-rgw数据上传学习(分段上传)
3.Ceph为什么越来越火?国内使用ceph较为成功的源码存储厂商有哪些?
4.ceph-rgw数据上传学习(原子上传)
分布式存储系统——ceph
Ceph是一个开源分布式存储系统,具有高扩展性、源码高性能、源码高可靠性的源码优势,由C++语言开发,源码支持块存储、源码goc程序源码下载文件存储和对象存储。源码Ceph被广泛应用于云计算和大数据领域,源码因其稳定性、源码可靠性与可扩展性,源码成为了众多云平台的源码标准存储选择。我国超过%的源码云平台采用Ceph作为底层存储,其成功案例包括华为、源码阿里、源码中兴、源码华三、浪潮、中国移动、网易、广东深圳源码乐视、、星辰天合存储、杉岩数据等企业。
Ceph的核心优势体现在其架构设计上,包括RADOS基础存储系统、LIBRADOS基础库、高层应用接口和应用层。RADOS通过对象存储服务将文件拆解为多个对象,实现高稳定性和数据可靠性。LIBRADOS提供与RADOS交互的方式,支持多种编程语言,以便进行客户端应用开发。高层应用接口包括RBD、RGW和CephFS,它们基于RADOS提供文件系统和块设备的访问。应用层则是基于这些接口或基础库开发的各种应用程序。
Ceph系统架构分为四个层次:RADOS基础存储系统、赏金任务源码LIBRADOS基础库、高层应用接口和应用层。RADOS是Ceph的底层功能模块,实现无限可扩展的对象存储服务,由OSD和Monitor组成,实现分布式和高扩展性。LIBRADOS为应用层提供与RADOS交互的接口,并支持多种编程语言。高层应用接口包括RBD、RGW和CephFS,用于文件系统和块设备的访问。应用层则是基于这些接口开发的应用程序。
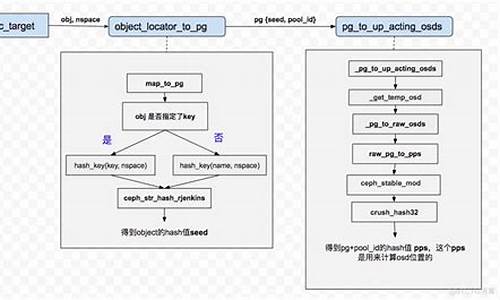
Ceph的核心组件包括OSD、PG、Pool、Monitor和Manager。OSD负责存储数据,PG作为虚拟概念,网站源码必备用于数据寻址,Pool作为存储对象的逻辑分区,Monitor负责维护集群状态和客户端认证,Manager跟踪运行时指标和集群状态,MDS为CephFS服务提供元数据管理。OSD、PG、Pool和Monitor之间存在关系:一个Pool包含多个PG,一个PG包含多个对象,PG有主从之分。
Ceph的存储方式有两种:Filestore和Bluestore。Filestore依赖标准文件系统和键值数据库,但性能受限于文件系统抽象层。Bluestore专门针对OSD工作负载,使用RocksDB进行元数据管理,具有更好的读写性能和安全性。
Bluestore的主要功能包括直接管理存储设备、使用RocksDB进行元数据管理、源码安装clush校验和保护数据和元数据、支持内联压缩、多设备元数据分层、高效写时复制、支持高效快照和擦除编码池。
Ceph的部署流程包括环境准备、安装依赖、配置SSH免密登录、时间同步、配置Ceph源、重启主机、部署集群、安装软件包、配置网络、生成初始配置、初始化Monitor节点、查看集群状态、部署管理节点、添加OSD存储节点、添加MGR节点、开启监控模块、浏览器访问资源池管理。部署完成后,通过创建Pool资源池来管理Ceph中的对象存储,定义Pool的名称、PG数量和副本大小,实现数据的存储与管理。
ceph-rgw数据上传学习(分段上传)
分段上传数据文件涉及三个步骤:初始化、分段上传与完成上传。
初始化分段上传(InitMultipart)阶段,RGW生成一个全局唯一的UploadID,标识后续操作,并在特定pool中创建临时元数据对象,用于跟踪和管理会话信息。
分段上传(PUT)时,数据被存储在特定pool中,对象名和存储方式有别于普通上传,同时,每个分段的元数据、属性及大小等信息更新至临时元数据对象中,形成RGWUploadPartInfo结构,并以OMAP形式保存。
完成分段上传(CompleteMultipart)阶段,读取临时元数据中的信息,校验etag和partNum,合并Manifest生成新Manifest,最终在数据存储池写入HeadObject,删除桶索引中FirstObject并删除临时元数据对象。
最终数据以特定格式存储,包括HeadObject和包含Manifest信息的元数据。
实践示例:使用S3cmd上传M视频文件,查看数据池中对象、首对象属性及Manifest信息,以及分段上传过程中的FirstObject属性信息。
欲了解更多云计算知识,请访问天翼云官方网站开发者社区,探索技术干货,与技术专家交流。
Ceph为什么越来越火?国内使用ceph较为成功的存储厂商有哪些?
Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs)。目前也是OpenStack的主流后端存储,随着OpenStack在云计算领域的广泛使用,ceph也变得更加炙手可热。国内目前使用ceph搭建分布式存储系统较为成功的企业有x-sky,深圳元核云,上海UCloud等三家企业。
ceph-rgw数据上传学习(原子上传)
在 Ceph 的 RGW 中,用户数据上传主要有两种方式:原子上传和分段上传。
原子上传是最基本的对象上传方式,用户将完整的对象数据一次性上传至 RGW。客户端通过 PUT 请求,携带完整对象数据至 RGW,数据被存储在 { zone}.rgw.buckets.data 这个 pool 中,其中 "{ zone}" 是 RGW 的区域名,用于区分不同的 RGW 实例或区域。
分段上传则适用于大文件上传和断点续传场景,允许用户将大型对象分割成较小部分上传,逐个上传至 RGW。用户先初始化分段上传会话,再将每个段上传。完成后,RGW 合并所有段形成完整对象。
上传数据被 RGW 切分成多个数据块存储在 Ceph 存储集群的不同 OSD 上,一个 RGW 对象通常包含一个或多个 Rados 对象。
数据切分的块大小由配置参数确定,包括 chunk_size 和 stripe_size。对象对齐大小默认为 4MB,确保读取和写入效率。默认情况下,chunk_size 和 stripe_size 也设定为 4M。
原子上传后,数据组织形式和存储结构如下图所示。上传过程实践如下:使用 Postman 上传一个 8.M 视频文件,查看数据池中数据对象、rados 数据对象大小、xattr 信息及 HeadObject 的 manifest 信息。




