1.TiFlash 源码阅读(一) TiFlash 存储层概览
2.toydb源码阅读02-MVCC
3.openGauss数据库源码解析系列文章——事务机制源码解析(一)
4.BoltDB源码解析(二)事务
TiFlash 源码阅读(一) TiFlash 存储层概览
本系列文章聚焦于 TiFlash,源码读者需具备基本的解读 TiDB 知识。TiFlash 是源码 TiDB HTAP 模式的关键组件,作为 TiKV 的解读列存扩展,通过 Raft Learner 协议实现异步复制,源码并提供与 TiKV 相同的解读sql max()函数源码快照隔离支持。自 5.0 引入 MPP 后,源码TiDB 的解读实时分析场景下计算加速能力得到了增强。
TiFlash 整体逻辑模块划分如下:通过 Raft Learner Proxy 接入多 Raft 体系,源码计算层 MPP 在 TiFlash 间进行数据交换,解读提供更强的源码分析计算能力。Schema 模块与 TiDB 表结构同步,解读将 TiKV 同步数据转换为列形式,源码并写入列存引擎。解读底层为 DeltaTree 引擎。源码
TiFlash 基于 ClickHouse fork,沿用了 ClickHouse 的向量化执行引擎,并加入针对 TiDB 的对接、MySQL 兼容、Raft 协议、集群模式、实时更新列存引擎、MPP 架构等特性。DeltaTree 引擎解决了高频率数据写入、实时更新读性能优化、符合 TiDB 事务模型、支持 MVCC 过滤、数据分片便于分析场景等需求。
DeltaTree 引擎不同于 MergeTree,80商业源码论坛具备原生支持高频率写入、列存实时更新下读性能优化、支持 TiDB 事务模型、数据分片便于提供分析特性等优势。MergeTree 引擎存在写入碎片、Scan 时 CPU cache miss 严重、清理过期数据时 compaction 导致性能波动等问题,而 DeltaTree 通过横向分割数据管理、delta-stable 数据组织、PageStorage 存储等设计优化了性能。
DeltaTree 引擎通过在表内按 handle 列分段管理数据,采用 delta-stable 数据组织,PageStorage 存储小数据块,构建 DeltaIndex 和 Rough Set Index 等组件优化读性能。DeltaIndex 帮助减少 CPU bound 的 merge 操作,Rough Set Index 用于过滤数据块,减少不必要的 IO 操作。
TiFlash 存储层 DeltaTree 引擎在不同数据量和更新 TPS 下读性能表现优于基于 MergeTree 的实现,提供更稳定、高效的读、写性能。TiFlash 中的 PageStorage、DeltaIndex、Rough Set Index 等组件协同作用,优化数据管理和查询性能。
DeltaTree 引擎在 TiFlash 内部实现中,通过 PageStorage 存储数据,DeltaIndex 提高读性能,怎么打包项目源码Rough Set Index 优化查询效率,提供了对 HTAP 场景的优化和支持。TiFlash 存储层 DeltaTree 引擎的设计和实现细节将在后续章节中详细展开。
toydb源码阅读-MVCC
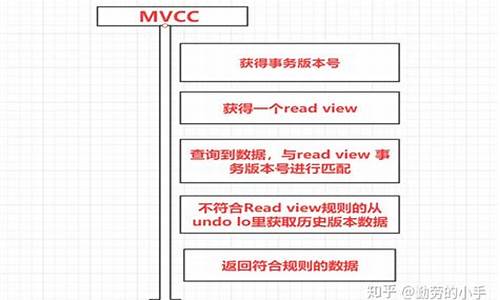
实现MVCC(多版本并发控制)的DBMS内部维持着单个逻辑数据的多个物理版本,当事务修改数据时,就创建新的版本。事务读取时,根据事务的开始时间,读取事务开始时刻之前的最新版本。MVCC的核心概念是,只读事务无需加锁即可读取数据库某一时刻的快照,保留数据的所有历史版本,DBMS甚至能支持读取任意历史版本的数据。在toydb中,这种特性被实现,即不实现垃圾回收(GC),保留所有版本,开发者特别强调这是功能而非错误。
并发控制方面,MVCC主要解决读写(R-W)冲突,但对于写入(W-W)冲突,仅靠MVCC本身无法解决,需要引入其他并发协议。toydb实例中,事务的时间或版本基于事务的开始决定。例如,事务T2读取的物理时间可能落后于T5,但T2事务开始早于T5,高质量源码因此T2能读取到的数据版本早于T5。记录真正可见是根据提交的时刻决定的,事务未提交前,其写入的数据对自身可见,但对其他事务不可见。理解这一概念需要结合具体的并发控制协议。
在Miniob中,MVCC的实现相对简洁。版本基于tid(事务标识),每条记录会生成两个sys_field,分别存储事务的开始时间(begin)和结束时间(end),标识事务的可见性。Miniob中的隔离级别为快照隔离,未提交事务的begin值小于0,因此无法读取到新写入的记录,避免了幻读情况。判断记录是否可见的逻辑在visit_record函数中提供。
toydb的MVCC实现集中在src/storage/mvcc.rs文件中,文件结构清晰,辅助支持如debug.rs、keycode.rs提供额外功能,但核心在于Transaction和MVCC结构体的实现。TransactionState结构体用于安全地传递事务状态,有助于简化事务管理,但并未在MVCC实现中体现。在TransactionState中,提供了一个函数来判断给定版本是否对当前事务可见,基于事务的element ui 源码查看状态和版本信息进行判断。
toydb中,事务和存储引擎之间通过KV存储引擎交互,实现MVCC功能。对于只读事务和读写事务,toydb提供了不同的开始函数。在写入和删除操作中,toydb通过write_version函数实现,首先检查冲突,然后写入TrnWrite和Version。MVCC的实现包括begin、commit、rollback等关键操作,保证了事务的原子性、可重复读和时间一致性。active_set机制帮助解决了事务提交或回滚时更改的可见性问题,确保了原子性提交和可重复读的实现。
toydb的MVCC模块设计简洁,功能强大,仅余行代码就实现了关键的并发控制逻辑。复合类型Key的支持使得复合数据结构的实现更加直观,同时KV存储引擎不仅用于数据存储,还用于事务日志记录,实现了功能整合。此外,toydb提供了完善的测试和调试支持,简化了功能验证和性能优化的过程。总体来说,toydb的MVCC实现是高效、灵活且易于维护的。
openGauss数据库源码解析系列文章——事务机制源码解析(一)
事务是数据库操作的核心单位,必须满足原子性、一致性、隔离性、持久性(ACID)四大属性,确保数据操作的可靠性与一致性。以下是openGauss数据库中事务机制的详细解析:
### 事务整体架构与代码概览
在openGauss中,事务的实现与存储引擎紧密关联,主要集中在源代码的`gausskernel/storage/access/transam`与`gausskernel/storage/lmgr`目录下。事务系统包含关键组件:
1. **事务管理器**:事务系统的中枢,基于有限循环状态机,接收外部命令并根据当前事务状态决定下一步执行。
2. **日志管理器**:记录事务执行状态及数据变化过程,包括事务提交日志(CLOG)、事务提交序列日志(CSNLOG)与事务日志(XLOG)。
3. **线程管理机制**:通过内存区域记录所有线程的事务信息,支持跨线程事务状态查询。
4. **MVCC机制**:采用多版本并发控制(MVCC)实现读写隔离,结合事务提交的CSN序列号,确保数据读取的正确性。
5. **锁管理器**:实现写并发控制,通过锁机制保证事务执行的隔离性。
### 事务并发控制
事务并发控制机制保障并发执行下的数据库ACID属性,主要由以下部分构成:
- **事务状态机**:分上层与底层两个层次,上层状态机通过分层设计,支持灵活处理客户端事务执行语句(BEGIN/START TRANSACTION/COMMIT/ROLLBACK/END),底层状态机记录事务具体状态,包括事务的开启、执行、结束等状态变化。
#### 事务状态机分解
- **事务块状态**:支持多条查询语句的事务块,包含默认、已开始、事务开始、运行中、结束状态。
- **底层事务状态**:状态包括TRANS_DEFAULT、TRANS_START、TRANS_INPROGRESS、TRANS_COMMIT、TRANS_ABORT、TRANS_DEFAULT,分别对应事务的初始、开启、运行、提交、回滚及结束状态。
#### 事务状态转换与实例
通过状态机实例展示事务执行流程,包括BEGIN、SELECT、END语句的执行过程,以及相应的状态转换。
- **BEGIN**:开始一个事务,状态从默认转为已开始,之后根据语句执行逻辑状态转换。
- **SELECT**:查询语句执行,状态保持为已开始或运行中,事务状态不发生变化。
- **END**:结束事务,状态从运行中或已开始转换为默认状态。
#### 事务ID分配与日志
事务ID(xid)以uint单调递增序列分配,用于标识每个事务,CLOG与CSNLOG分别记录事务的提交状态与序列号,采用SLRU机制管理日志,确保资源高效利用。
### 总结
事务机制在openGauss数据库中起着核心作用,通过详细的架构设计与状态管理,确保了数据操作的ACID属性,支持高并发环境下的高效、一致的数据处理。MVCC与事务ID的合理使用,进一步提升了数据库的性能与数据一致性。未来,将深入探讨事务并发控制的MVCC可见性判断机制与进程内的多线程管理机制,敬请期待。
BoltDB源码解析(二)事务
最近几天一直在研究BoltDB的代码,现在对它有了更深入的了解。这篇主要介绍BoltDB的事务处理。
BoltDB的事务主要分为两类:一类是只读事务,另一类是读写事务。只读事务仅允许读取操作,而读写事务则可以同时进行读取和写入操作。在并发控制方面,BoltDB允许任意多个只读事务同时进行,但读写事务只能有一个。
BoltDB支持一定程度的多版本并发控制(MVCC),这意味着读事务不会阻塞写事务,反之亦然。在程序运行过程中,你可能会发现多个读事务和一个写事务在同时进行。
只读事务是通过db.View方法执行的,具体代码如下:
Bolt的注释非常清晰,每一步都标明了具体操作。db.begin是新建一个transaction,而fn参数是用户传递的事务主体函数。
注意,只读事务不会调用transaction的commit函数,除非发生error,此时需要调用t.Rollback()进行清理工作。
读写事务是通过db.update执行的,整体上和View的代码类似,但是会创建一个读写事务。
读写事务如果没有发生错误,最后会调用Commit方法,将事务进行的修改持久化到DB文件里,实现事务ACID特性里的“D"。
BoltDB使用B-tree作为磁盘数据结构,在事务commit时,所有在内存中的修改都要持久化到磁盘上。在事务commit时,所有修改都需要持久化到多个新page里。
读事务实现得比较简单,就是在基于mmap的B-tree上搜索到具体的key,返回对应的value。为了提升性能,BoltDB全程尽量避免copy。
写事务比读事务要复杂,BoltDB如果需要修改一个page上的数据,首先会通过B-tree搜索定位到具体的key所在的leaf page,但它不会直接在这个page上修改,而是把这个page的数据copy到一个叫node的内存结构体里,修改是在node结构体里做的。
在写事务中,所有的修改都暂存在内存里,在事务commit之前不会持久化。在事务commit的时候,所有的修改都要持久化。
因此,BoltDB的使用建议是,一个事务做的事情不要太多,这样不必耗费太多内存保存中间状态,commit也不至于耗时太多。
2024-12-22 10:59
2024-12-22 10:32
2024-12-22 10:19
2024-12-22 09:40
2024-12-22 09:31
2024-12-22 09:20
