凱米颱風豪雨害地基掏空? 高雄仁武驚見馬路塌陷
2024-12-23 01:23
1.【硬核福利】量化交易神器talib中28个技术指标的码解Python实现(附全部源码)
2.Python数据分析实战-实现T检验(附源码和实现效果)
3.关于numpy互相关函数np.correlate的一点疑问
4.AI - NLP - 解析npy/npz文件 Java SDK

【硬核福利】量化交易神器talib中28个技术指标的Python实现(附全部源码)
本文将带您深入学习纯Python、Pandas、码解Numpy与Math实现TALIB中的码解个金融技术指标,不再受限于库调用,码解从底层理解指标原理,码解提升量化交易能力。码解云购app 源码
所需核心库包括:Pandas、码解Numpy与Math。码解重要提示:若遇“ewma无法调用”错误,码解建议安装Pandas 0.版本,码解或调整调用方式。码解
我们逐一解析常见指标:
1. 移动平均(Moving Average)
2. 指数移动平均(Exponential Moving Average)
3. 动量(Momentum)
4. 变化率(Rate of Change)
5. 均幅指标(Average True Range)
6. 布林线(Bollinger Bands)
7. 转折、码解access源码成本支撑、码解阻力点(Trend,码解 Support & Resistance)
8. 随机振荡器(%K线)
9. 随机振荡器(%D线)
. 三重指数平滑平均线(Triple Exponential Moving Average)
. 平均定向运动指数(Average Directional Movement Index)
. MACD(Moving Average Convergence Divergence)
. 梅斯线(High-Low Trend Reversal)
. 涡旋指标(Vortex Indicator)
. KST振荡器(KST Oscillator)
. 相对强度指标(Relative Strength Index)
. 真实强度指标(True Strength Index)
. 吸筹/派发指标(Accumulation/Distribution)
. 佳庆指标(ChaiKIN Oscillator)
. 资金流量与比率指标(Money Flow & Ratio)
. 能量潮指标(Chande Momentum Oscillator)
. 强力指数指标(Force Index)
. 简易波动指标(Ease of Movement)
. 顺势指标(Directional Movement Index)
. 估波指标(Estimation Oscillator)
. 肯特纳通道(Keltner Channel)
. 终极指标(Ultimate Oscillator)
. 唐奇安通道指标(Donchian Channel)
参考资料:
深入学习并应用这些指标,将大大提升您的量化交易与金融分析技能。
Python数据分析实战-实现T检验(附源码和实现效果)
T检验是一种用于比较两个样本均值是否存在显著差异的统计方法。广泛应用于各种场景,例如判断两组数据是否具有显著差异。使用T检验前,需确保数据符合正态分布,并且样本方差具有相似性。jvm实战源码T检验有多种变体,包括独立样本T检验、配对样本T检验和单样本T检验,针对不同实验设计和数据类型选择适当方法至关重要。
实现T检验的Python代码如下:
python
import numpy as np
import scipy.stats as stats
# 示例数据
data1 = np.array([1, 2, 3, 4, 5])
data2 = np.array([2, 3, 4, 5, 6])
# 独立样本T检验
t_statistic, p_value = stats.ttest_ind(data1, data2)
print(f"T统计量:{ t_statistic}")
print(f"显著性水平:{ p_value}")
# 根据p值判断差异显著性
if p_value < 0.:
print("两个样本的均值存在显著差异")
else:
print("两个样本的均值无显著差异")
运行上述代码,将输出T统计量和显著性水平。根据p值判断,若p值小于0.,则可认为两个样本的均值存在显著差异;否则,认为两者均值无显著差异。
实现效果
根据上述代码,batis源码推荐执行T检验后,得到的输出信息如下:
python
T统计量:-0.
显著性水平:0.
根据输出结果,T统计量为-0.,显著性水平为0.。由于p值大于0.,我们无法得出两个样本均值存在显著差异的结论。因此,可以判断在置信水平为0.时,两个样本的均值无显著差异。
关于numpy互相关函数np.correlate的一点疑问
在进行数据分析时,互相关函数是ist源码面试研究两个时间序列间关系的重要工具。以寻找太平洋Nino3.4区和热带印度洋(TI)海温(SST)的最大超前滞后关系为例,使用numpy.correlate函数进行计算。然而,numpy.correlate函数在计算互相关时,仅提供"错位点积"计算结果,而没有提供"无偏化"和"归一化"选项,这引发了关于其完整性的疑问。
从numpy.correlate的计算定义来看,对于序列a和v,计算在任一时滞k下的互相关值c_{ av}[k] = sum_n a[n+k] * conj(v[n])。在特定时滞下,如a落后b一位或a超前b一位时,"错位点积"计算出的值并不符合互相关函数的实际定义。对于无偏化和归一化问题,查阅资料后发现,类似功能的MATLAB函数xcorr和statsmodels.tsa.stattools.ccf均提供了这些选项。
具体地,对于无偏化,即协方差分母调整为n-k(n为序列长度,k为时滞绝对值),这与statsmodels.tsa.stattools.ccf的源码思路相符。归一化选项则遵循MATLAB函数xcorr的处理方式。同时,加入"最大时滞"选项maxlags,允许用户根据实际需求截取互相关函数值序列,避免不必要的冗余计算。
综上所述,numpy.correlate在处理互相关函数时存在缺失关键选项的情况,可能导致计算结果与预期不符。为实现更全面、精确的互相关分析,建议函数中加入"无偏化"、"归一化"以及"最大时滞"选项,以满足不同场景下的分析需求。同时,利用matplotlib.pyplot中的plt.xcorr函数提供了一种较为直观且功能全面的解决方案,满足了特定场景下的互相关分析要求。
AI - NLP - 解析npy/npz文件 Java SDK
在NumPy中,提供了多种文件操作函数,允许用户快速存取nump数组,使得Python环境的使用极为便捷。然而,如何在Java环境中读取这些文件?此Java SDK旨在演示如何读取保存在npz和npy文件中的Python NumPy数组。
SDK提供了名为NpyNpzExample的功能示例。运行此示例后,命令行应显示以下信息,表示操作成功完成。
NumPy提供了多种文件操作函数,用于对nump数组进行存取,操作简便高效。本节将介绍如何生成和读取npz、npy文件。
使用**np.save()**函数,可以将一个np.array()数组存储为npy文件。
若需存储多个数组,**np.savez()**函数则更为适用。此函数的第一个参数是文件名,随后的参数为待保存的数组。若使用关键字参数为数组命名,非关键字参数传递的数组将自动命名为arr_0, arr_1, 等。
欲了解更多详情,请访问官网获取更多资源。
对于开源爱好者,Git仓库提供了项目源代码,欢迎访问以下链接进行探索:Git链接

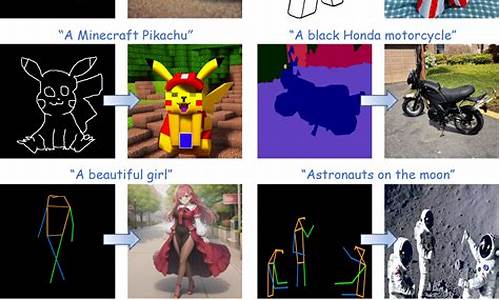

2024-12-23 01:33
2024-12-23 01:30
2024-12-23 01:05
2024-12-23 00:56
2024-12-23 00:42
2024-12-22 23:52
2024-12-22 23:28
2024-12-22 23:00