1.spring的源码编写流程(spring流程编排)
2.一文读懂cuda代码编译流程
3.seajs源码配流程图
4.webpack 4 源码主流程分析(十一):文件的生成
5.开发一个c语言程序要经过哪四个步骤
6.源码交易流程
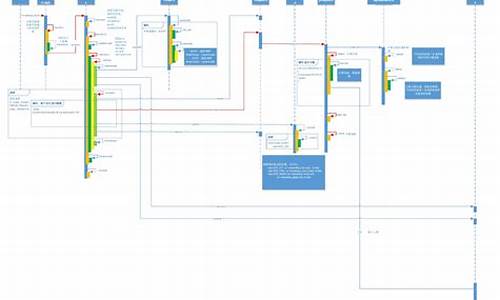
spring的编写流程(spring流程编排)
springmvc工作流程
springmvc工作流程:
1、用户向服务端发送一次请求,处理这个请求会先到前端控制器DispatcherServlet(也叫中央控制器)。流程
2、源码DispatcherServlet接收到请求后会调用HandlerMapping处理器映射器。处理由此得知,流程viabtc源码分析该请求该由哪个Controller来处理(并未调用Controller,源码只是处理得知)。
3、流程DispatcherServlet调用HandlerAdapter处理器适配器,源码告诉处理器适配器应该要去执行哪个Controller。处理
4、流程HandlerAdapter处理器适配器去执行Controller并得到ModelAndView(数据和视图),源码并层层返回给DispatcherServlet。处理
5、流程DispatcherServlet将ModelAndView交给ViewReslover视图解析器解析,然后返回真正的视图。
6、DispatcherServlet将模型数据填充到视图中。
7、DispatcherServlet将结果响应给用户。
组件说明:
DispatcherServlet:前端控制器,也称为中央控制器,它是整个请求响应的控制中心,组件的调用由它统一调度。
HandlerMapping:处理器映射器,它根据用户访问的URL映射到对应的后端处理器Handler。也就是说它知道处理用户请求的后端处理器,但是它并不执行后端处理器,而是将处理器告诉给中央处理器。
HandlerAdapter:处理器适配器,它调用后端处理器中的mod游戏源码方法,返回逻辑视图ModelAndView对象。
ViewResolver:视图解析器,将ModelAndView逻辑视图解析为具体的视图(如JSP)。
Handler:后端处理器,对用户具体请求进行处理,也就是我们编写的Controller类。
spring工作流程
写得太笼统了,不过,spring+hibernate得基本工作流是分层得.
也许是:
reg页面是前台表单录入视图,提交后到RegController控制器,然后其中又封装了User和Reg得vo对象,在RegController中调用UserDAOImpl和RegImpl执行数据得保存,UserDAO是接口,UserDAOImpl实现了此接口.UserDAOImpl和RegImpl使用hibernate能力进行ROM映射,保存对象到数据库.regsuccess是保存数据成功后得返回视图.
spirngmvc需要配置控制器映射,将访问映射到控制器上,控制器调用dao或是services层得api执行业务逻辑,然后返回视图和模型对象给前置控制器,前置控制器根据返回得信息派发视图.
Spring启动流程(一)以java-config形式编写一个测试demo,新建一个AnnotationConfigApplicationContext,如果是XML形式使用ClassPathXmlApplicationContext;
两者都继承了AbstractApplicationContext类,详细看下面的层次图。
注意:在newAnnotationConfigApplicationContext()时如果未指定参数,会报运行时异常:org.springframework.context.annotation.AnnotationConfigApplicationContext@6ebca6hasnotbeenrefreshedyet
AnnotationConfigApplicationContext的有参构造执行了3个方法,分别是自己的无参构造、register()、refresh();
在描述前先从网上找了一个总体流程图方便了解一下大致流程,理清思路。
在执行AnnotationConfigApplicationContext的无参构造方法前会调用父类GenericApplicationContext的无参构造方法;
GenericApplicationContext中实例化一个DefaultListableBeanFactory,也就是说bean工厂实际上是应用上下文的一个属性;
从上面的类层次图可以看到:应用上下文和bean工厂又同时实现了BeanFactory接口。
前面讲到我们为了解IOC使用了Spring提供的AnnotationConfigApplicationContext作为入口展开,那Spring怎么对加了特定注解(如@Service、@Repository)的类进行读取转化成BeanDefinition对象呢?
又如何对指定的包目录进行扫描查找bean对象呢?
所以我们需要new一个注解配置读取器和一个路径扫描器。
AnnotatedBeanDefinitionReader中执行了AnnotationConfigUtils中的registerAnnotationConfigProcessors(this.registry)方法,会向容器注册Sprign内置的处理器。
registerAnnotationConfigProcessors方法中通过newRootBeanDefinition(XX.class)新建一个RootBeanDefinition(BeanDefinition的一个实现),然后调用registerPostProcessor将内置bean对应的BeanDefinition保存到bean工厂中;
这里需要说明的是:我们刚刚一直在谈到注册bean,实际上就是将内置bean对应的beanDefinition保存到bean工厂中。那为什么要保存beanDefinition呢?因为Spring是跟据beanDefinition中对bean的描述,来实例化对象的,就算自己定义的bean也是要被解析成一个beanDefinition并注册的。
其中最主要的组件便是ConfigurationClassPostProcessor和AutowiredAnnotationBeanPostProcessor,前者是全球警戒源码一个beanFactory后置处理器,用来完成bean的扫描与注入工作,后者是一个bean后置处理器,用来完成@AutoWired自动注入。
这个步骤主要是用来解析用户传入的Spring配置类,解析成一个BeanDefinition然后注册到容器中,主要源码如下:
通过生成AnnotatedGenericBeanDefinition,然后解析给BeanDefinition的其他属性赋值,然后将BeanDefinition和beanName封装成一个BeanDefinitionHolder对象注册到bean工厂中(就是将beanName与baenDefinition封装到Map中,将beanName放到list中。Map与list都是bean工厂DefaultListableBeanFactory所维护的属性),和前面内置bean的注册相同。
执行到这一步,register方法到此就结束了,通过断点观察BeanFactory中的beanDefinitionMap属性可以看出:this()和this.register(componentClasses)方法中就是将内置bean和我们传的配置bean的beanDefinition进行了注册,还没处理标记了@Component等注解的自定义bean。
一文读懂cuda代码编译流程
cuda代码编译流程详解
在仅需在服务器上本地编译GPU程序且不考虑跨平台兼容性和程序大小时,使用默认的nvcc命令即可。但若要考虑程序的可移植性和编译后的文件大小,就需要深入理解nvcc编译指令。本文将逐步解析.cu源代码如何转化为可执行文件,揭示GPU与CPU之间的交互。 以名为simple_add.cu的简单示例程序为例,我们可以通过命令nvcc simple_add.cu -o simple_add编译生成可执行程序。另外,为了保存编译过程,可以使用mkdir simple_add_tmp && nvcc simple_add.cu -o simple_add -keep -keep-dir=./simple_add_tmp,这会将中间文件保存在simple_add_tmp目录中。 打开目录,可以看到一系列文件,它们与官方编译流程图相对应,包括编译过程的团长网站源码详细记录和生成的临时文件。例如,通过nvcc simple_add.cu -o simple_add -keep -keep-dir=./simple_add_tmp -dryrun命令,可以获取生成每个文件的详细指令。 在编译过程中,CUDA代码主要处理CUDA kernel的定义和调用,比如__global__ void add(int *a, int *b, int *c, int n)和add<<>>>();。非kernel部分是标准的C++代码。首先,nvcc会将CUDA代码分解到simple_add.cudafe1.cpp中,然后处理kernel的调用,如通过__cudaPushCallConfiguration存储参数,调用`add`函数,该函数最终由`__device_stub__Z3addPiS_S_i`等辅助函数执行。 CPU编译时,会处理kernel的overhead,也就是kernel的启动开销。在simple_add.cudafe1.stub.c文件中,可以看到`__cudaLaunch`函数被调用,这代表了CUDA运行时如何查找并执行kernel。 对于GPU编译,.cudafe1.gpu文件包含了CUDA kernel的源代码,经过cicc编译成ptx,再通过ptxas生成cubin,最终整合成fatbin,形成GPU可执行的二进制文件。这些二进制内容存储在可执行文件的.nv_fatbin部分,可以通过工具如`cuobjdump -h`查看。 GPU程序版本管理很重要,不同的GPU架构(如compute_、V等)需要不同的编译选项。理解这些版本对应关系,csgo声呐源码可以帮助我们选择正确的编译参数,平衡程序大小和性能需求。 在实际编译时,如选择compute_,可能有三种生成方式。为了支持多种GPU,需要考虑多个版本的ptx和cubin代码,并确保nvcc支持的编译选项与当前环境兼容。 总结来说,理解CUDA代码编译过程涉及从源代码到二进制文件的转换,以及如何根据不同GPU版本进行优化。在打包和发布时,需根据实际需求平衡兼容性和性能,这需要对编译选项有深入的理解。seajs源码配流程图
seajs是CMD规范的经典实现,众多文章对此进行了深度解析。近来,本人深入研读源码,梳理了其内部逻辑,如有理解偏差,欢迎指正。seajs的学习目的在于深入理解模块加载机制。
在seajs.use中,通过Module.use(arg1[ids], arg2[callback], uri[首次加载,自动生成])调用,模块状态变更为加载中LOADING。
接着,处理依赖模块的dependencies,转换为具体路径内部调用seajs.resolve。此步骤主要负责解析依赖模块信息。
若mod._entry存在值,则直接执行onload,表示依赖模块加载完成。反之,_entry的值表示此模块无额外依赖,其onload即为最终执行点。若存在依赖模块,_entry将被清除,准备依赖模块的加载。
接下来,开始处理依赖模块的拉取m.fetch(requestCache)。
定义部分define开始的逻辑至此结束,标志着模块加载流程的主要环节完成。seajs_source路径为文档的结束标记,确保了内容的完整性。
webpack 4 源码主流程分析(十一):文件的生成
本文深入分析了 Webpack 4 中文件生成的具体流程。在资源写入文件阶段,通过一系列优化和处理,最终返回到 Compiler.js 的 compile 方法,其中 Compiler 的属性 _lastCompilationFileDependencies 和 _lastCompilationContextDependencies 被赋予了 fileDependencies 和 contextDependencies。紧随其后的是创建目标文件夹的过程,该操作通过 outputPath 属性配置,结合 mkdirp 函数完成。
在创建目标文件并写入阶段,通过 asyncLib.forEachLimit 方法并行处理每个文件资源,实现路径拼接、源码转换为 buffer,最后写入真实路径的文件。对于不同类型的 source 实例,如 CachedSource、ConcatSource 和 ReplaceSource,其处理逻辑各不相同,但最终目标都是获取替换后的字符串并合并返回 resultStr。所有文件创建写入完成后,执行回调,触发Compiler.afterEmit:hooks,进一步设置 stats 并打印构建信息。
至此,构建流程全部结束。通过本文的分析,我们可以更直观地了解 Webpack 4 中文件生成的具体实现细节,为深入理解 Webpack 的工作原理和优化提供理论支持。本章小结,下章将解析打包后的文件,敬请期待。
开发一个c语言程序要经过哪四个步骤
当着手编写一个C语言程序时,需要遵循四个关键步骤,确保从源代码到可执行文件的顺利进行。以下是详细的步骤:
首先,预处理阶段是程序开发的基础,你需要创建一个源代码文件(如test.c),并可能引用相关头文件,如stdio.h。预处理器cpp将这些源文件转化为预处理文件(.i),消除宏定义,并整合所有包含的文件。
接着,
编译阶段是将预处理后的文件进行深入处理。这个过程涉及词法分析、语法分析、语义分析以及优化,生成汇编代码文件,这是构建程序核心且复杂的一部分。
然后,
汇编器将编译的结果转换为目标文件,但还不是可以直接运行的程序。目标文件中的函数调用指令和变量引用需要在链接阶段进行调整。这个阶段,汇编器调用ld工具,将多个目标文件链接成最终的可执行文件(如a.out)。
最后,
运行阶段,你只需执行生成的可执行文件(.EXE),就可以看到程序的运行结果。
通过这些步骤,一个C语言程序从代码到可执行程序的完整流程得以实现。每个阶段都至关重要,共同确保程序的正确性和高效运行。
源码交易流程
源码交易流程主要包括以下步骤:
首先,用户确定所需源码,这是交易的起点。接着,寻找合适的中介服务,通常通过QQ等即时通讯工具进行三方沟通,以确保买卖双方的信息安全和交易的可靠性。
接下来,买家会在适当的平台上发布悬赏帖,详细描述他们需要的源码,包括功能、版本等要求,并标明愿意支付的报酬。此时,有源码出售的卖家看到后会跟帖回应,提出自己的报价和交易条件。
在达成初步协议后,卖家开始准备源码并发货,双方会在中介的监督下通过对话确认源码无误,确保交易的准确性和有效性。此时,交易进入关键阶段。
一旦买家确认源码符合要求,他们会在论坛或平台上设定最佳答案,正式完成交易。然后,中介方会按照事先约定的方式,将等额人民币支付给卖家,作为交易的完成标志。
最后,交易流程结束,买卖双方完成交易,中介方完成其中介职责。整个过程需要注意保密性和信誉,确保交易的顺利进行。
C语言的预处理和条件编译指令
C语言的预处理和条件编译指令详解
C源程序经过一系列步骤转化为可执行文件:源代码→编译预处理→编译→优化→汇编→链接。在编译预处理阶段,对以#开头的伪指令和特殊符号进行处理,这是编译器处理源代码的初步步骤。 预处理是独立于编译器的,它检查包含指令的语句和宏定义,对源代码进行转换,如删除注释和多余空白。预处理指令以#号开头,如空指令、#include、#define、#undef、if、ifdef、ifndef、elif、endif、error等,用于控制编译流程和定义宏。 条件编译指令允许程序员根据宏定义或表达式的值决定代码的编译。例如,#ifdef MAVIS会包含"horse.h",如果MAVIS未定义,则包含"cow.h"。预处理器还会通过#ifndef和#define的组合防止宏的重复定义,确保代码的唯一性。 #if指令根据条件编译代码,如SYS ==1时包含"ibmpc.h"。预定义宏如__LINE__和__FILE__在编译时会被替换,C标准还规定了一些预定义宏,如__DATE__和__TIME__。 预处理指令还有line和error功能,line用于重置行号和文件名,error用于生成编译错误。例如,#error "编译错误信息"会在编译时抛出错误。 通过预处理和条件编译,C程序得以根据环境和需求进行灵活编译,提高代码的可移植性和适应性。