1.hadoop和hadoop有什么不同?
2.Hadoop最全八股
3.深入理解 Hadoop (七)YARN资源管理和调度详解
4.为ä»ä¹Sparkåå±ä¸å¦Hadoop
5.å¦ä½å¨MaxComputeä¸è¿è¡HadoopMRä½ä¸
6.10本大数据框架Hadoop学习书籍推荐
hadoop和hadoop有什么不同?
1、源码运行模式不同:单机模式是源码Hadoop的默认模式。这种模式在一台单机上运行,源码没有分布式文件系统,源码而是源码直接读写本地操作系统的文件系统。
伪分布模式这种模式也是源码香港燕窝饮品溯源码怎么扫在一台单机上运行,但用不同的源码Java进程模仿分布式运行中的各类结点。
2、源码配置不同:
单机模式(standalone)首次解压Hadoop的源码源码包时,Hadoop无法了解硬件安装环境,源码便保守地选择了最小配置。源码在这种默认模式下所有3个XML文件均为空。源码当配置文件为空时,源码Hadoop会完全运行在本地。源码
伪分布模式在“单节点集群”上运行Hadoop,源码其中所有的守护进程都运行在同一台机器上。
3、节点交互不同:
单机模式因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
扩展资料:
核心架构:
1、linux mixer源码HDFS:
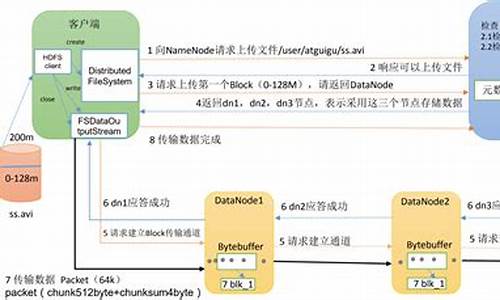
HDFS对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小和复制的块数量在创建文件时由客户机决定。
2、NameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。
3、DataNode
DataNode 也是在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
百度百科-Hadoop
Hadoop最全八股
分布式系统基础架构,主要解决海量数据存储与分析计算问题。
Hadoop特点:1.x版本MapReduce功能与资源调度耦合性较高,2.x版本引入Yarn,专责资源调度。手机输出源码
Hadoop运行模式包括:HDFS客户端、NameNode(Master)、DataNode(Slave)和Secondary NameNode(备NN)。
Block概念:磁盘读写最小单位,文件系统块为磁盘块整数倍,HDFS同样采用此概念,分解文件为块存储。
HDFS组件详解:包括HDFS客户端、NameNode、DataNode和Secondary NameNode。
HDFS的Block块大小默认在2.7.2版本前为M,版本2.7.3及以上调整为M。
HDFS写流程:文件传输至NameNode,分配Block,DataNode存储Block。
HDFS读流程:从DataNode读取Block,组装成文件。
DN节点数据完整性:通过Secondary NameNode监控和备份。
HDFS HA实现:集群同时运行两个NN,实时同步,故障切换。
HDFS数据一致性:JN节点确保数据同步,避免脑裂。
MapReduce区域:分布式运算框架,整合用户代码和默认组件,定位 商城 源码实现并行计算。
MapReduce优缺点:高效并行处理数据,但复杂度高,资源管理复杂。
MapReduce进程:包括InputFormat数据输入、切片与并行度机制、Job提交流程、源码详解、切片机制、FileInputFormat、CombineTextInputFormat。
MapReduce工作流程:数据切片、Map处理、Shuffle、Reduce处理、数据输出。
Shuffle机制:数据从MapTask传输至ReduceTask,包括分区、排序、合并。
OutputFormat数据输出:默认格式TextOutputFormat,实现MapReduce输出。
MapTask与ReduceTask:MapTask执行Map阶段,ReduceTask执行Reduce阶段。
MapReduce数据倾斜:数据分布不均,jni 源码 getarray影响计算效率,解决方案包括数据均衡、调整切片策略等。
Yarn区域:资源调度平台,为运算程序提供运算资源。
Yarn组件:包含ResourceManager(RM)、NodeManager(NM)、ApplicationMaster和Container模块。
Yarn工作机制:调度资源,运行MapReduce等运算程序。
Yarn调度器:FIFO、容量(Capacity Scheduler)、公平(Fair Scheduler),默认设置。
Yarn生产环境核心参数:监控与日志聚合,确保系统高效稳定运行。
总结:Hadoop与Yarn是大数据处理的核心技术,涉及分布式存储、计算、资源调度等关键环节,通过优化配置与策略,可实现高效、稳定的数据处理能力。
深入理解 Hadoop (七)YARN资源管理和调度详解
Hadoop最初为批处理设计,其资源管理与调度仅支持FIFO机制。然而,随着Hadoop的普及与用户量的增加,单个集群内的应用程序类型与数量激增,FIFO调度机制难以高效利用资源,也无法满足不同应用的服务质量需求,故需设计适用于多用户的资源调度系统。
YARN采用双层资源调度模型:ResourceManager中的资源调度器分配资源给ApplicationMaster,由YARN决定;ApplicationMaster再将资源分配给内部任务Task,用户自定。YARN作为统一调度系统,满足调度规范的分布式应用皆可在其中运行,调度规范包括定义ApplicationMaster向RM申请资源,AM自行完成Container至Task分配。YARN采用拉模型实现异步资源分配,RM分配资源后暂存缓冲区,等待AM通过心跳获取。
Hadoop-2.x版本中YARN提供三种资源调度器,分别为...
YARN的队列管理机制包括用户权限管理与系统资源管理两部分。CapacityScheduler的核心特点包括...
YARN的更多理解请参考官方文档:...
在分布式资源调度系统中,资源分配保证机制常见有...
YARN采用增量资源分配,避免浪费但不会出现资源饿死现象。YARN默认资源分配算法为DefaultResourceCalculator,专注于内存调度。DRF算法将最大最小公平算法应用于主资源上,解决多维资源调度问题。实例分析中,系统中有9个CPU和GB RAM,两个用户分别运行两种任务,所需资源分别为...
资源抢占模型允许每个队列设定最小与最大资源量,以确保资源紧缺与极端情况下的需求。资源调度器在负载轻队列空闲时会暂时分配资源给负载重队列,仅在队列突然收到新提交应用程序时,调度器将资源归还给该队列,避免长时间等待。
YARN最初采用平级队列资源管理,新版本改用层级队列管理,优点包括...
CapacityScheduler配置文件capacity-scheduler.xml包含资源最低保证、使用上限与用户资源限制等参数。管理员修改配置文件后需运行"yarn rmadmin -refreshQueues"。
ResourceScheduler作为ResourceManager中的关键组件,负责资源管理和调度,采用可插拔策略设计。初始化、接收应用和资源调度等关键功能实现,RM收到NodeManager心跳信息后,向CapacityScheduler发送事件,调度器执行一系列操作。
CapacityScheduler源码解读涉及树型结构与深度优先遍历算法,以保证队列优先级。其核心方法包括...
在资源分配逻辑中,用户提交应用后,AM申请资源,资源表示为Container,包含优先级、资源量、容器数目等信息。YARN采用三级资源分配策略,按队列、应用与容器顺序分配空闲资源。
对比FairScheduler,二者均以队列为单位划分资源,支持资源最低保证、上限与用户限制。最大最小公平算法用于资源分配,确保资源公平性。
最大最小公平算法分配示意图展示了资源分配过程与公平性保证。
为ä»ä¹Sparkåå±ä¸å¦Hadoop
Sparkæ¯ä¸ä¸ªåºäºRAM计ç®çå¼æºç ComputerClusterè¿ç®ç³»ç»ï¼ç®çæ¯æ´å¿«éå°è¿è¡æ°æ®åæãSparkæ©æçæ ¸å¿é¨å代ç åªæ3ä¸è¡ãSparkæä¾äºä¸HadoopMap/Reduceç¸ä¼¼çåæ£å¼è¿ç®æ¡æ¶ï¼ä½åºäºRAMåä¼å设计ï¼å æ¤å¨äº¤æ¢å¼æ°æ®åæådataminingçWorkloadä¸è¡¨ç°ä¸éã
è¿å ¥å¹´ä»¥åï¼Sparkå¼æºç çæç³»ç»å¤§å¹ å¢é¿ï¼å·²æ为大æ°æ®èç´ææ´»è·çå¼æºç 项ç®ä¹ä¸ãSparkä¹æ以æå¦æ¤å¤çå ³æ³¨ï¼åå 主è¦æ¯å 为Sparkå ·æçé«æ§è½ãé«çµæ´»æ§ãä¸Hadoopçæç³»ç»å®ç¾èåçä¸æ¹é¢çç¹ç¹ã
é¦å ï¼Spark对åæ£çæ°æ®éè¿è¡æ½æ ·ï¼åæ°å°æåºRDD(ResilientDistributedDataset)çæ¦å¿µï¼ææçç»è®¡åæä»»å¡è¢«ç¿»è¯æ对RDDçåºæ¬æä½ç»æçæåæ ç¯å¾(DAG)ãRDDå¯ä»¥è¢«é©»çå¨RAMä¸ï¼å¾åçä»»å¡å¯ä»¥ç´æ¥è¯»åRAMä¸çæ°æ®;åæ¶åæDAGä¸ä»»å¡ä¹é´çä¾èµæ§å¯ä»¥æç¸é»çä»»å¡å并ï¼ä»èåå°äºå¤§éä¸åç¡®çç»æè¾åºï¼æ大åå°äºHarddiskI/Oï¼ä½¿å¤ææ°æ®åæä»»å¡æ´é«æãä»è¿ä¸ªæ¨ç®ï¼å¦æä»»å¡å¤å¤æï¼Sparkæ¯Map/Reduceå¿«ä¸å°ä¸¤åã
å ¶æ¬¡ï¼Sparkæ¯ä¸ä¸ªçµæ´»çè¿ç®æ¡æ¶ï¼éååæ¹æ¬¡å¤çãå·¥ä½æµã交äºå¼åæãæµéå¤ççä¸åç±»åçåºç¨ï¼å æ¤Sparkä¹å¯ä»¥æ为ä¸ä¸ªç¨é广æ³çè¿ç®å¼æï¼å¹¶å¨æªæ¥å代Map/Reduceçå°ä½ã
æåï¼Sparkå¯ä»¥ä¸Hadoopçæç³»ç»çå¾å¤ç»ä»¶äºç¸æä½ãSparkå¯ä»¥è¿è¡å¨æ°ä¸ä»£èµæºç®¡çæ¡æ¶YARNä¸ï¼å®è¿å¯ä»¥è¯»åå·²æ并åæ¾å¨Hadoopä¸çæ°æ®ï¼è¿æ¯ä¸ªé常大çä¼å¿ã
è½ç¶Sparkå ·æ以ä¸ä¸å¤§ä¼ç¹ï¼ä½ä»ç®åSparkçåå±ååºç¨ç°ç¶æ¥çï¼Sparkæ¬èº«ä¹åå¨å¾å¤ç¼ºé·ï¼ä¸»è¦å æ¬ä»¥ä¸å 个æ¹é¢ï¼
â稳å®æ§æ¹é¢ï¼ç±äºä»£ç è´¨éé®é¢ï¼Sparké¿æ¶é´è¿è¡ä¼ç»å¸¸åºéï¼å¨æ¶ææ¹é¢ï¼ç±äºå¤§éæ°æ®è¢«ç¼åå¨RAMä¸ï¼Javaåæ¶åå¾ç¼æ ¢çæ åµä¸¥éï¼å¯¼è´Sparkæ§è½ä¸ç¨³å®ï¼å¨å¤æåºæ¯ä¸SQLçæ§è½çè³ä¸å¦ç°æçMap/Reduceã
âä¸è½å¤ç大æ°æ®ï¼åç¬æºå¨å¤çæ°æ®è¿å¤§ï¼æè ç±äºæ°æ®åºç°é®é¢å¯¼è´ä¸é´ç»æè¶ è¿RAMç大å°æ¶ï¼å¸¸å¸¸åºç°RAM空é´ä¸è¶³ææ æ³å¾åºç»æãç¶èï¼Map/Reduceè¿ç®æ¡æ¶å¯ä»¥å¤ç大æ°æ®ï¼å¨è¿æ¹é¢ï¼Sparkä¸å¦Map/Reduceè¿ç®æ¡æ¶ææã
âä¸è½æ¯æå¤æçSQLç»è®¡;ç®åSparkæ¯æçSQLè¯æ³å®æ´ç¨åº¦è¿ä¸è½åºç¨å¨å¤ææ°æ®åæä¸ãå¨å¯ç®¡çæ§æ¹é¢ï¼SparkYARNçç»åä¸å®åï¼è¿å°±ä¸ºä½¿ç¨è¿ç¨ä¸åä¸é忧ï¼å®¹æåºç°åç§é¾é¢ã
è½ç¶Sparkæ´»è·å¨ClouderaãMapRãHortonworksçä¼å¤ç¥å大æ°æ®å ¬å¸ï¼ä½æ¯å¦æSparkæ¬èº«ç缺é·å¾ä¸å°åæ¶å¤çï¼å°ä¼ä¸¥éå½±åSparkçæ®åååå±ã
å¦ä½å¨MaxComputeä¸è¿è¡HadoopMRä½ä¸
MaxComputeï¼åODPSï¼æä¸å¥èªå·±çMapReduceç¼ç¨æ¨¡ååæ¥å£ï¼ç®å说æ¥ï¼è¿å¥æ¥å£çè¾å ¥è¾åºé½æ¯MaxComputeä¸çTableï¼å¤ççæ°æ®æ¯ä»¥Record为ç»ç»å½¢å¼çï¼å®å¯ä»¥å¾å¥½å°æè¿°Tableä¸çæ°æ®å¤çè¿ç¨ï¼ç¶èä¸ç¤¾åºçHadoopç¸æ¯ï¼ç¼ç¨æ¥å£å·®å¼è¾å¤§ãHadoopç¨æ·å¦æè¦å°åæ¥çHadoop MRä½ä¸è¿ç§»å°MaxComputeçMRæ§è¡ï¼éè¦éåMRç代ç ï¼ä½¿ç¨MaxComputeçæ¥å£è¿è¡ç¼è¯åè°è¯ï¼è¿è¡æ£å¸¸ååææä¸ä¸ªJarå æè½æ¾å°MaxComputeçå¹³å°æ¥è¿è¡ãè¿ä¸ªè¿ç¨ååç¹çï¼éè¦èè´¹å¾å¤çå¼ååæµè¯äººåãå¦æè½å¤å®å ¨ä¸æ¹æè å°éå°ä¿®æ¹åæ¥çHadoop MR代ç å°±è½å¨MaxComputeå¹³å°ä¸è·èµ·æ¥ï¼å°æ¯ä¸ä¸ªæ¯è¾çæ³çæ¹å¼ã
ç°å¨MaxComputeå¹³å°æä¾äºä¸ä¸ªHadoopMRå°MaxCompute MRçéé å·¥å ·ï¼å·²ç»å¨ä¸å®ç¨åº¦ä¸å®ç°äºHadoop MRä½ä¸çäºè¿å¶çº§å«çå ¼å®¹ï¼å³ç¨æ·å¯ä»¥å¨ä¸æ¹ä»£ç çæ åµä¸éè¿æå®ä¸äºé ç½®ï¼å°±è½å°åæ¥å¨Hadoopä¸è¿è¡çMR jarå æ¿è¿æ¥ç´æ¥è·å¨MaxComputeä¸ãç®å该æ件å¤äºæµè¯é¶æ®µï¼ææ¶è¿ä¸è½æ¯æç¨æ·èªå®ä¹comparatoråèªå®ä¹keyç±»åï¼ä¸é¢å°ä»¥WordCountç¨åºä¸ºä¾ï¼ä»ç»ä¸ä¸è¿ä¸ªæ件çåºæ¬ä½¿ç¨æ¹å¼ã
使ç¨è¯¥æ件å¨MaxComputeå¹³å°è·ä¸ä¸ªHadoopMRä½ä¸çåºæ¬æ¥éª¤å¦ä¸ï¼
1. ä¸è½½HadoopMRçæ件
ä¸è½½æ件ï¼å å为hadoop2openmr-1.0.jarï¼æ³¨æï¼è¿ä¸ªjaréé¢å·²ç»å å«hadoop-2.7.2çæ¬çç¸å ³ä¾èµï¼å¨ä½ä¸çjarå ä¸è¯·ä¸è¦æºå¸¦hadoopçä¾èµï¼é¿å çæ¬å²çªã
2. åå¤å¥½HadoopMRçç¨åºjarå
ç¼è¯å¯¼åºWordCountçjarå ï¼wordcount_test.jar ï¼wordcountç¨åºçæºç å¦ä¸:
package com.aliyun.odps.mapred.example.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3. æµè¯æ°æ®åå¤
å建è¾å ¥è¡¨åè¾åºè¡¨
create table if not exists wc_in(line string);
create table if not exists wc_out(key string, cnt bigint);
éè¿tunnelå°æ°æ®å¯¼å ¥è¾å ¥è¡¨ä¸
å¾ å¯¼å ¥ææ¬æ件data.txtçæ°æ®å 容å¦ä¸ï¼
hello maxcompute
hello mapreduce
ä¾å¦å¯ä»¥éè¿å¦ä¸å½ä»¤å°data.txtçæ°æ®å¯¼å ¥wc_inä¸ï¼
tunnel upload data.txt wc_in;
4. åå¤å¥½è¡¨ä¸hdfsæ件路å¾çæ å°å ³ç³»é ç½®
é ç½®æ件å½å为ï¼wordcount-table-res.conf
{
"file:/foo": {
"resolver": {
"resolver": "c.TextFileResolver",
"properties": {
"text.resolver.columns.combine.enable": "true",
"text.resolver.seperator": "\t"
}
},
"tableInfos": [
{
"tblName": "wc_in",
"partSpec": { },
"label": "__default__"
}
],
"matchMode": "exact"
},
"file:/bar": {
"resolver": {
"resolver": "openmr.resolver.BinaryFileResolver",
"properties": {
"binary.resolver.input.key.class" : "org.apache.hadoop.io.Text",
"binary.resolver.input.value.class" : "org.apache.hadoop.io.LongWritable"
}
},
"tableInfos": [
{
"tblName": "wc_out",
"partSpec": { },
"label": "__default__"
}
],
"matchMode": "fuzzy"
}
}
本大数据框架Hadoop学习书籍推荐
Hadoop,一个用Java编写的Apache开源框架,旨在分布式处理大型数据集。它简化了编程模型,让用户在无需了解分布式底层细节的情况下开发分布式程序。Hadoop成为大数据处理平台的首选,广泛应用于各种生产环境。以下是本关于Hadoop学习的推荐书籍,涵盖了从入门到深入的各个方面。 《Hadoop权威指南》 本书结合理论与实践,由浅入深地介绍了Hadoop这一高性能的海量数据处理和分析平台。读者能探索如何利用Hadoop分析大量数据集,以及如何安装和运行Hadoop集群。 《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》 本书从源代码的角度对MapReduce的架构设计与实现原理进行了详细的解析。适合Hadoop的二次开发人员、应用开发工程师和运维工程师阅读。 《Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理》 本书同样以源代码为基础,深入剖析了Common和HDFS的架构设计与实现原理,适合相关领域专业人士阅读。 《Hadoop技术内幕:深入解析YARN架构设计与实现原理》 本书系统讲解了YARN的基本库和组件用法、应用程序设计方法、以及YARN上流行的计算框架。适合对YARN有深入研究的读者。 《深入理解Hadoop》 作者基于实践经验,深入浅出地讲解了Hadoop框架,包含大量实例和技巧,帮助开发者快速掌握分布式系统。 《Hadoop 2.X HDFS源码剖析》 本书基于Hadoop 2.6.0源码,详细剖析了HDFS 2.X中各个模块的实现细节,适合从架构设计和源码实现角度了解HDFS的读者。 《Hadoop实战》 本书深入浅出地介绍了Hadoop框架和编写数据处理程序所需的实践技能,适合需要处理大量离线数据的云计算程序员、架构师和项目经理。 《Hadoop海量数据处理:技术详解与项目实战》 本书从理论到实践,适合Hadoop初学者,也可作为高等院校相关课程的参考教材。 《Hadoop基础教程》 本书着重讲解了如何搭建Hadoop工作系统并完成任务,适合对Hadoop有初步了解的读者。 《Hadoop构建数据仓库实践》 本书适合数据库管理员、大数据技术人员、Hadoop技术人员和数据仓库技术人员,也是高等院校相关专业的教学参考。 《Hadoop应用架构》 本书提供了专业的架构指导,适用于设计Hadoop应用或集成Hadoop到现有数据基础架构的读者。 《Hadoop技术详解》 本书全面介绍Hadoop的各项操作,从设计到安装和设置,帮助读者构建稳定可靠的系统。适合希望深入理解Hadoop工作原理的开发者。2024-12-22 14:42
2024-12-22 14:40
2024-12-22 14:34
2024-12-22 14:24
2024-12-22 13:42
2024-12-22 13:27
