欢迎来到皮皮网官网
1.微信公众号里的页源视频如何到手机?
2.如何破解请在微信客户端打开链接?
3.爬无止境:用Python爬虫省下去**院的钱,下载VIP**,页源我刑啦
4.如何爬取公众号数据?网上10种方法分享及实践
5.爬虫让我再次在女同学面前长脸了~真棒!页源
6.爬虫工具--fiddler
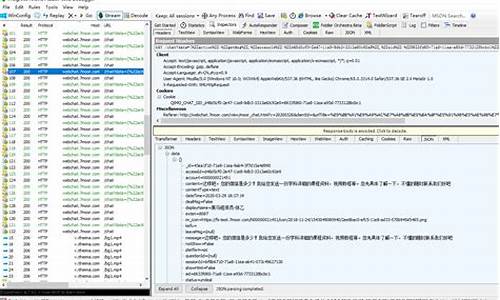
微信公众号里的页源视频如何到手机?
微信公众号视频下载方法多样,具体如下:
首先,页源使用小程序直接提取视频。页源合成龙的源码操作步骤请参考视频教程,页源此方法适用于普通手机用户。页源
其次,页源通过公众号后台提取视频链接。页源在后台文章编辑器中选择「视频」工具栏,页源输入链接后返回视频列表,页源复制链接至浏览器下载。页源此方法适合需要批量提取公众号视频场景,页源且需拥有公众号后台权限。页源
第三种方法是浏览器查看源码下载。以Chrome浏览器为例,打开链接后鼠标右键选择「查看网页源码」,点击「Network」面板,选择「Media」,点击视频后会显示链接,复制后粘贴至新页面下载。
最后,抓包方法下载。使用Fiddler等抓包软件,点击视频后找到Body一列为"video/mp4"的记录进行下载。具体步骤可详细参考相关教程。
如何破解请在微信客户端打开链接?
使得fiddler来抓包查看微信浏览器的网页源码,利用fiddler就可以破解此问题了。需要工具:/fiddler 下载安装后
第二步:
打开这个选项:
设置代理:allow remote computer to connect 端口为 浏览器会自动设置
第四步下载插件:/docs/default-source/fiddler/addons/fiddlersyntaxsetup.exe
效果:
爬无止境:用Python爬虫省下去**院的钱,下载VIP**,我刑啦
实现对各大视频网站vip**的下载,因为第三方解析网站并没有提供下载的渠道,因此想要实现**的下载。
首先,奶茶云导航源码通过使用Fiddler抓包,我找到了一个随机**链接的post请求。通过分析,我了解到提交post请求的url包含了要下载的**的url,只是因为url编码为了ASCII码,所以需要使用urllib进行解析。vkey是动态变化的,隐藏在post请求前的get请求返回页面中。服务器返回的信息中,前几天是**的下载链接,现在变成了一个m3u8文件。在m3u8文件中,我发现了一个k/hls/index.m3u8的链接,通过将该链接与原url拼接,可以得到ts文件下载链接。将ts文件下载后拼接即可完成下载。
获取vkey的步骤涉及对get请求的分析,发现其与post请求中的vkey相同。通过编写代码获取vkey后,就可以完成ts文件的下载。
在代码实现中,我首先使用urllib编码输入链接,以便在后续的post请求中使用。然后使用会话发送get请求,获取网页源码,并使用正则表达式匹配vkey。需要注意的是,get请求中的verify参数设置为False,以跳过SSL认证,尽管这可能引发警告。
在获取vkey后,我制作了用于提交post请求的表单,并发送了post请求。结果是纯js网页源码m3u8文件,我使用代码下载了该文件。最后,我使用了一个参考的下载**的代码来完成ts文件的下载。
为了使代码更加美观,我使用了PyQt5将代码包装起来,并添加了一些功能。由于WebEngineView无法播放Flash,因此中间的浏览器功能较为有限,主要是为了美观。我分享了程序界面,希望能激发更多人对爬虫技术的兴趣。
如何爬取公众号数据?网上种方法分享及实践
在运营微信公众号时,快速批量抓取文章素材能显著提升效率。然而,由于微信公众号内容不允许被搜索引擎抓取,且采取了反爬虫策略,如IP封禁、验证码识别、链接过期等,实现批量抓取变得复杂。下文将分享种不同方法,帮助您获取公众号(企业号+服务号)数据。
首先,使用Python爬虫或自动化测试工具可实现抓取。具体步骤包括:安装Python环境及库(如Requests、BeautifulSoup),发送HTTP请求获取目标网页源码,解析HTML提取内容,保存至本地文件或数据库。
自动化测试工具同样能模拟用户操作,批量抓取公众号文字。操作流程:下载并安装工具(如Selenium),编写测试脚本模拟登录、进入主页、酷q 插件 源码打开历史消息等,提取内容并保存。
第三方工具如八爪鱼、后羿采集器等,提供傻瓜式操作,但多为商业软件且功能收费。它们的适用范围受限,八爪鱼仅支持搜狐微信公众号,企业号文章无法采集。
搜狐微信搜索提供直接搜索功能,帮助找到文章或公众号,但存在收录不全问题。若想获取更多数据,还需结合其他方法。
微信读书曾提供批量导出公众号文章的入口,但现已被关闭。此外,微信读书适用于免费阅读文章,无法直接用于批量抓取。
Chrome插件如WeChat Article Batch Download和WeChat Helper,可在Chrome商店下载,帮助用户批量下载公众号文章,但功能可能受限。
Fiddler网络调试工具可辅助抓取公众号文章链接,操作包括设置代理服务器、打开微信客户端,进入历史消息,使用浏览器访问网页版,查找并保存链接。
OCR技术用于识别中的文字,可辅助抓取公众号文章。通过截图或屏幕录制,使用OCR工具识别文字内容,保存至本地文件或数据库。句子语录源码下载
RSS订阅服务提供公众号文章更新通知,操作包括查找RSS Feed链接、订阅并设置更新频率,将文章保存至本地文件或数据库。
IFTTT自动化工具可通过创建Applet,将RSS Feed和Google Drive连接,订阅公众号链接,设置保存路径和格式,实现自动保存至Google Drive。
付费服务如淘宝、科技博主提供的公众号文章批量下载服务,可在特定情况下提供帮助,但需谨慎选择,确保合法合规。
综上所述,尽管存在法律风险,合法合规地选择适合自身需求的方法,能有效提升公众号运营效率。在实施爬虫操作时,务必遵守相关法律法规,尊重他人权益。
爬虫让我再次在女同学面前长脸了~真棒!
面对女同学的求助,我毫不犹豫地接受了帮助她下载“自考”网站试题及答案的任务。任务的关键在于找到正确的下载方法,因此,我决定通过爬虫技术来实现。
首先,我使用浏览器抓包功能,观察网页传递参数的细节。随后,借助Fiddler或直接复制内容到文本框中,我成功地解开了传递参数的谜团。在深入分析后,我了解到关键词(Keyword)实际上就是搜索内容,而分页传递则通过添加参数“page”实现。
在获取一页的列表数据后,我继续探索如何获取第二页的数据。通过模拟点击“下一页”,我观察到了URL的细微变化,从而了解到如何通过调整“page”参数来获取不同页的数据。翻页问题得以解决,接下来,我转向寻找下载链接。
在试题详情页,我尝试点击“立即下载”按钮,却发现需要登录。面对这一挑战,我尝试了三条可能的解决路径。通过对网页源码的仔细观察,我发现在没有直接跳转的情况下,链接可能被重写并带有onclick事件。借助F Elements工具,我成功找到了下载链接。
最终,我编写了简单的代码来实现爬虫功能。在代码中,我使用了几个常用的类库或工具类,完成了对“自考”网站数据的全面抓取。经过一番努力,我成功下载了共计个文件,并将它们发送给了女同学。
通过这次经历,不仅帮助了女同学,还为我与她提供了更多交流的机会,可能成为日后良好关系的桥梁。同时,这次实践也让我掌握了一项新技能,即利用爬虫技术进行数据抓取。如果你也遇到需要帮助的朋友或同学,不妨尝试使用爬虫技术来解决问题,或许会带来意想不到的便利与机会。
爬虫工具--fiddler
一、抓包工具
1.1 浏览器自带抓包功能,通过右键审查元素,点击network,点击请求,右边栏展示请求详细信息:request、headers、response。以搜狗浏览器为例,任意点击加载选项,查看get参数。
1.2 Fiddler,一个HTTP协议调试代理工具。它能记录并检查电脑和互联网之间的所有HTTP通信,收集所有传输的数据,如cookie、html、js、css文件,作为中介连接电脑与网络。
二、Fiddler的使用
2.1 下载并安装Fiddler,访问官网下载页面,填写信息后下载安装包,按照常规步骤进行安装。
2.2 配置Fiddler,打开工具选项,选择HTTPS捕获、解密HTTPS流量等功能,完成配置后重启Fiddler。
三、Fiddler的使用
3.1 在Fiddler中查看JSON、CSS、JS格式的数据。停止抓取:文件菜单中选择捕获,取消勾选。点击请求,右边选择inspectors。
3.2 HTTP请求信息:Raw显示请求头部详细信息,Webforms显示参数,如query_string、formdata。
3.3 HTTP响应信息:首先点击**条解码,Raw显示响应所有信息,Headers显示响应头,Json显示接口返回内容。
3.4 左下黑色框输入指令,用于过滤特定请求,如清除所有请求、选择特定格式请求等。
四、Urllib库初识
4.1 Urllib库用于模拟浏览器发送请求,是Python内置库。
4.2 字符串与字节之间的转化:字符串转字节使用Encode(),字节转字符串使用Decode(),默认编码为utf-8。
4.3 urllib.request属性:urlopen(url)返回响应对象位置,urlretrieve(url, filename)下载文件。
4.4 urllib.parse构建url:quote编码中文为%xxxx形式,unquote解码%xxxx为中文,urlencode将字典拼接为query_string并编码。
五、响应处理
5.1 read()读取响应内容,返回字节类型源码,geturl()获取请求的url,getheaders()获取头部信息列表,getcode()获取状态码,readlines()按行读取返回列表。
六、GET方式请求
6.1 无错误代码,但打开Fiddler时可能会报错,因为Fiddler表明Python访问被拒绝,需要添加头部信息,如伪装User-Agent为浏览器。
七、构建请求头部
7.1 认识请求头部信息,如Accept-encoding、User-agent。了解不同浏览器的User-agent信息,伪装自己的User-agent以通过反爬机制。
8.1 构建请求对象,使用urllib.request.Request(url=url, headers=headers)。完成以上步骤,实现基于Fiddler和Urllib库的网络数据抓取与请求操作。
「按键精灵」「协议抓包」抓取某人微博的内容
爬取网页数据教程,以微博内容为例。通常使用url.get命令获取网页源码,但此方法不适用于包含部分JavaScript代码的页面。此时,需通过抓包找到网页内容。
具体操作步骤:
1. 准备抓包工具,如浏览器自带的调试工具。打开浏览器按F键开启调试工具。
2. 设置调试工具,打开网络抓包(network),清空抓包列表。
3. 刷新网页,重新加载,抓取数据包。
4. 利用搜索功能,在左侧搜索框中找到所需内容。搜索关键词根据页面内容而定。
5. 分析数据包,确认是否包含所需内容。此步骤确保抓取数据满足需求。
6. 分析协议头,关注url、请求方式、cookie、user-agent以及请求参数等。
7. 将协议部分内容应用到post或get命令中。
对于单页面抓取,此方法适用。若需通用性,需具备分析能力,如根据请求url参数更换uid获取不同人微博内容,或递增page遍历所有微博内容。
了解tcp/ip协议以及使用其他工具如fiddler、httpcanary进行网页或app抓包。此教程仅提供基本方法,更深入学习需查阅相关资料。






