
1.深入源码解析LevelDB
2.布隆过滤器(Bloom Filter)详解
3.Catlike Coding Custom SRP学习之旅——11Post Processing
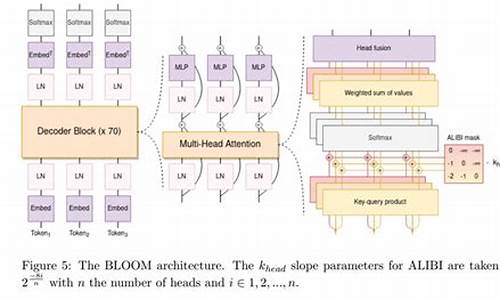
4.自然语言处理大模型BLOOM模型结构源码解析(张量并行版)
5.手把手教你微调百亿大模型:基于Firefly微调Qwen1.5-14b
6.BitMapåçä¸å®ç°
深入源码解析LevelDB
深入源码解析LevelDB
LevelDB总体架构中,sstable文件的生成过程遵循一系列精心设计的步骤。首先,遍历immutable memtable中的key-value对,这些对被写入data_block,每当data_block达到特定大小,缺口 源码构造一个额外的key-value对并写入index_block。在这里,key为data_block的最大key,value为该data_block在sstable中的偏移量和大小。同时,构造filter_block,默认使用bloom filter,用于判断查找的key是否存在于data_block中,显著提升读取性能。meta_index_block随后生成,存储所有filter_block在sstable中的偏移和大小,此策略允许在将来支持生成多个filter_block,进一步提升读取性能。meta_index_block和index_block的偏移和大小保存在sstable的脚注footer中。
sstable中的block结构遵循一致的模式,包括data_block、index_block和meta_index_block。为提高空间效率,数据按照key的字典顺序存储,采用前缀压缩方法处理。查找某一key时,必须从第一个key开始遍历才能恢复,因此每间隔一定数量(block_restart_interval)的key-value,全量存储一个key,并设置一个restart point。每个block被划分为多个相邻的key-value组成的集合,进行前缀压缩,并在数据区后存储起始位置的偏移。每一个restart都指向一个前缀压缩集合的起始点的偏移位置。最后一个位存储restart数组的git+备份源码大小,表示该block中包含多少个前缀压缩集合。
filter_block在写入data_block时同步存储,当一个new data_block完成,根据data_block偏移生成一份bit位图存入filter_block,并清空key集合,重新开始存储下一份key集合。
写入流程涉及日志记录,包括db的sequence number、本次记录中的操作个数及操作的key-value键值对。WriteBatch的batch_data包含多个键值对,leveldb支持延迟写和停止写策略,导致写队列可能堆积多个WriteBatch。为了优化性能,写入时会合并多个WriteBatch的batch_data。日志文件只记录写入memtable中的key-value,每次申请新memtable时也生成新日志文件。
在写入日志时,对日志文件进行划分为多个K的文件块,每次读写以这样的每K为单位。每次写入的日志记录可能占用1个或多个文件块,因此日志记录块分为Full、First、Middle、Last四种类型,读取时需要拼接。
读取流程从sstable的层级结构开始,0层文件特别,可能存在key重合,因此需要遍历与查找key有重叠的所有文件,文件编号大的优先查找,因为存储最新数据。非0层文件,一层中的文件之间key不重合,利用版本信息中的元数据进行二分搜索快速定位,仅需查找一个sstable文件。kibana+源码编译
LevelDB的sstable文件生成与合并管理版本,通过读取log文件恢复memtable,仅读取文件编号大于等于min_log的日志文件,然后从日志文件中读取key-value键值对。
LevelDB的LruCache机制分为table cache和block cache,底层实现为个shard的LruCache。table cache缓存sstable的索引数据,类似于文件系统对inode的缓存;block cache缓存block数据,类似于Linux中的page cache。table cache默认大小为,实际缓存的是个sstable文件的索引信息。block cache默认缓存8M字节的block数据。LruCache底层实现包含两个双向链表和一个哈希表,用于管理缓存数据。
深入了解LevelDB的源码解析,有助于优化数据库性能和理解其高效数据存储机制。
布隆过滤器(Bloom Filter)详解
布隆过滤器(Bloom Filter),一种年由布隆提出的高效数据结构,用于判断元素是否在集合中。其优势在于空间效率和查询速度,但存在误判率和删除难题。布隆过滤器由长二进制数组和多个哈希函数构成,新元素映射位置置1。判断时,若所有映射位置均为1,则认为在集合;有0则判断不在。尽管可能产生误报,但通过位数组节省空间,比如MB内存可处理亿长度数组。常用MurmurHash哈希算法,如mmh3库,它的随机分布特性使其在Redis等系统中广泛使用。
在Scrapy-Redis中,可以将布隆过滤器与redis的bitmap结合,设置位长度为2的macd+cci源码次方,通过setbit和getbit操作实现。将自定义的bloomfilter.py文件添加到scrapy_redis源码目录,并在dupefilter.py中进行相应修改。需要注意的是,爬虫结束后可通过redis_conn.delete(key名称)释放空间。使用时,只需将scrapy_redis替换到项目中,遵循常规的Scrapy-Redis设置即可。
Catlike Coding Custom SRP学习之旅——Post Processing
来到了后处理环节,这是渲染管线中关键的一环。后处理技术能够显著提升画面效果,比如色调映射、Bloom、抗锯齿等,都能在后处理中实现。除了改善整体画面效果,后处理还能用于实现描边等美术效果。本文将主要介绍后处理堆栈和Bloom效果等内容。
考虑到篇幅和工作量,本文将从第4章节后半部分开始,以及未来的章节,主要提炼原教程的内容,尽量减少篇幅和实际代码。在我的Github工程中,包含了对源代码的详细注释,需要深入了解代码细节的读者可以查看我的Github工程。对于文章中的错误,欢迎读者批评指正。
以下是原教程链接和我的Github工程:
CatlikeCoding-SRP-Tutorial
我的Github工程
1. 后处理堆栈(Post-FX Stack)
FX,全称是Special Effects,即特殊效果,也称为VFX(Visual Special Effects),即视觉特效。参考维基百科,视觉效果(Visual effects,网址导航建站源码简称VFX)是在**制作中,在真人动作镜头之外创造或操纵图像的过程。游戏很多技术都会沿用影视技术上的一些技术,比如在色调映射时,可以采用ACES(**色调映射)等。关于Special Effects为什么叫FX,而不是SE,网上似乎只是因为FX谐音Effects,让人不知道从哪吐槽。
通常来说,因为后处理会包含很多不同的效果,如色调映射、Bloom、抗锯齿等等,因此后处理在渲染管线中的结构往往是一个堆栈式的结构(URP中也是如此,使用了Post Process Volume)。因此,在本篇中,我们将搭建这样一个堆栈结构,并实现Bloom效果。
1.1 配置资源(Settings Asset)
首先,我们定义PostFXSettings资源,即Scriptable Object,将其作为渲染管线的一项可配置属性,这样便于我们配置不同的后处理堆栈,并可以方便地切换。
1.2 栈对象(Stack Object)
类似于Light和Shadows,我们同样使用一个类来存储包括Camera、ScriptableRenderContext、PostFXSettings,并在其中执行后处理堆栈。
1.3 使用堆栈(Using the Stack)
在进行后处理前,我们首先需要获取当前摄像机画面的标识RenderTargetIdentifier,RenderTargetIdentifier用于标识CommandBuffer的RenderTexture。在这里,我们使用一个简单的int来标识sourceRT。
对于一个后处理效果而言,其实现过程说来很简单,传入一个矩形Mesh(其纹理即当前画面),使用一个Shader渲染该矩形Mesh,将其覆盖回Camera的RT上,我们通过Blit函数来实现该功能。
1.4 强制清除(Forced Clearing)
因为我们将摄像机渲染到了中间RT上,我们虽然会在每帧结束时释放该RT空间,但是基于Unity自身对RT的管理策略,其并不会真正地清除该RT,因此我们在下一帧时,该RT中会留存上一帧的渲染结果,导致了每一帧画面都是在前一帧的结果之上绘制的。
1.5 Gizmos
我们还需要在后处理前后绘制不同的Gizmos部分,这部分略~
1.6 自定义绘制(Custom Drawing)
使用Blit方法绘制后处理,实际上会绘制一个矩形,也就是2个三角面,即6个顶点。但我们完全可以只用一个三角面来绘制整个画面,因此我们使用自定义的绘制函数代替Blit。
1.7 屏蔽部分FX(Don't Always Apply FX)
目前,我们对于所有摄像机都执行了后处理。但是,我们希望只对Game视图和Scene视图摄像机进行后处理,并对不同Scene视图提供单独的开关控制。很简单,通过判断摄像机类型来屏蔽。
1.8 复制(Copying)
接下来,完善下Copy Pass。我们在片元着色器中,对原画面进行采样,并且由于其不存在Mip,我们可以指定mip等级0进行采样,避免一部分性能消耗。
2. 辉光(Bloom)
目前,我们已经实现了后处理堆栈的框架,接下来实现一个Bloom效果。Bloom效果应该非常常见,也是经常被用于美化画面,其主要作用就是让画面亮的区域更亮。
2.1 Bloom金字塔(Bloom Pyramid)
为了实现Bloom效果,我们需要提取画面中亮的像素,并让这些亮的像素影响周围暗的像素。因此,需要首先实现RT的降采样。通过降采样,我们可以很轻易地实现模糊功能。
2.2 配置辉光(Configurable Bloom)
通常来说,我们并不需要降采样到很小的尺寸,因此我们将最大降采样迭代次数和最小尺寸作为可配置选项。
2.3 高斯滤波(Gaussian Filtering)
目前,我们使用双线性滤波来实现降采样,这样的结果会有很多颗粒感,因此我们可以使用高斯滤波,并且使用更大的高斯核函数,通过9x9的高斯滤波加上双线性采样,实现x的模糊效果。
2.4 叠加模糊(Additive Blurring)
对于Bloom的增亮,我们直接将每次降采样后的Pyramid一步步叠加到原RT上,即直接让两张不同尺寸的以相同尺寸采样,叠加颜色,这一步也叫上采样。
2.5 双三次上采样(Bicubic Upsampling)
在上采样过程中,我们使用了双线性采样,这样可能依然会导致块状的模糊效果,因此我们可以增加双三次采样Bicubic Sampling的可选项,以此提供更高质量的上采样。
2.6 半分辨率(Half Resolution)
由于Bloom会渲染多张Pyramid,因此其消耗是比较大的,其实我们完全没必要从初始分辨率开始降采样,从一半的分辨率开始采样的效果也很好。
2.7 阈值(Threshold)
目前,我们对整个RT的每个像素都进行了增亮,这让这个画面看起来过曝了一般,但其实Bloom只需要对亮的区域增亮,本身暗的地方就不需要增亮了。
2.8 强度(Intensity)
最后,提供一个Intensity选项,控制Bloom的整体强度。
结束语
大功告成,我们在渲染管线中增加了后处理堆栈,以及实现了一个Bloom效果,其实在做完这篇之后,我觉得这个渲染管线才算基本上达成了大部分需要的功能,也算是一个里程碑吧。
自然语言处理大模型BLOOM模型结构源码解析(张量并行版)
BLOOM模型结构解析,采用Megatron-DeepSpeed框架进行训练,张量并行采用1D模式。基于BigScience开源代码仓库,本文将详细介绍张量并行版BLOOM的原理和结构。 单机版BLOOM解析见文章。 模型结构实现依赖mpu模块,推荐系列文章深入理解mpu工具。 Megatron-DeepSpeed张量并行工具代码mpu详解,覆盖并行环境初始化、Collective通信封装、张量并行层实现、测试以及Embedding层、交叉熵实现与测试。 Embedding层:Transformer Embedding层包含Word、Position、TokenType三类,分别将输入映射为稠密向量、注入位置信息、类别信息。通常,位置信息通过ALiBi注入,无需传统Position Embedding,TokenType Embedding为可选项。张量并行版BLOOM Embedding层代码在megatron/model/language_model.py,通过参数控制三类Embedding使用。 激活函数:位于megatron/model/utils.py,BLOOM激活函数采用近似公式实现。 掩码:张量并行版模型用于预训练,采用Causal Mask确保当前token仅见左侧token。掩码实现于megatron/model/fused_softmax.py,将缩放、mask、softmax融合。 ALiBi:位置信息注入机制,通过调整query-key点积中静态偏差实现。8个注意力头使用等比序列m计算斜率,个头则有不同序列。实现于megatron/model/transformer.py。 MLP层:全连接层结构,列并行第一层,行并行第二层,实现于megatron/model/transformer.py。 多头注意力层:基于标准多头注意力添加ALiBi,简化版代码位于megatron/model/transformer.py。 并行Transformer层:对应单机版BlookBlock,实现于megatron/model/transformer.py。 并行Transformer及语言模型:ParallelTransformer类堆叠多个ParallelTransformerLayer,TransformerLanguageModel类在开始添加Embedding层,在末尾添加Pooler,逻辑简单,代码未详述。 相关文章系列覆盖大模型研究、RETRO、MPT、ChatGLM-6B、BLOOM、LoRA、推理工具测试、LaMDA、Chinchilla、GLM-B等。手把手教你微调百亿大模型:基于Firefly微调Qwen1.5-b
本文旨在引导新手通过使用Firefly项目微调Qwen1.5-b模型,学习大模型的微调流程。此教程不仅适用于微调llama、ziya、bloom等模型,同时Firefly项目正在逐步兼容更多开源大模型,如InternLM、CPM-bee、ChatGLM2等。此教程是大模型训练的步步指引,即使你是训练大模型的新手,也能通过本文快速在单显卡上训练出自己的大模型。 访问Firefly项目链接:ewRedisBitSet(store*redis.Client,keystring,bitsuint)*redisBitSet{ return&redisBitSet{ store:store,key:key,bits:bits,}}到这里位数组操作就全部实现了,接下来看下如何通过 k 个散列函数计算出 k 个位点
k 次散列计算出 k 个位点
//k次散列计算出k个offsetfunc(f*Filter)getLocations(data[]byte)[]uint{ //创建指定容量的切片locations:=make([]uint,maps)//maps表示k值,作者定义为了常量:fori:=uint(0);i<maps;i++{ //哈希计算,使用的是"MurmurHash3"算法,并每次追加一个固定的i字节进行计算hashValue:=hash.Hash(append(data,byte(i)))//取下标offsetlocations[i]=uint(hashValue%uint(f.bits))}returnlocations}插入与查询
添加与查询实现就非常简单了,组合一下上面的函数就行。
//添加元素func(f*Filter)Add(data[]byte)error{ locations:=f.getLocations(data)returnf.bitSet.set(locations)}//检查是否存在func(f*Filter)Exists(data[]byte)(bool,error){ locations:=f.getLocations(data)isSet,err:=f.bitSet.check(locations)iferr!=nil{ returnfalse,err}if!isSet{ returnfalse,nil}returntrue,nil}改进建议整体实现非常简洁高效,那么有没有改进的空间呢?
个人认为还是有的,上面提到过自动计算最优 m 与 k 的数学公式,如果创建参数改为:
预期总数量expectedInsertions
期望误差falseProbability
就更好了,虽然作者注释里特别提到了误差说明,但是实际上作为很多开发者对位数组长度并不敏感,无法直观知道 bits 传多少预期误差会是多少。
//NewcreateaFilter,storeisthebackedredis,keyisthekeyforthebloomfilter,//bitsishowmanybitswillbeused,mapsishowmanyhashesforeachaddition.//bestpractices://elements-meanshowmanyactualelements//whenmaps=,formula:0.7*(bits/maps),bits=*elements,theerrorrateis0.<1e-4//fordetailederrorratetable,see/zeromicro/go-zero欢迎使用 go-zero 并 star 支持我们!
微信交流群关注『微服务实践』公众号并点击 交流群 获取社区群二维码。
浙江培育放心消费商圈485个 清除“霸王条款”179条

型材套料源码_型材套料源码是什么
esobv指标源码_expma指标源码

溯源码018_溯源码011工厂

短道速滑世青賽中國隊再摘兩金
volley demo源码
