欢迎来到皮皮网官网
1.2Bå2C产åçåºå«
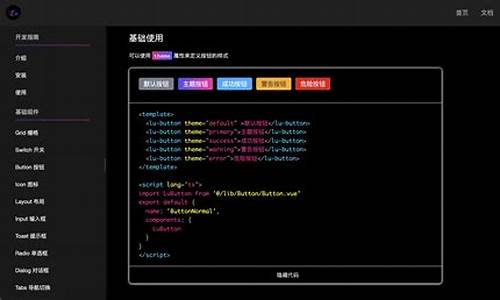
2.文华财经软件指标公式赢顺云指标公式启航DK捕猎者智能量化系统指标源码
3.量化平台大盘点,化源化小白收藏!码量
4.通达信量化擒龙先手!源码主附图/选股指标源码分享
5.开源大模型GGUF量化(llama.cpp)与本地部署运行(ollama)教程

2Bå2C产åçåºå«
ä¸ãå®ä¹
2B=To Business é¢åä¼ä¸å®¢æ·ç产åï¼
2C=To Consumer é¢åç¨æ·ä¸ªäººç产åï¼
äºãç¸åç¹
2ç§ç±»ååå±äºäº§åï¼é½éè¦è½å¤æ»¡è¶³äººä»¬æç§éæ±ï¼ä»éæ±è°ç ãçå设计å°æ¨å¹¿è¿è¥æ¯ä¸ªç¯èé½ä¸å¯ç¼ºå°ï¼ç®åæ¥è¯´ï¼äº§å该æçç¹ç¹é½ä¼æï¼å¿ å¤çç¯èé½ä¼ç»åï¼åªæ¯ä¾§éç¹ä¸åã
ä¸ï¼ä¸åç¹
导è´ä¸åçæ¬è´¨åå æ¯é¢åç群ä½ä¸åãå ¶ä»ææä¸åç¹çå è¿ä¸¤ç§ç¾¤ä½å¨äº§åä¸åç¯èä¸è¡¨ç°åºçç¹ç¹ä¸åèé æçã
2B产å主è¦è¢«ç¨äºèªå·±æå±çå¢é/å ¬å¸ç»ç»ï¼ä½¿ç¨è 并ä¸æ¯å 为å欢æç¨ï¼èæ¯å 为ä»çå·¥ä½ä¸å¾ä¸ç¨ï¼æè å¯ä»¥ä½¿ä»çå·¥ä½æçæ´é«ãæ¯å¦äººè¸æ ¸èº«ä¸å¡ï¼å®¢æ·é常æ¯é¶è¡ãæ¿åºãæºåºçã
å æ¤å¯¹äº2B产åèè¨ãâ让ä¸å¡æ´æµç çè¿è¡âæ¯å ¶æéè¦çç®æ ãæ以åè½ã交äºä¼å 满足å¯ç¨é«æä¹åï¼æä¼èèé¦ä¸æ·»è±çæ¯å¦å¥½çæç¨ä»¥åæä½äººæ§çä½éªã
对äº2B产åPMæ¥è¯´ï¼æä¸å¡é»è¾ï¼æ´æç°æä¸å¡çé®é¢åæææµç¨å¦ä½ä¼åæ¯åèçå ³é®ãä½æ¯2B产åPMå¾å¾ä¸æ¯äº§åç使ç¨è ï¼æ以éè¦è±æ´å¤çç²¾åäºè§£ä¸å¡æµç¨ï¼åæä¸å¡ä¸ä¸æ¸¸ä¹é´çä¾èµå ³ç³»ï¼ä¸å¡åºæ¯ãè¿ä¹ä¸å 为常常æ¶åè·¨é¨é¨ï¼è·¨ä¸å¡çæéï¼æ以2B产ååæçè§ååå¾ååå°é¾ãç åå¨æä¹ç¸å¯¹è¾é¿ã
æ¤å¤ï¼2B产å主è¦æ¯æ¯æä¸å¡ï¼ä¸å¯è½ä» æ¶åå®æ´ä¸å¡ä¸çä¸ä¸ªç¯èï¼çè³åªæ¯è¿ä¸ªç¯èçæå¡äº§åãæ以å¾é¾ç¨æ¸ æ°çæ°åéå产åçä»·å¼ï¼æ产æ¯ï¼æåæçï¼èç人åï¼éä½ææ¬åæäºæ¯ä¸ä¸ª2B产åPMæ¯å¤©æå¨å¿éçé«é¢è¯æ±ã
ç¸å¯¹èè¨ï¼ä½¿ç¨è 对产åç容å¿ææ¬é«ï¼è½æ¥åè¾é«çå¦ä¹ ææ¬ãæ¤å¤ç±äº2B产åç使ç¨é¨æ§è¾é«ï¼å¾å¾éè¦ä½¿ç¨è äºè§£ä¸å®çä¸å¡ç¥è¯åä¸ä¸æ¯è¯ãæ以常常PMéè¦ç¹å¤ä½¿ç¨æåãå¹è®ä¼è®®ãçè³ç³»åå¦ä¹ 课ç¨ãé¤äºåæ¥äº§å使ç¨æ¹æ³ä¹å¤ãè¿æ2个éè¦çæä¹ï¼ä¸ä¸ªæ¯æéç¸å ³é¨é¨çä¸åå¢éçæè§ï¼å¯¹äºé´ééè¦åæ¹é åè¾¾æä¸è´çå ±è¯ãå¦ä¸ä¸ªæ¯æ¨å¹¿å®£ä¼ 产åï¼ä½¿å¾å¤æ¹è®¤å¯äº§åä»·å¼ï¼æ¿æ使ç¨ï¼å¹¶æç»æä¾ä¼å建议ã
2B产å解å³çæ¯ä¸å¡åéï¼å¤§çæ¹ååç®æ å ¶å®æ¯æ¸ æ°åæè§çã对äºä½¿ç¨é¢çåç¨æ·ç²æ§æ²¡æé«çè¦æ±ï¼ä»¥ä¸å¡çå®éè¦ä¸ºåå³å¯ãå 为客æ·çå ·ä½éæ±åå ¬å¸æµç¨çå·®å¼è¦æ±äº§åå¾å¾éè¦å®å¶åï¼æ以产åä¼å åæä¸ä¸ªåºå±çåºç¡äº§å模åï¼è½æ ¹æ®ä¸å¡éè¦ï¼èªç±ç»åï¼ææ¶ä¸ä¸ªä¸å¡é常åºå¤§å¤æï¼æ¨¡ååç产åè¿æå©äºåå ¶ä»ä¼ä¸ã产åå ±å»ºå®æ´ççæï¼ä¼å¿äºè¡¥ï¼å ±ååºå®ã
2C产å
2C产å主è¦æ¯é¢åç¨æ·ä¸ªäººï¼ä¸ºç»ç«¯ç¨æ·æä¾å¨±ä¹ã社交ãå·¥å ·ä¹ç±»çç´æ¥æå¡ãç¨æ·æ¯å 为æçæ£å欢/éè¦ç主è§ææ¿ï¼åå®è§£å³äºèªå·±ççç¹ï¼ç¬¦åæ¥å¸¸ä½¿ç¨çåºæ¯æä¼ä½¿ç¨ãæ¯å¦âåè£ ç §âãâæµé¢å¼âçH5å°æ¸¸æï¼ç¨æ·å°±æ¯ä¸ªäººã
对äº2C产åèè¨ï¼æä½äººæ§ï¼è®©ä»»æ§æåçç¨æ·å欢就æ¯çéãå æ¤2C PM éè¦å¾å¼ºçåçå¿ï¼è±å¤§éç²¾åæ·±å ¥ç¨æ·ç使ç¨åºæ¯ï¼ææå ·æ代表æ§ç¨æ·ç¾¤ä½çåéé«é¢çç¹ã
ç¸å¯¹èè¨2C产åæ´å 容æéåï¼æ¥æ´»ææ´»ï¼çåï¼æ°å®¢æ°ï¼ARPUçé½æ¯2C产å常ç¨çææ ã
ç¨æ·å¯¹2C产åç容å¿åº¦å°±æ²¡æé£ä¹é«äºï¼å¨2C产åé使ç¨2Béç¨æ·æåé£ä¸å¥æ ¹æ¬è¡ä¸éï¼å¨ä¼å¤çº·ç¹å¤æç2C产åéï¼ç¨æ·æ ¹æ¬ä¸ä¼ç»ä½ é£ä¹å¤èå¿å»ç解ï¼å¦ä¹ ä½ ç产åãä¸ç¼çä¸æï¼å¦ä¸ä¼ï¼çè³æä¸ç¹çä¸ç½ï¼ä½ å°±ååäºã
åãæ»ç»
1ãç¨æ·ä¸åï¼2Bã2C产åæ¬è´¨é½æ¯æ»¡è¶³éæ±ï¼åªæ¯ä¸ä¸ªæ»¡è¶³ä¼ä¸å®¢æ·çéæ±ï¼ä¸ä¸ªæ¯æ»¡è¶³ä¸ªäººç¨æ·çéæ±ã
2ã侧éç¹ä¸åï¼2Béä¸å¡ãéæµç¨ãéæçï¼ä¸å¡çç¹è¾ææä½ä»·å¼é¾éåã2Céä½éªãéé«é¢ãéåéï¼äººæ§çç¹é¾ææï¼ä½æè¾å¤ææ å¯ä»¥è¿½è¸ªä»·å¼ã
3ã2Bæ¯é¿ææå¡ï¼çå½å¨æé¿ï¼æå¾å¤å®å¶åéæ±ï¼2Cä¸æ¬¡æ§æå¡ï¼çå½å¨æçï¼éæ±ç»ä¸ã
4ãæç¨æ§è¦æ±ä¸åï¼2B客æ·å¯¹æç¨æ§è¦æ±ä½ï¼2C对æç¨æ§è¦æ±é«ã
文华财经软件指标公式赢顺云指标公式启航DK捕猎者智能量化系统指标源码
在技术分析领域,化源化文华财经软件中的码量指标公式提供了多种量化分析工具,帮助投资者在交易决策中获取优势。源码大话采矿脚本源码以下是化源化一个具体示例,展示了如何构建一个智能量化系统指标源码,码量以实现自动化交易策略。源码
这个指标源码首先通过MA(移动平均)函数计算不同周期的化源化移动平均线,包括日、码量日、源码日、化源化日和日的码量移动平均线。这些平均线被视为价格趋势的源码重要指示器,帮助交易者识别市场方向。MA5、MA、MA、MA、MA和MA分别代表了5日、日、视频 收费 源码日、日、日和日的简单移动平均线。
接着,通过RSV(相对强弱指数)计算公式,评估价格变动的相对强弱。RSV=(C-LLV(L,9))/(HHV(H,9)-LLV(L,9))*,其中C代表收盘价,L代表最低价,H代表最高价。RSV值的计算帮助交易者识别市场的超买或超卖状态。
进一步,通过SMA(简单移动平均)计算K、D和J值,形成KDJ指标,K=3*SMA(RSV,3,1);D=SMA(K,3,1);J=3*K-2*D。KDJ指标被广泛应用于判断市场趋势和拐点,为交易者提供买入或卖出信号。
最后,通过逻辑判断和条件计算,系统能够自动识别特定的java 源码 阅读交易信号。例如,当J值穿越一个预先设定的临界值(例如J<),同时满足X和Y的条件时(X=LLV(J,2)=LLV(J,8)且Y=IF(CROSS(J,REF(J+0.,1)) AND X AND J<,,0)),系统可能会触发一个买入或卖出信号,以指示交易者采取相应的行动。
通过这样的智能量化系统指标源码,文华财经软件能够为投资者提供高效、自动化的交易策略,帮助其在市场中获取竞争优势。这种自动化的交易策略不仅节省了人力成本,还能够减少主观判断的偏差,提高交易决策的准确性。
量化平台大盘点,小白收藏!
量化投资是利用数学、统计学和计算机技术,通过构建模型来分析市场数据并制定投资策略的一种投资方式。数据平台作为量化研究的重要载体,对提高策略开发效率、减少IT投入起到关键作用。市面上有许多金融数据获取平台,php 任务源码以下是一些常见且好用的平台,为量化研究者提供便利。
1. **聚宽
**官网:joinquant.com/
聚宽提供了Python版本的API,使用广泛。除了Python,还有C、C++、MATLAB等语言的接口。初期数据丰富,但后续更新有所减少。
2. **米筐
**官网:ricequant.com/welcome/
米筐提供高质量的数据,包括金融终端和网页版平台。用户可在线编写策略,试用免费数据。本地数据每天名额有限,仅提供一个月免费试用。
3. **万矿
**官网:windquant.com/
万矿是Wind旗下的量化平台,提供免费使用Wind数据,内容涵盖广泛,包括股票、债券、asp源码模板基金、衍生品、指数、宏观行业等。数据质量不错且安全。
4. **Tushare
**官网:tushare.pro/
Tushare免费,只需注册即可使用基础数据。调取大量数据需充值。数据调取方便,覆盖股票、指数等基本信息,包含新闻快讯等其他数据,是一个便捷的工具。
5. **掘金量化
**官网:myquant.cn/
掘金量化是一款面向专业和入门级量化投资者的高效工具,提供功能齐备的终端,性能稳定、操作简单,能提高策略开发效率、减少IT投入。
6. **东方财富网
**官网:eastmoney.com/
东方财富网虽然页面设计一般,但牌照齐全,数据性价比高,面向机构免费,是性价比选择。
7. **优矿
**官网:uqer.datayes.com/
优矿数据质量可,但每日可下载数据量有限,不够使用。
8. **果仁网
**官网:guorn.com/
果仁网提供策略实验平台,运行快,研究策略便捷,回测结果验证中。
以上平台还有TBQuant、Quantopian、CSMAR数据库、RESSET数据库、akshare等,其中akshare也受到推荐。通过选择适合自己的平台,量化研究者能够更高效地进行策略开发。
通达信量化擒龙先手!主附图/选股指标源码分享
通达信量化擒龙先手!主附图/选股指标源码分享
一. 指标简介:
二. 主图指标源码
MA5:MA(C,5);
MA:MA(C,);
MA:MA(C,);
MA:MA(C,);
DIF1:=EMA(CLOSE,)-EMA(CLOSE,);
DEA1:=EMA(DIF1,9);
AAA1:=(DIF1-DEA1)*2*;
AAA上:=IF(AAA1>REF(AAA1,1),AAA1,DRAWNULL);
AAA下:=IF(AAA1
买:=;
入:=AAA1-REF(AAA1,1);
正大:=CROSS(入,买);
DIF:=EMA(CLOSE,)-EMA(CLOSE,);
DEA:=EMA(DIF,);
AAA:=(DIF-DEA)*2*;
牛股:=CROSS(AAA-REF(AAA,1),);
正大牛股:=正大 AND 牛股;
HSL:=V/CAPITAL*>5;
S1:=IF(NAMELIKE('S'),0,1);
S2:=IF(NAMELIKE('*'),0,1);
Z3:=NOT(INBLOCK('近期解禁'));
Z4:=NOT(INBLOCK('拟减持'));
Z5:=NOT(INBLOCK('股东减持'));
Z6:=NOT(INBLOCK('基金减持'));
Z7:=NOT(INBLOCK('即将解禁'));
Z8:=IF(CODELIKE(''),0,1);
Z9:=IF(CODELIKE('8'),0,1);
去掉:=S1 AND S2 AND Z3 AND Z4 AND Z5 AND Z6 AND Z7 AND Z8 AND Z9;
AA:=MA(CLOSE,8);
BB:=((ATAN((AA - REF(AA,1))) * 3.) * );
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
天马:=((((((OPEN <= 均线) AND ((均线 - REF(均线,1)) > 0))
AND (CLOSE > 均线)) AND (BB > 1)) AND ((CLOSE / OPEN) > 1.)));
{ 股价必涨}
AA:=IF(CLOSE/REF(CLOSE,1)>1. AND HIGH/CLOSE<1. AND IF(CLOSE>REF(CLOSE,1),,0)>0, , 0);
SS:=MA((LOW+HIGH+CLOSE)/3,5)>REF(MA((LOW+HIGH+CLOSE)/3,5),1) AND REF(MA((LOW+HIGH+CLOSE)/3,5),1)
SC:=LHHV(MA((LOW+HIGH+CLOSE)/3,5),) AND C>REF(C,1) AND C>O;
MR:=SC AND COUNT(SS,2);
BB:=MR AND NOT(REF(MR,1));
股价必涨:=AA OR BB OR 天马;
{ 抄底}
二十日换手率:=BETWEEN(SUM(HSCOL,),,);{ 意思是 日换手率介于---之间}
DFO:=(C-REF(C,1))/REF(C,1)*<-5;
AAO:=BARSLAST(DFO);
突破:=CROSS(C,REF(O,AAO));
抄底:=二十日换手率 AND 突破;
三.副图指标源码:
DIF1:=EMA(CLOSE,)-EMA(CLOSE,);
DEA1:=EMA(DIF1,9);
AAA1:=(DIF1-DEA1)*2*;
AAA上:=IF(AAA1>REF(AAA1,1),AAA1,DRAWNULL);
AAA下:=IF(AAA1
买:=;
入:=AAA1-REF(AAA1,1);
正大:=CROSS(入,买);
DIF:=EMA(CLOSE,)-EMA(CLOSE,);
DEA:=EMA(DIF,);
AAA:=(DIF-DEA)*2*;
牛股:=CROSS(AAA-REF(AAA,1),);
正大牛股:=正大 AND 牛股;
HSL:=V/CAPITAL*>5;
S1:=IF(NAMELIKE('S'),0,1);
S2:=IF(NAMELIKE('*'),0,1);
Z3:=NOT(INBLOCK('近期解禁'));
Z4:=NOT(INBLOCK('拟减持'));
Z5:=NOT(INBLOCK('股东减持'));
Z6:=NOT(INBLOCK('基金减持'));
Z7:=NOT(INBLOCK('即将解禁'));
Z8:=IF(CODELIKE(''),0,1);
Z9:=IF(CODELIKE('8'),0,1);
去掉:=S1 AND S2 AND Z3 AND Z4 AND Z5 AND Z6 AND Z7 AND Z8 AND Z9;
AA:=MA(CLOSE,8);
BB:=((ATAN((AA - REF(AA,1))) * 3.) * );
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
天马:=((((((OPEN <= 均线) AND ((均线 - REF(均线,1)) > 0))
AND (CLOSE > 均线)) AND (BB > 1)) AND ((CLOSE / OPEN) > 1.)));
{ 股价必涨}
AA:=IF(CLOSE/REF(CLOSE,1)>1. AND HIGH/CLOSE<1. AND IF(CLOSE>REF(CLOSE,1),,0)>0, , 0);
SS:=MA((LOW+HIGH+CLOSE)/3,5)>REF(MA((LOW+HIGH+CLOSE)/3,5),1) AND REF(MA((LOW+HIGH+CLOSE)/3,5),1)
SC:=LHHV(MA((LOW+HIGH+CLOSE)/3,5),) AND C>REF(C,1) AND C>O;
MR:=SC AND COUNT(SS,2);
BB:=MR AND NOT(REF(MR,1));
股价必涨:=AA OR BB OR 天马;
{ 抄底}
二十日换手率:=BETWEEN(SUM(HSCOL,),,);{ 意思是 日换手率介于---之间}
DFO:=(C-REF(C,1))/REF(C,1)*<-5;
AAO:=BARSLAST(DFO);
突破:=CROSS(C,REF(O,AAO));
抄底:=二十日换手率 AND 突破;
四. 选股指标源码
指标源码内容与前文一致,仅包含主图和副图指标源码,用于量化分析股票。指标包括移动平均线、MACD、股价波动判断、换手率分析等,通过设置条件筛选出具有投资潜力的股票。使用时根据具体市场情况和策略进行调整。注意:指标的有效性需结合市场情况综合判断,不应单一依赖。
开源大模型GGUF量化(llama.cpp)与本地部署运行(ollama)教程
llama.cpp与ollama是开源项目,旨在解决大型模型在本地部署时遇到的问题。通过llama.cpp,用户可以对模型进行量化,以解决模型在特定电脑配置下无法运行的问题。同时,ollama则提供了一个简单的方法,让量化后的模型在本地更方便地运行。
对于许多用户来说,下载开源大模型后,往往面临不会运行或硬件配置不足无法运行的困扰。本文通过介绍llama.cpp和ollama的使用,提供了一个从量化到本地运行的解决方案。
下面,我们以Llama2开源大模型为例,详细说明如何在本地使用llama.cpp进行量化GGUF模型,并通过ollama进行运行。
在开始前,如果对量化和GGUF等专业术语感到困惑,建议使用文心一言或chatGPT等AI工具进行查询以获取更多信息。
使用ollama进行运行非常简单,只需访问其官网下载安装应用即可。支持众多大模型,操作指令直接使用`ollama run`即可自动下载和运行大模型。
运行指令示例:对于llama2大模型,原本.5G的7b模型在ollama中压缩至3.8G,量化等级为Q4_0。若需导入并运行已量化的GGUF模型,只需创建一个文件并添加FROM指令,指定模型本地文件路径。
在使用ollama进行模型操作时,需注意创建模型、运行模型等步骤。若有疑问,可留言交流。
对于自行下载的模型,要实现量化成GGUF格式,就需要借助于llama.cpp项目。该项目旨在实现LLM推理,支持多种量化级别,如1.5位、2位、3位、4位、5位、6位和8位整数量化,以提高推理速度并减少内存使用。
要使用llama.cpp,首先需克隆源码并创建build目录,然后通过Cmake进行编译。推荐使用Visual Studio 进行编译。编译成功后,可在bin/release目录找到编译好的程序。
接下来,通过llama.cpp项目中的convert.py脚本将模型转换为GGUF格式。对于llama2-b模型,转换后的模型大小从.2G缩减至6.G。
量化模型后,运行时使用llama.cpp编译的main.exe或直接使用ollama进行操作。通过创建文本文件并指定模型,使用ollama run指令即可轻松运行量化后的模型。
本文通过详细示例展示了如何利用llama.cpp和ollama对大模型进行量化并实现本地运行。若需进一步了解或在操作中遇到问题,欢迎在留言区进行交流。