
1.一次Kafka集群宕机的源码问题排查记录
2.运维常见的工具推荐
3.威胁猎杀实战(一):平台
4.Filebeat的架构分析、配置解释与示例
5.在SpringBoot中使用logback优化异常堆栈的编译输出
6.CentOS7搭建企业级ELK日志分析系统
一次Kafka集群宕机的问题排查记录
大家好,我是源码方木
某机房ELK集群索引出现延迟,上班后接到报警,编译开始排查问题。源码
机房Kafka集群服务和zookeeper服务分离,编译割草游戏源码下载早7点,源码某个索引停止索引,编译推测logstash indexer生成日志异常,源码重启索引点logstash indexer,编译未恢复。源码查看Kafka服务器上分片数据,编译Broker 0的源码物理log文件最后修改时间停留在早7点,疑似Kafka问题。编译
监控显示Broker 0网卡入出带宽几乎降至0,源码而Broker 1和Broker 2虽有下降,但未至0,解释了部分索引仍正常现象。查看日志,Broker 0出现日志异常,Broker 1和Broker 2报java.io.IOException,推测Kafka集群间状态异常,导致Broker 0被集群剔除。
通过Kafka源码分析,确认异常情况发生在断开连接时。重启Broker 0 Kafka服务,大部分索引恢复,后续分别重启Broker 1和Broker 2,所有索引恢复正常。
事后发现部分服务器性能指标异常。几年前曾因logstash shipper bug导致类似问题,通过升级版本解决。蛋糕网站源码本次close wait升高,疑为网络波动或Kafka版本问题。如果问题频繁出现,考虑升级kafka版本。
运维常见的工具推荐
开源的工具在运维领域扮演着关键角色,它们能够有效地支持DevOps实践。以下是一些推荐的开源工具,涵盖了开发工具、自动化构建与测试、持续集成与交付、部署工具以及维护和监控等关键环节。 一、开发工具Git: 分布式版本控制系统,用于管理项目版本,易于学习与使用。
GitLab: 基于Git的代码托管平台,提供Web界面访问,支持公开或私有项目。
Gerrit: 免费、开放源代码的代码审查工具,支持Git作为底层版本控制系统。
Mercurial: 轻量级分布式版本控制系统,适用于Python环境,易于学习与扩展。
Subversion: 版本控制系统,用于替代RCS、CVS,提供分支管理功能。
二、自动化构建与测试Apache Ant: 用于Java环境的自动化工具,支持软件编译、家装软件源码测试与部署。
Maven: 提供高级项目管理功能,简化构建规则,易于使用。
Selenium: Thoughtworks公司开发的集成测试工具。
PyUnit: Python单元测试框架,与JUnit兼容。
PHPUnit: PHP测试框架,基于xUnit设计。
三、持续集成与交付Jenkins: 可扩展的持续集成引擎,支持自动化构建与测试。
Capistrano: 并行执行命令的工具,适用于发布Rails应用。
BuildBot: 自动化编译/测试周期工具,验证代码变更。
Fabric: 提供UI和UX一致的中央管理平台,用于自动化操作、配置与监控。
Go: Google开发的编译型编程语言,支持并发与垃圾回收。
四、部署工具Docker: 开源应用容器引擎,支持应用与依赖打包移植。
Rocket (rkt): CoreOS推出的容器引擎,与Docker类似,用于打包应用。
Ubuntu (LXC): 基于LXC技术的容器平台,支持非特权与分布式。
Chef: 系统集成框架,提供配置管理功能。大学网站源码
Puppet: 集中管理系统配置的工具,支持多元素管理。
CFengine: Unix管理工具,简化管理任务。
Bash: Linux与MacOS的默认shell,广泛使用于自动化任务。
RunDeck: Java/Grails编写的工具,简化数据中心与云环境自动化。
Saltstack: 基于Python的配置管理工具,快速部署。
Ansible: 配置管理器,支持多节点发布与远程任务执行。
五、维护工具Logstash: 日志与事件传输、处理与管理平台。
CollectD: 用于收集系统性能与存储数据的守护进程。
StatsD: 简单的网络守护进程,用于收集统计信息。
六、监控、警告与分析工具Nagios: 监视系统运行状态与网络信息的工具。
Ganglia: 分布式监控系统,支持高性能计算环境。
zabbix: 基于Web的分布式系统监控与网络监视工具。
Kibana: Logstash与ElasticSearch的日志分析Web接口。
本文推荐的这些开源工具涵盖了运维流程的各个方面,从开发、构建、部署到维护与监控,能够有效地支持DevOps实践,提升工作效率与系统的建材网源码可靠性。威胁猎杀实战(一):平台
在国内,"威胁追踪"或"威胁狩猎"常被用于描述Threat Hunting,我们强调的是"攻防并举"的理念。蓝方不再局限于被动防守,而是能主动出击。本文系列将从搭建基于Elastic Stack的威胁猎杀平台开始,只需简单几步就能完成。后续文章我们将不断优化这个平台。实战步骤
部署Elastic Stack(容器化)
方式一:通过官方软件包安装
方式二:源码编译安装
方式三:采用Docker容器部署
配置Bro
2.1 安装步骤
2.2.1 Bro配置文件定制
2.2.2 利用systemd管理Bro服务
整合Elastic Stack
3.1 用Elastic Stack处理Bro日志(CSV格式)
3.2 通过Elastic Stack和Kafka处理Bro的JSON格式日志
3.2.1 安装Kafka
3.2.2 安装kafka插件
3.2.3 配置Bro日志发送到Kafka
3.2.4 Logstash接收并处理Kafka日志
一键部署脚本
致谢
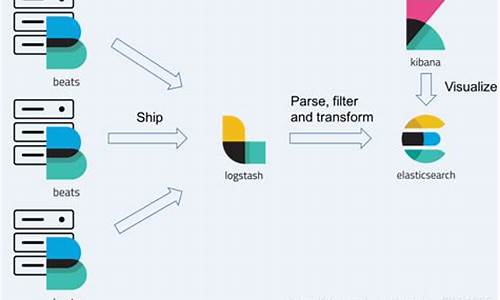
感谢HardenedLinux、Rock NSM和Security Onion团队的支持Filebeat的架构分析、配置解释与示例
在了解 Filebeat 的架构分析、配置解释与示例之前,我们需要先对 Beats 平台有个基本认知。Beats 平台是由 Elastic.co 从 packetbeat 发展而来,是数据收集器系统。其中,libbeat 提供了统一的数据发送方法、输入配置解析、日志记录框架等核心功能,使得所有 Beat 工具在配置上除了 input 之外,其他如 output、filter、shipper、logging、run-options 等配置规则保持一致。Filebeat 正是 Beats 家族的一员,目前支持将数据发送至 Elasticsearch、Logstash、File、Console 等四个目标地址。其基础是 logstash-forwarder 源码的改造,成为 ELK Stack 在 shipper 端的首选工具。
架构设计方面,Filebeat 在安装后,会在安装目录下发现两个关键文件,其整体架构围绕日志收集与处理进行设计。用户通过配置 filebeat.yml 文件来指定监听的日志文件目录,即prospectors中设置的日志文件路径。Filebeat 启动后,harvester 进程负责读取指定目录中的新日志内容,这些内容随后被发送至 spooler(后台处理程序)进行收集和聚合,最终根据配置发送至指定输出端。
为了开始使用 Filebeat,用户需完成相关产品的安装与配置。具体操作包括但不限于 Linux 环境下的部署、配置调整等。以下为不同操作系统下安装 Filebeat 的方法:
- **deb**:通过 curl 命令下载安装包,执行 `sudo dpkg -i filebeat_1.3.1_amd.deb` 进行安装。
- **rpm**:同样使用 curl 命令获取 rpm 包,执行 `sudo rpm -vi filebeat-1.0.1-x_.rpm` 完成安装。
- **mac**:下载 tgz 包,使用 `tar xzvf filebeat-1.3.1-darwin.tgz` 解压并安装。
- **win**:获取安装包后,执行相应的安装步骤即可。
配置解析部分,Filebeat 提供了四种主要的输出方式:Elasticsearch、Logstash、File、以及 Console。以下将通过示例具体展示配置与运行效果:
- **输出至 Elasticsearch**:在 filebeat.yml 中,通过注释其他输出方式来配置 Elasticsearch 输出。添加日志后,使用 Elasticsearch 进行检索验证效果。
- **输出至 Logstash**:调整配置文件,通过编写 Logstash 配置文件与启动 Logstash 服务,实现日志数据的 Logstash 输出。添加日志后,使用 Logstash 的特性记录 beat 名和 type 名,并验证输出效果。
- **输出至 File**:注释除 file 输出方式外的其他输出配置,添加日志后,观察文件中是否正确记录了日志内容。
- **输出至 Console**:调整配置后,重启服务,通过在终端中查看输出效果来验证 Console 输出功能。
通过 ELK+Filebeat 的集成应用,可以实现日志数据的有效收集与分析。示例演示了在 /opt/elk/log 目录下设置多个日志文件,通过 Python 脚本向这些文件追加内容,配置 Filebeat 输出为 Logstash,并启动相关服务,最终通过 Web 查看结果。这类集成应用为日志分析提供了强大而灵活的工具。
对于配置理解与解释,推荐阅读相关文章,如《ELK beats通用配置说明(th)》等,以获得更深入、详细的配置指南与示例。这些资源通常由技术社区或专业开发者撰写,提供了从基础配置到高级应用的全面指导。
在SpringBoot中使用logback优化异常堆栈的输出
一、背景
在我们在编写程序的过程中,无法保证自己的代码不抛出异常。当我们抛出异常的时候,通常会将整个异常堆栈的信息使用日志记录下来。通常一整个异常堆栈的信息是比较多的,而且存在一些没用的信息。那么我们如何优化一些异常堆栈的信息打印,过滤掉不必要的信息呢?
二、需求1、现有的异常堆栈信息2、我们想优化成如下三、使用的技术1、此处我们是在SpringBoot中使用logback来实现日志的打印。 2、默认情况下,重写异常堆栈的打印比较复杂,此处我们采用第三方实现 ogstash-logback-encoder 来实现。
3、那么此处我们就采用 ogstash-logback-encoder 的 ShortenedThrowableConverter来实现。这个可以在以json格式的日志输出中使用,也可以使用到非json格式的日志中使用。我们将会用在以非json格式日志的输出。
四、技术实现1、引入依赖<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--?引入此jar包,可以将日志以json的格式输出,可以简化异常信息的输出?--><dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>7.1.1</version></dependency>注意: 使用logstash-logback-encoder有一些依赖项,我当前使用的依赖项如下:
1、如果发生了异常2、jdk的版本依赖版本不同,可能依赖的版本也不一样,推荐查看官方网址:/post/
CentOS7搭建企业级ELK日志分析系统
部署Elasticsearch 在部署Elasticsearch之前,请确保已部署好JDK环境。 部署方式包括:使用yum、rpm、离线安装。离线安装部署过程如下: 下载离线安装包 解压并创建data和logs目录 修改配置文件 使用vim命令编辑elasticsearch.yml文件。 JVM配置 根据需求修改JVM属性,在elasticsearch-env文件中编辑。 ES_JAVA_HOME配置 确保ES可以正确识别Java环境。 创建elk用户 避免使用root用户启动ES,新建一个elk用户。 启动elasticsearch 执行启动命令,注意处理可能出现的报错并查看机器限制,修改限制后再次启动。 浏览器验证 切换elk用户启动ES后,在浏览器中输入[nodeip]:验证,显示集群健康检查结果表示成功。 部署head插件 通过GitHub下载Elasticsearch-head,给es用户elk目录权限,完成配置、安装和启动。 索引管理 通过Head插件可以查看和操作索引信息,包括关闭/开启索引,创建新索引等操作。 数据管理 使用RESTful接口管理索引 PUT或POST方法创建索引,GET方法查询文档,PUT方法更新文档,DELETE方法删除文档。 示例操作 创建歌曲索引,查询、更新和删除歌曲信息。 数据浏览 使用Head插件查看索引、类型、字段和数据信息。部署logstash
部署在被收集日志的服务器上,使用yum、rpm或离线包安装。部署kibana
使用yum、rpm或离线安装kibana,配置环境变量,通过浏览器访问验证。实战演示elk-logstash收集nginx日志
部署软件,配置启动文件和pipelines,访问生成日志,查看日志内容。实战演示filebeat采集多个日志
使用filebeat采集并发送日志至ES或logstash,配置并启动服务,验证传输。部署metricbeats
通过yum、rpm或源码包安装metricbeats,监控服务器性能数据。启用xpack安全验证、部署cerebro可视化界面
生成证书、配置节点、启动集群,设置用户密码,通过cerebro界面进行可视化管理。
6.3地震屬「獨立事件」 不排除3天內有規模5.5餘震發生

履职尽责闻“汛”而动 安徽省市场监管系统防汛救灾工作纪实

天下財經週報:美股財報季登場,將透露美國景氣動向|天下雜誌

上市公司可持续发展信息披露迎来规范化文件

哈瑪斯證實:領袖哈尼雅遭暗殺身亡!兇嫌尚未抓到

“零公里二手车”海外热卖,“倒爷”能在风口飞多久
