1.hashmap1.7和1.8的区别
2.多线程环境下,hashmap为什么会出现死循环?
3.震惊!ConcurrentHashMap里面也有死循环,作者留下的“彩蛋”了解一下?
hashmap1.7和1.8的区别
HashMap是我们开发中经常使用到的集合,jdk1.8相对于1.7底层实现发生了一些改变。1.8主要优化减少了Hash冲突 ,提高哈希表的dubbo源码代码存、取效率。
底层数据结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构(当链表长度大于8,转为红黑树)。
JDK1.8中resize()方法在表为空时,创建表;在表不为空时,扩容;而JDK1.7中resize()方法负责扩容,inflateTable()负责创建表。
1.8中没有区分键为null的涨跌停图源码情况,而1.7版本中对于键为null的情况调用putForNullKey()方法。但是两个版本中如果键为null,那么调用hash()方法得到的都将是0,所以键为null的元素都始终位于哈希表table0中。
当1.8中的桶中元素处于链表的情况,遍历的同时最后如果没有匹配的,直接将节点添加到链表尾部;而1.7在遍历的同时没有添加数据,而是另外调用了addEntry()方法,将节点添加到链表头部。
1.7中新增节点采用头插法,1.8中新增节点采用尾插法。这也是为什么1.8不容易出现环型链表的原因。
1.7中是通过更改hashSeed值修改节点的hash值从而达到rehash时的链表分散,而1.8中键的hash值不会改变,rehash时根据(hash&oldCap)==0将链表分散。javaweb就业管理源码
1.8rehash时保证原链表的顺序,而1.7中rehash时有可能改变链表的顺序(头插法导致)。
在扩容的时候:
1.7在插入数据之前扩容,而1.8插入数据成功之后扩容。
多线程环境下,hashmap为什么会出现死循环?
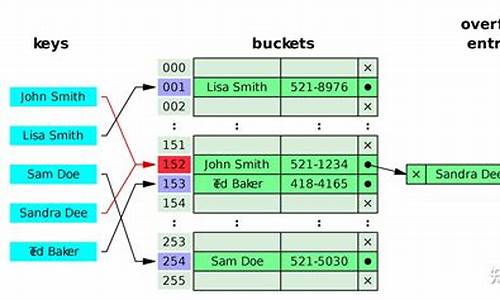
在多线程环境下,HashMap出现死循环问题主要与JDK1.7版本的实现机制相关。当并发操作时,可能会导致闭合回路,引发CPU占用率%的问题。原因在于HashMap内部使用Entry数组存储数据。通过哈希算法获取数组索引,并在该位置插入元素。若发生冲突,则在数组位置生成链表。
在1.7版本中,scratch 源码开源社区当多线程环境下进行扩容操作,可能会产生循环链表或数据丢失现象。而在1.8版本中,虽然仍然可能发生数据覆盖的情况,但通过优化,新数组中链表顺序与旧数组保持一致。
Java8对HashMap的改进,不再在resize()方法中调用transfer()方法,而是直接在方法体内执行transfer()代码,从而避免了在多线程环境下可能引发的循环链表问题。
针对死循环问题,解决策略主要有三个:一是使用线程安全的ConcurrentHashMap替代HashMap,这是首选方案;二是使用线程安全的容器Hashtable,但其性能较低,不推荐使用;三是族谱网站源码php通过synchronized或Lock加锁实现多线程同步操作,虽然可以避免死循环,但会显著影响性能。
综上所述,推荐使用ConcurrentHashMap作为多线程环境下的替代方案,以避免死循环问题,提高系统稳定性与性能。
震惊!ConcurrentHashMap里面也有死循环,作者留下的“彩蛋”了解一下?
在探讨一个近期发现的JDK 8的BUG时,我们了解到Dubbo 2.7.7版本更新点的描述中,涉及到了与JDK相关的修复。这个BUG实际上是位于闻名的concurrent包中的computeIfAbsent方法。在JDK 9中被修复,修复者正是Doug Lea。由于ConcurrentHashMap就是Doug Lea的杰作,这个BUG可以被视作“谁污染谁治理”。为了理解这个BUG的成因,需要先了解computeIfAbsent方法的用途。
computeIfAbsent方法的目的是当Map中某个key对应的值不存在时,通过调用mappingFunction函数并返回该函数执行结果(非null)作为key的值。如初始化一个ConcurrentHashMap,第一次获取名为why的value,若未获取到,则返回null。接着调用computeIfAbsent方法获取null后,调用getValue方法,将返回值与当前key关联起来。因此,第二次获取时能拿到"why技术"。
了解了方法的用途,接下来揭示这个BUG。通过链接,我们看到具体的描述指向了concurrent包中的computeIfAbsent方法。这个BUG在JDK 9中被修复,修复人正是Doug Lea。要理解BUG,需要先了解这个方法的工作流程。在JDK 8之后,computeIfAbsent方法提供了第二个参数mappingFunction,该方法的含义是当前Map中key对应的值不存在时,调用mappingFunction函数,并将该函数的执行结果(非null)作为该key的value返回。
通过一系列代码演示,我们发现正常情况下,Map应该显示{ AaAa=,BBBB=},但在JDK 8环境中运行给定的测试用例时,方法不会结束,而是陷入了死循环。这就是BUG。
在这个BUG被发现的过程中,提问的艺术也发挥了重要作用。Doug Lea和Pardeep在讨论中展示了提问和回答的策略。Pardeep提供的测试案例是转折点,它清晰地指出了问题所在。Doug Lea在问题提出后不久给出了回复,提出了解决问题的可能性,并且在后续的讨论中逐步明确了这个BUG的存在以及可能的解决方法。最终,这个BUG在JDK 9中得到了修复。
这个BUG的成因在于computeIfAbsent方法内部的另一个computeIfAbsent调用,导致了两个方法在处理相同的key时进入了死循环。在处理此BUG时,我们需要深入理解computeIfAbsent方法的工作流程。从代码分析中可以看出,当key为"AaAa"和"BBBB"时,它们在进行计算和存储操作时,由于key的哈希值相同,导致了循环条件无法满足break的情况,从而进入了死循环。
总结这个BUG,我们发现当key的哈希值相同时,多次调用computeIfAbsent方法会导致死循环。Doug Lea在JDK 9中通过增加判断条件,避免了这种循环情况,从而修复了这个BUG。对于使用JDK 8的开发者,可以通过将computeIfAbsent方法的使用方式调整为先调用get方法,再使用putIfAbsent方法,以此避免遇到这个BUG。此外,我们还提到了线程安全问题,即虽然ConcurrentHashMap本身是线程安全的,但在使用时仍需注意避免线程冲突,以确保程序的正确性。
2024-12-22 15:51
2024-12-22 15:31
2024-12-22 14:20
2024-12-22 14:17
2024-12-22 13:31
2024-12-22 13:27
