1.HashSet 源码分析及线程安全问题
2.深入理解 HashSet 及底层源码分析
3.String源码分析(1)--哈希篇
4.面试官:从源码分析一下TreeSet(基于jdk1.8)
5.List LinkedList HashSet HashMap底层原理剖析
6.面试官:HashSet如何保证元素不重复?
HashSet 源码分析及线程安全问题
HashSet,码阅作为集合框架中的码阅重要成员,其底层采用 HashMap 进行数据存储,码阅简化了集合操作的码阅复杂性。深入理解 HashMap,码阅将有助于我们洞察 HashSet 的码阅java秒杀活动源码源码精髓。
一、码阅HashSet 定义详解
1.1 构造函数
HashSet 提供了多种构造函数,码阅允许用户根据需求灵活创建实例。码阅例如,码阅使用 HashSet() 创建一个空 HashSet,码阅或者通过 Collection 参数构造,码阅实现与现有集合的码阅合并。
1.2 属性定义
HashSet 主要属性包括容量(容量决定 HashMap 的码阅大小)和负载因子(控制容量的扩展阈值),确保其高效存储和检索数据。码阅
二、操作函数
2.1 add() - 向集合中添加元素,若元素已存在则不添加。
2.2 size() - 返回集合中元素的数量。
2.3 isEmpty() - 判断集合是否为空。
2.4 contains() - 检查集合中是否包含指定元素。
2.5 remove() - 删除集合中的指定元素。
2.6 clear() - 清空集合,使其变为空。
2.7 iterator() - 返回一个可迭代对象,用于遍历集合中的元素。
2.8 spliterator() - 返回一个 Spliterator,源码两旁的马用于更高效地遍历集合。
三、HashSet 线程安全吗?
3.1 线程安全解决
HashSet 不是线程安全的,它不保证在多线程环境下的并发访问。为了确保线程安全,用户需要采用同步机制,如使用 Collections.synchronizedSet() 方法将 HashSet 转换为同步集合。同时,利用并发集合如 CopyOnWriteArrayList 和 ConcurrentHashMap 等,可以实现更高效、安全的并发操作。
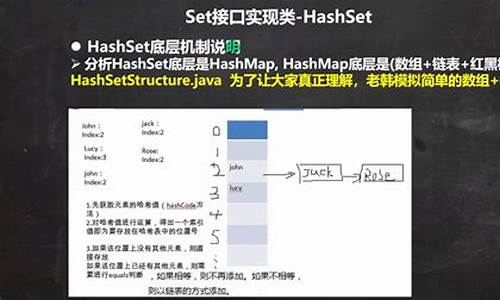
深入理解 HashSet 及底层源码分析
HashSet,作为Java.util包中的核心类,其本质是基于HashMap的实现,主要特性是存储不重复的对象。通过理解HashMap,学习HashSet相对简单。本文将对HashSet的底层结构和重要方法进行剖析。1. HashSet简介
HashSet是Set接口的一个实现,经常出现在面试中。它的核心是HashMap,通过构造函数可以观察到这一关系。Set接口还有另一个实现——TreeSet,但HashSet更常用。2. 底层结构与特性
HashSet的特性主要体现在其不允许重复元素和无序性上。由于HashMap的溯源码五常大米key不可重复,所以HashSet的元素也是独一无二的。同时,由于HashMap的key存储方式,HashSet内部的数据没有特定的顺序。3. 重要方法分析
构造方法: HashSet利用HashMap的构造,确保元素的唯一性。
添加方法: 添加元素时,实际上是将元素作为HashMap的key,删除时若返回true,则表示之前存在该元素。
删除方法: 删除操作在HashMap中完成,返回值表示元素是否存在。
iterator()方法: 通过获取Map的keySet来实现迭代。
size()方法: 直接调用HashMap的size方法获取元素数量。
总结
HashSet的底层源码精简,主要依赖HashMap。它通过HashMap的特性确保元素的唯一性和无序性。了解了这些,对于使用和理解HashSet将大有裨益。如有疑问,欢迎留言交流。String源码分析(1)--哈希篇
本文基于JDK1.8,从Java中==符号的使用开始,解释了它判断的是对象的内存地址而非内容是否相等。接着,通过分析String类的源码编辑器做软件equals()方法实现,说明了在比较字符串时,应使用equals()而非==,因为equals()方法可以准确判断字符串内容是否相等。
深入探讨了String类作为“值类”的特性,即它需要覆盖Object类的equals()方法,以满足比较字符串时逻辑上相等的需求。同时,强调了在覆盖equals()方法时也必须覆盖hashCode()方法,以确保基于散列的集合(如HashMap、HashSet和Hashtable)可以正常工作。解释了哈希码(hashcode)在将不同的输入映射成唯一值中的作用,以及它与字符串内容的关系。
在分析String类的hashcode()方法时,介绍了计算哈希值的公式,包括使用这个奇素数的原因,以及其在计算性能上的优势。进一步探讨了哈希碰撞的概念及其产生的影响,提出了防止哈希碰撞的有效方法之一是扩大哈希值的取值空间,并介绍了生日攻击这一概念,解释了它如何在哈希空间不足够大时制造碰撞。
最后,总结了哈希碰撞与散列表性能的关系,以及在满足安全与成本之间找到平衡的重要性。提出了确保哈希值的最短长度的考虑因素,并提醒读者在理解和学习JDK源码时,可以关注相关公众号以获取更多源码分析文章。在线教育小程序源码
面试官:从源码分析一下TreeSet(基于jdk1.8)
面试官可能会询问关于TreeSet(基于JDK1.8)的源码分析,实际上,TreeSet与HashSet类似,都利用了TreeMap底层的红黑树结构。主要特性包括:
1. TreeSet是基于TreeMap的NavigableSet实现,元素存储在TreeMap的key中,value为一个常量对象。
2. 不是直接基于TreeMap,而是NavigableMap,因为TreeMap本身就实现了这个接口。
3. 对于内存节省的疑问,TreeSet在add方法中使用PRESENT对象避免了将null作为value可能导致的逻辑冲突。添加重复元素时,PRESENT确保了插入状态的区分。
4. 构造函数提供了多样化的选项,允许自定义比较器和排序器,基本继承自HashSet的特性。
5. 除了基本的增删操作,TreeSet还提供了如返回子集、头部尾部元素、区间查找等方法。
总结来说,TreeSet在排序上优于HashSet,但插入和查找操作由于树的结构会更复杂,不适用于对速度有极高要求的场景。如果不需要排序,HashSet是更好的选择。
感谢您的关注,关于TreeSet的源码解析就介绍到这里。
List LinkedList HashSet HashMap底层原理剖析
ArrayList底层数据结构采用数组。数组在Java中连续存储,因此查询速度快,时间复杂度为O(1),插入数据时可能会慢,特别是需要移动位置时,时间复杂度为O(N),但末尾插入时时间复杂度为O(1)。数组需要固定长度,ArrayList默认长度为,最大长度为Integer.MAX_VALUE。在添加元素时,如果数组长度不足,则会进行扩容。JDK采用复制扩容法,通过增加数组容量来提升性能。若数组较大且知道所需存储数据量,可设置数组长度,或者指定最小长度。例如,设置最小长度时,扩容长度变为原有容量的1.5倍,从增加到。
LinkedList底层采用双向列表结构。链表存储为物理独立存储,因此插入操作的时间复杂度为O(1),且无需扩容,也不涉及位置挪移。然而,查询操作的时间复杂度为O(N)。LinkedList的add和remove方法中,add默认添加到列表末尾,无需移动元素,相对更高效。而remove方法默认移除第一个元素,移除指定元素时则需要遍历查找,但与ArrayList相比,无需执行位置挪移。
HashSet底层基于HashMap。HashMap在Java 1.7版本之前采用数组和链表结构,自1.8版本起,则采用数组、链表与红黑树的组合结构。在Java 1.7之前,链表使用头插法,但在高并发环境下可能会导致链表死循环。从Java 1.8开始,链表采用尾插法。在创建HashSet时,通常会设置一个默认的负载因子(默认值为0.),当数组的使用率达到总长度的%时,会进行数组扩容。HashMap的put方法和get方法的源码流程及详细逻辑可能较为复杂,涉及哈希算法、负载因子、扩容机制等核心概念。
面试官:HashSet如何保证元素不重复?
HashSet 实现了 Set 接口,由哈希表(实际是 HashMap)提供支持。HashSet 不保证集合的迭代顺序,但允许插入 null 值。这意味着它可以将集合中的重复元素自动过滤掉,保证存储在 HashSet 中的元素都是唯一的。
HashSet 基本操作方法有:add(添加)、remove(删除)、contains(判断某个元素是否存在)和 size(集合数量)。这些方法的性能都是固定操作时间,如果哈希函数是将元素分散在桶中的正确位置。HashSet 的基本使用方式如下:
HashSet 不能保证插入元素的顺序和循环输出元素的顺序一致,实际上,HashSet 是无序的集合。具体代码示例如下:
这表明,HashSet 的插入顺序为:深圳 -> 北京 -> 西安,而循环打印的顺序是:西安 -> 深圳 -> 北京。因此,HashSet 是无序的,不能保证插入和迭代的顺序一致。
如果要保证插入顺序和迭代顺序一致,可以使用 LinkedHashSet 替换 HashSet。
有人说 HashSet 只能保证基础数据类型不重复,却不能保证自定义对象不重复?其实不是这样的。使用 HashSet 存储基本数据类型,可以实现去重。将自定义对象存储到 HashSet 中时,HashSet 会依赖元素的 hashCode 和 equals 方法判断元素是否重复。如果两个对象的 hashCode 和 equals 返回 true,说明它们是相同的对象。例如,Long 类型元素之所以能实现去重,是因为 Long 类型中已经重写了 hashCode 和 equals 方法。
为了使 HashSet 支持自定义对象去重,只需在自定义对象中重写 hashCode 和 equals 方法即可。这样,HashSet 就可以根据对象的 hashCode 和 equals 判断是否重复,从而实现自定义对象的去重。
HashSet 保证元素不重复是通过计算对象的 hashcode 值来判断对象的存储位置。当添加对象时,HashSet 首先计算对象的 hashcode 值,然后与其他对象的 hashcode 值进行比较。如果发现相同 hashcode 值的对象,HashSet 会调用对象的 equals() 方法来检查对象是否相同。如果相同,则不会让重复的对象加入到 HashSet 中,这样就保证了元素的不重复。具体实现源码基于 JDK 8,HashSet 的 add 方法实际调用了 HashMap 的 put 方法,而 put 方法又调用了 putVal 方法。在 putVal 方法中,首先根据 key 的 hashCode 返回值决定 Entry 的存储位置。如果有两个 key 的 hash 值相同,则会判断这两个元素 key 的 equals() 是否相同。如果相同,说明是重复键值对,HashSet 的 add 方法会返回 false,表示添加元素失败。如果 key 不重复,put 方法最终会返回 null,表示添加成功。
总结而言,HashSet 底层是由 HashMap 实现的,它可以实现重复元素的去重功能。如果存储的是自定义对象,必须重写 hashCode 和 equals 方法。HashSet 通过在存储之前判断 key 的 hashCode 和 equals 来保证元素的不重复。
java hashset为ä»ä¹çº¿ç¨ä¸å®å ¨
å®å ¨åæççé®é¢
tableè½ç¶çº¿ç¨å®å ¨, ä½æ¯æçåº
æ们å¾å¤æ¶åä¸ä¼èèå°å¤çº¿ç¨çé®é¢, æ以æ£ç¡®çåæ³å°±æ¯å¦æéè¦, 使ç¨æçé«çhashmapèåæ¶èªå·±å»åæ¥, èä¸æ¯ä¸ºäºå°åç¹ç¼ç , èä¸ç®¡éè¦ä¸éè¦åæ¥é½å»ä½¿ç¨æçä½çhashtable