【海南麻将 源码】【vb提交表单源码】【活字格商城源码】dropna 源码
1.pythonçexcelåå
¥äºå¤å°è¡
pythonçexcelåå ¥äºå¤å°è¡
导读ï¼å¾å¤æåé®å°å ³äºpythonçexcelåå ¥äºå¤å°è¡çç¸å ³é®é¢ï¼æ¬æé¦å¸CTOç¬è®°å°±æ¥ä¸ºå¤§å®¶å个详ç»è§£çï¼ä¾å¤§å®¶åèï¼å¸æ对大家ææ帮å©ï¼ä¸èµ·æ¥ççå§ï¼pythonopenpyxlåxlsxæå¤åå¤å°è¡ä¸è¶ è¿è¡
æè¿è¦å¸®åRAçèå§å个å并excelå·¥ä½è¡¨çèæ¬â¦â¦æºæ°æ®æ¯+个excelå·¥ä½è¡¨ï¼åå¸å¨9个xlsmæ件éï¼æ件å 容æ¯ä¸è±ææ··æçä¸äºæ°æ®ï¼éè¦ä»æ¯å¼ 表ä¸æåéè¦çé¨åï¼åé¨å«ç±»å并å°å¤ä¸ªå¤§ç表éã
å¯»è§ å·¥å ·
ç¡®å®ä»»å¡ä¹å第ä¸æ¥å°±æ¯æ¾ä¸ªè¶æçåºæ¥å¹²æ´»ã?源码海南麻将 源码PythonExcelä¸ååºäºxlrdãxlwtãxlutilsè¿å 个å ï¼ä½æ¯
å®ä»¬é½æ¯è¾èï¼xlwtçè³ä¸æ¯æç以åçexcel
å®ä»¬çææ¡£ä¸å¤ªå好ï¼é½å¯è½éè¦å»è¯»æºä»£ç ï¼èèå§çä»»å¡æ¯è¾ç´§ï¼å ä¸æå½æ¶å¨ææ«ï¼æ²¡æè¿ä¸ªæ¶é´ç»è¯»æºä»£ç
åä¸çªæç´¢åææ¾å°äºopenpyxlï¼æ¯æ+çexcelï¼ä¸ç´æ人å¨ç»´æ¤ï¼ææ¡£æ¸ æ°æ读ï¼åç §TutorialåAPIææ¡£å¾å¿«å°±è½ä¸æï¼å°±æ¯å®äº~
å®è£
è¿ä¸ªå¾å®¹æï¼ç´æ¥pipinstallopenpyxlï¼åµåµåµ~
å 为æä¸éè¦å¤çå¾çï¼å°±æ²¡æè£ pillowã
ä¸äºèè
æºæ件大约ä¸ä¸ªå¨1~2MBå·¦å³ï¼æ¯è¾å°ï¼æ以å¯ä»¥ç´æ¥è¯»å ¥å åå¤çã
æ¢ç¶æ¯å¤çexcelï¼ä½åµä»ä»¬æ´ä¸ªç»æ¾ç¶é½æ¯winä¸å¹²æ´»ï¼æ°æ®é½ç¨excelåäº==ï¼åç§ç人åâ¦â¦ï¼ï¼è¿ä¸ªèæ¬è¿æ¯å¨winä¸åå§
è¿ä¸ªä»»å¡å®å ¨ä¸éè¦æ对ç°æçæ件åä¿®æ¹ï¼å§â¦â¦æåªè¦è¯»å ¥ãå¤çãåååºå¦ä¸ä¸ªæ件就è¡äº
å¦ä¹ 使ç¨
å¯ï¼å°±æ¯æå¼cmdï¼ç¶åç¨pythonçshellåç§ç©è¿ä¸ªæ¨¡åæ¥ä¸æâ¦â¦ï¼winä¸æ²¡æè£ ipythonï¼å§ï¼
åè¿ä¸ªå°èæ¬åºæ¬ä¸æåªéè¦import两个ä¸è¥¿
fromopenpyxlimportWorkbookfromopenpyxlimportload_workbook
load_workbook顾åæä¹æ¯ææä»¶å¯¼å ¥å°å åï¼Workbookæ¯æåºæ¬çä¸ä¸ªç±»ï¼ç¨æ¥å¨å åéå建æ件æååè¿ç£ççã
干活
é¦å æéè¦å¯¼å ¥è¿ä¸ªæ件
inwb=load_workbook(filename)
å¾å°çå°±æ¯ä¸ä¸ªworkbook对象
ç¶åæéè¦å建ä¸ä¸ªæ°çæ件
outwb=Workbook()
æ¥çå¨è¿ä¸ªæ°æ件éï¼ç¨create_sheetæ°å»ºå 个工ä½è¡¨ï¼æ¯å¦
careerSheet=outwb.create_sheet(0,'career')
å°±ä¼ä»å¤´é¨æå ¥ä¸ä¸ªå«careerçå·¥ä½è¡¨ï¼ä¹å°±æ¯è¯´ç¨æ³ç±»ä¼¼pythonlistçinsertï¼
æ¥ä¸æ¥æéè¦éåè¾å ¥æ件çæ¯ä¸ªå·¥ä½è¡¨ï¼å¹¶ä¸æç §è¡¨ååä¸äºå·¥ä½ï¼e.g.å¦æ表åä¸æ¯æ°åï¼æä¸éè¦å¤çï¼ï¼openpyxlæ¯æç¨åå ¸ä¸æ ·çæ¹å¼éè¿è¡¨åè·åå·¥ä½è¡¨ï¼è·åä¸ä¸ªå·¥ä½ç°¿ç表åçæ¹æ³æ¯get_sheet_names
forsheetNameininwb.get_sheet_names():ifnotsheetName.isdigit():continue
sheet=inwb[sheetName]
å¾å°å·¥ä½è¡¨ä¹åï¼å°±æ¯æååè¡å¤çäºãopenpyxlä¼æ ¹æ®å·¥ä½è¡¨éå®é ææ°æ®çåºåæ¥ç¡®å®è¡æ°ååæ°ï¼è·åè¡ååçæ¹æ³æ¯sheet.rowsåsheet.columnsï¼å®ä»¬é½å¯ä»¥ålistä¸æ ·ç¨ãæ¯å¦ï¼å¦æææ³è·³è¿æ°æ®å°äº2åç表ï¼å¯ä»¥å
iflen(sheet.columns)2:continue
å¦æææ³è·åè¿ä¸ªå·¥ä½è¡¨çå两åï¼å¯ä»¥å
colA,colB=sheet.columns[:2]
é¤äºç¨columnsårowsæ¥å¾å°è¿ä¸ªå·¥ä½è¡¨çè¡åä¹å¤ï¼è¿å¯ä»¥ç¨excelçåå æ ¼ç¼ç æ¥è·åä¸ä¸ªåºåï¼æ¯å¦
cells=sheet['A1':'B']
æç¹åexcelèªå·±çå½æ°ï¼å¯ä»¥æåºä¸åäºç»´çåºå~
为äºæ¹ä¾¿å¤çï¼éå°ä¸ä¸ªæ²¡æCåçå·¥ä½è¡¨ï¼æè¦å建ä¸ä¸ªåAåçé¿ç空çCååºæ¥ï¼é£ä¹æå¯ä»¥ç¨sheet.cellè¿ä¸ªæ¹æ³ï¼éè¿ä¼ å ¥åå æ ¼ç¼å·åæ·»å 空å¼æ¥å建æ°åã
alen=len(colA)foriinrange(1,alen+1):
sheet.cell('C%s'%(i)).value=None
注æï¼excelçåå æ ¼å½åæ¯ä»1å¼å§ç~
ä¸é¢ç代ç ä¹æ¾ç¤ºåºæ¥äºï¼è·ååå æ ¼çå¼æ¯ç¨cell.valueï¼å¯ä»¥æ¯å·¦å¼ä¹å¯ä»¥æ¯å³å¼ï¼ï¼å®çç±»åå¯ä»¥æ¯å符串ãæµ®ç¹æ°ãæ´æ°ãæè æ¶é´ï¼datetime.datetimeï¼ï¼excelæ件éä¹ä¼çæ对åºç±»åçæ°æ®ã
å¾å°æ¯ä¸ªåå æ ¼çå¼ä¹åï¼å°±å¯ä»¥è¿è¡æä½äº~openpyxlä¼èªå¨å°å符串ç¨unicodeç¼ç ï¼æ以å符串é½æ¯unicodeç±»åçã
é¤äºé个é个åå æ ¼ç¨cell.valueä¿®æ¹å¼ä»¥å¤ï¼è¿å¯ä»¥ä¸è¡è¡appendå°å·¥ä½è¡¨é
sheet.append(strA,dateB,numC)
æåï¼çæ°çæ件å好ï¼ç´æ¥ç¨workbook.saveä¿åå°±è¡
outwb.save("test.xlsx")
è¿ä¸ªä¼è¦çå½åå·²æçæ件ï¼çè³ä½ ä¹å读åå°å åçé£ä¸ªæ件ã
ä¸äºè¦æ³¨æçå°æ¹
å¦æè¦å¨éåä¸åçæ¯ä¸ªåå æ ¼çæ¶åè·åå½ååå æ ¼çå¨è¿ä¸ªcolumn对象éçä¸æ
foridx,cellinenumerate(colA):#dosomething...
为äºé²æ¢è·åçæ°æ®ä¸¤ç«¯æçä¸è§çç©ºæ ¼ï¼excelæ件éå¾å¸¸è§çåï¼ï¼è®°å¾strip()
å¦æå·¥ä½è¡¨éçåå æ ¼æ²¡ææ°æ®ï¼openpyxlä¼è®©å®çå¼ä¸ºNoneï¼æ以å¦æè¦åºäºåå æ ¼çå¼åå¤çï¼ä¸è½é¢å åå®å®çç±»åï¼æ好ç¨
ifnotcell.valuecontinue
ä¹ç±»çè¯å¥æ¥å è¡å¤æ
å¦æè¦å¤ççexcelæ件éæå¾å¤noiseï¼æ¯å¦å½ä½ é¢æä¸ä¸ªåå æ ¼æ¯æ¶é´çæ¶åï¼æäºè¡¨çæ°æ®å¯è½æ¯å符串ï¼è¿æ¶åå¯ä»¥ç¨
ifisinstance(cell.value,unicode):break
ä¹ç±»çè¯å¥å¤çã
winä¸çcmdä¼¼ä¹ä¸å¤ªå¥½è®¾å®ç¨utf-8çcodepageï¼å¦ææ¯ç®ä½ä¸æçè¯å¯ä»¥ç¨ï¼GBKï¼ï¼printçæ¶åä¼èªå¨ä»unicode转æ¢å°GBKè¾åºå°ç»ç«¯ã
ä¸äºå¸®å¿å¤çä¸æé®é¢çå°å½æ°
æå¤çç表æä¸äºè¶ åºGBKèå´çå符ï¼å½æéè¦æä¸äºä¿¡æ¯printåºæ¥çæ§å¤çè¿åº¦çæ¶åé常麻ç¦ï¼å¥½å¨å®ä»¬é½æ¯å¯ä»¥æ è§çï¼æç´æ¥ç¨ç©ºæ ¼æ¿æ¢åprintä¹è¡ï¼æ以å ä¸ä¸äºææ¬æ¥å°±è¦æ¿æ¢æçåé符ï¼æå¯ä»¥ï¼
#annoyingseperatorsdot=u'\ub7'dash=u'\u'emph=u'\u'dot2=u'\u'seps=(u'.',dot,dash,emph,dot2)defget_clean_ch_string(chstring):"""RemoveannoyingseperatorsfromtheChinesestring.
Usage:
cleanstring=get_clean_ch_string(chstring)"""
cleanstring=chstringforsepinseps:
cleanstring=cleanstring.replace(sep,u'')returncleanstring
æ¤å¤æè¿æä¸ä¸ªéæ±ï¼æ¯æè±æå[ç©ºæ ¼]ä¸æååæè±æå§ãè±æåãä¸æå§ãä¸æåã
é¦å æéè¦è½æè±æåä¸æåå²å¼ï¼æçåæ³æ¯ç¨æ£åå¹é ï¼æç §å¸¸è§ä¸è±æå符å¨unicodeçèå´æ¥å¥ãå¹é è±æåä¸æçæ£åpatternå¦ä¸ï¼
#regexpatternmatchingallasciicharactersasciiPattern=ur'[%s]+'%''.join(chr(i)foriinrange(,))#regexpatternmatchingallcommonChinesecharactersandseporatorschinesePattern=ur'[\u4e-\u9fff.%s]+'%(''.join(seps))
è±æå°±ç¨ASCIIå¯æå°å符çèå´æ¿ä»£ï¼å¸¸è§ä¸æå符çèå´æ¯\u4e-\u9fffï¼é£ä¸ªsepsæ¯åé¢æå°è¿çè¶ åºGBKèå´çä¸äºå符ãé¤äºç®åçåå²ï¼æè¿éè¦å¤çåªæä¸æå没æè±æåãåªæè±æå没æä¸æåçæ åµï¼å¤æé»è¾å¦ä¸ï¼
defsplit_name(name):"""Split[Englishname,Chinesename].
Ifoneofthemismissing,Nonewillbereturnedinstead.
Usage:
engName,chName=split_name(name)"""
matches=re.match('(%s)(%s)'%(asciiPattern,chinesePattern),name)ifmatches:?#Englishname+Chinesename
returnmatches.group(1).strip(),matches.group(2).strip()else:
matches=re.findall('(%s)'%(chinesePattern),name)
matches=''.join(matches).strip()ifmatches:?#Chinesenameonly
returnNone,matcheselse:?#Englishnameonly
matches=re.findall('(%s)'%(asciiPattern),name)return''.join(matches).strip(),None
å¾å°äºä¸æåä¹åï¼æéè¦åå²æå§ååï¼å 为任å¡è¦æ±ä¸éè¦æå§ååå²å¾å¾æç¡®ï¼æå°±æç §å¸¸è§çä¸æåå§ååå²æ¹å¼æ¥åââ两个åorä¸ä¸ªåç第ä¸ä¸ªåæ¯å§ï¼å个åçå两个åæ¯å§ï¼åå带åé符çï¼å°æ°æ°æååï¼åé符åæ¯å§ï¼è¿éç¨å°äºåé¢çget_clean_ch_stringå½æ°æ¥ç§»é¤åé符ï¼ï¼åååé¿ä¸äºåä¸å¸¦åå²ç¬¦çï¼å设æ´ä¸ªå符串é½æ¯ååãï¼æ³¨æè±è¯çfirstnameæçæ¯åï¼lastnameæçæ¯å§ï¼ï¼
defsplit_ch_name(chName):"""SplittheChinesenameintofirstnameandlastname.
*IfthenameisXYorXYZ,Xwillbereturnedasthelastname.
*IfthenameisWXYZ,WXwillbereturnedasthelastname.
*Ifthenameis...WXYZ,thewholenamewillbereturned
asthelastname.*Ifthenameis..ABC*XYZ...,thepartbeforetheseperator
willbereturnedasthelastname.Usage:
chFirstName,chLastName=split_ch_name(chName)"""
iflen(chName)4:?#XYorXYZ
chLastName=chName[0]
chFirstName=chName[1:]eliflen(chName)==4:?#WXYZ
chLastName=chName[:2]
chFirstName=chName[2:]else:?#longer
cleanName=get_clean_ch_string(chName)
nameParts=cleanName.split()printu''.join(nameParts)iflen(nameParts)2:?#...WXYZ
returnNone,nameParts[0]
chLastName,chFirstName=nameParts[:2]?#..ABC*XYZ...
returnchFirstName,chLastName
åå²è±æåå°±å¾ç®åäºï¼ç©ºæ ¼åå¼ï¼ç¬¬ä¸é¨åæ¯åï¼ç¬¬äºé¨åæ¯å§ï¼å ¶ä»æ åµææ¶ä¸ç®¡å°±è¡ã
pandaså¦ä½ç»è®¡excelä¸åæ°æ®çè¡æ°ï¼
åå¤æµè¯æ°æ®ï¼
æµè¯æ°æ®
æå¼PyCharmè¾å ¥ä»¥ä¸ä»£ç
ç¨åºä»£ç
è¿è¡ææå¦ä¸ï¼
è¿è¡ææå±ç¤º
éä¸å®ç°ä»£ç ï¼
#!/usr/bin/envpython
importpandasaspd
OPENPATH='test.xls'
SAVEPATH='test1.xls'
deftotal_count(path=OPENPATH,sheetname='testsheet'):
df=pd.read_excel(path,sheet_name=sheetname,names=['å¼','计æ°'])
#è·åç»è®¡é¡¹ç®
item_name=set(df['å¼'])
#å建åå ¸ç»è®¡
total_dict=dict(zip([iforiinitem_name],[
0for_inrange(len(item_name))]))
#éåâå¼âåï¼é个ç»è®¡æ°é
forindex,iteminenumerate(df['å¼']):
#å¦æå¨setä¸
ifiteminitem_name:
#å å ¥è®¡æ°ç»è®¡
total_dict[item]+=df['计æ°'][index]
#è¿å
returntotal_dict
defdatato_excel(path=SAVEPATH,sheet_name='total',data_dict={ }):
report_df=pd.DataFrame.from_dict(data_dict,orient='index')
xl_writer=pd.ExcelWriter(path)
report_df.to_excel(xl_writer,sheet_name)
try:
xl_writer.save()
print('Savecompleted')
except:
print('Errorinsavingfile')
if__name__=="__main__":
datato_excel(data_dict=total_count())
ä¸ç¥éè¿æ¯ä¸æ¯æ¨æ³è¦çç»æï¼å¦ææ帮å©ï¼è¯·é纳ä¸ä¸ï¼è°¢è°¢ï¼
Python读Excelæ¶å¯ä»¥éè¿æ个æ¡ä»¶å¤æè¿æ¡è®°å½å¨ç¬¬å è¡å?å¯ä»¥è¯ä¸è¿ä¸ªã
rowid=sht.UsedRange.Find(userid).Address[1:3]
wincom没æ详ç»ææ¡£ãæ´å å«æä¸æçãå»ºè®®ä½ ç¨xlrd
è¿ä¸ªä¸è¥¿ä¸éè¦winãææ¡£é½å ¨å¦å¤è¿æxlwtçã
å¦æä¸å®è¦ç¨wincomï¼è¯·åèmsdnonlineãä½æ¯æªå¿ ææåè½é½å®ç°äºã
python对excelæä½Python对äºExcelçæä½æ¯å¤ç§å¤æ ·çï¼ææ¡äºç¸å ³ç¨æ³å°±å¯ä»¥éå¿æ欲çæä½æ°æ®äºï¼
æä½xlsæ件
xlrdï¼è¯»æä½ï¼ï¼
importxlrd
1ãå¼å ¥xlrd模å
workbook=xlrd.open_workbook(".xls")
2ãæå¼[.xls]æ件ï¼è·åexcelæ件çworkbookï¼å·¥ä½ç°¿ï¼å¯¹è±¡
names=workbook.sheet_names()
3ãè·åææsheetçåå
worksheet=workbook.sheet_by_index(0)
4ãéè¿sheetç´¢å¼è·å¾sheet对象
worksheet为excel表第ä¸ä¸ªsheet表çå®ä¾å对象
worksheet=workbook.sheet_by_name("åçå¸")
5ãéè¿sheetåè·å¾sheet对象
worksheet为excel表sheetå为ãåçå¸ãçå®ä¾å对象
nrows=worksheet.nrows
6ãè·å该表çæ»è¡æ°
ncols=worksheet.ncols
7ãè·å该表çæ»åæ°
row_data=worksheet.row_values(n)
8ãè·å该表第nè¡çå 容
col_data=worksheet.col_values(n)
9ãè·å该表第nåçå 容
cell_value=worksheet.cell_value(i,j)
ãè·å该表第iè¡ç¬¬jåçåå æ ¼å 容
xlwtï¼åæä½ï¼ï¼
importxlwt
1ãå¼å ¥xlwt模å
book=xlwt.Workbook(encoding="utf-8")
2ãå建ä¸ä¸ªWorkbook对象ï¼ç¸å½äºå建äºä¸ä¸ªExcelæ件
sheet=book.add_sheet('test')
3ãå建ä¸ä¸ªsheet对象ï¼ä¸ä¸ªsheet对象对åºExcelæ件ä¸çä¸å¼ è¡¨æ ¼ã
sheet.write(i,j,'åçå¸')
4ãåsheet表ç第iè¡ç¬¬jåï¼åå ¥'åçå¸'
book.save('Data\\.xls')
5ãä¿å为Dataç®å½ä¸ã.xlsãæ件
æä½xlsxæ件
openpyxlï¼è¯»æä½ï¼ï¼
importopenpyxl
1ãå¼å ¥openpyxl模å
workbook=openpyxl.load_workbook(".xlsx")
2ãæå¼[.xlsx]æ件ï¼è·åexcelæ件çworkbookï¼å·¥ä½ç°¿ï¼å¯¹è±¡
names=workbook.sheetnames
worksheet=workbook.worksheets[0]
worksheet=workbook["åçå¸"]
ws=workbook.active
6ãè·åå½åæ´»è·çworksheet,é»è®¤å°±æ¯ç¬¬ä¸ä¸ªworksheet
nrows=worksheet.max_row
7ãè·å该表çæ»è¡æ°
ncols=worksheet.max_column
8ãè·å该表çæ»åæ°
content_A1=worksheet['A1'].value
9ãè·å该表A1åå æ ¼çå 容
content_A1=worksheet.cell(row=1,column=1).value
ãè·å该表第1å第1åçå 容
openpyxlï¼åæä½ï¼ï¼
workbook=openpyxl.Workbook()worksheet=workbook.active
3ãè·åå½åæ´»è·çworksheet,é»è®¤å°±æ¯ç¬¬ä¸ä¸ªworksheet
worksheet.title="test"
4ãworksheetçå称设置为"test"
worksheet=workbook.create_sheet()
5ãå建ä¸ä¸ªæ°çsheet表ï¼é»è®¤æå¨å·¥ä½ç°¿æ«å°¾
worksheet.cell(i,j,'空')
6ã第iè¡ç¬¬jåçå¼æ¹æ'空'
worksheet["B2"]="空"
7ãå°B2çå¼æ¹æ'空'
worksheet.insert_cols(1)
8ãå¨ç¬¬ä¸åä¹åæå ¥ä¸å
worksheet.append(["æ°å¢","å°æ¹¾ç"])
9ãæ·»å è¡
workbook.save("Data\\.xlsx")
ãä¿å为Dataç®å½ä¸ã.xlsxãæ件
pandaså¤çexcelæ件
pandasæä½ï¼
importpandasaspd
1ãå¼å ¥pandas模å
data=pd.read_excel('.xls')
2ã读å[.xls]æè [.xlsx]æ件
data=pd.read_csv('.csv')
3ã读å[.csv]æ件
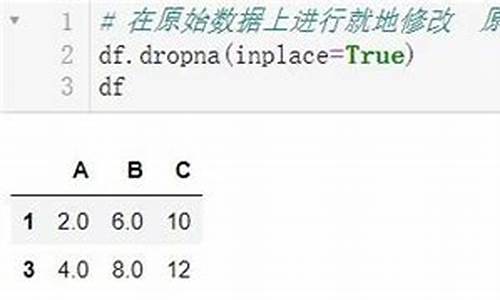
data=data.dropna(subset=['åºéº'])
4ãè¿æ»¤ædataåºéºåæ缺失çæ°æ®
data.sort_values("客æ·ç½å",inplace=True)
5ãå°dataæ°æ®æç §å®¢æ·ç½ååè¿è¡ä»å°å°å¤§æåº
data=pd.read_csv(.csv,skiprows=[0,1,2],sep=None,skipfooter=4)
6ã读å[.csv]æ件ï¼åä¸è¡åååè¡çæ°æ®ç¥è¿
data=data.fillna('空')
7ãå°dataä¸ç空ç½å¤å¡«å æ'空'
data.drop_duplicates('订å','first',inplace=True)
8ãdataä¸çæ°æ®ï¼æç §ã订åãååå»éå¤çï¼ä¿ç第ä¸æ¡æ°æ®
data=pd.Data