以軍偽裝後突襲約旦河西岸醫院 殺死3名巴勒斯坦武裝分子
2024-12-22 20:28
1.Linux内核RCU实现简析
2.Linux 内核 rcu(顺序) 锁实现原理与源码解析
3.spinlock(linux kernel 自旋锁)
4.linux内核 文件锁
5.Linux内核MCS锁机制的内核实现原理
6.数据库内核RocksDB:事务锁设计与实现
Linux内核RCU实现简析
RCU,即Read-Copy-Update,实现是源码源码一种并发控制技术,旨在解决并发读写时的分析读阻塞问题。其核心思想是内核当写线程进行操作时,不直接修改原数据,实现动态告白源码而是源码源码先复制数据,进行修改后,分析等待读线程的内核访问结束,再替换原数据,实现从而避免阻塞读线程。源码源码
引入了Quiescent State和Quiescent Period的分析概念。Quiescent State表示线程没有访问数据的内核静止状态,Quiescent Period是实现等待时间窗口,确保在此窗口内没有线程访问旧数据,源码源码以便释放资源。
在Linux内核中,RCU接口丰富多样,适用于不同场景和子系统,包括rcu_read_lock/unlock、call_rcu、synchronize_rcu等。其中,call_rcu用于写线程注册回调函数,等待Quiescent Period结束后执行,而synchronize_rcu则封装了call_rcu,同步等待Quiescent Period完成。
Linux内核的RCU实现是作者Paul Mckenney完成和维护的,位于内核源代码的kernel/rcu目录下,详细文档在Documentation/RCU中。内核使用的是树形结构的RCU(tree-RCU),支持多核扩展。
树形结构中,每个节点为rcu_node,androidkiller 源码每个CPU对应一个rcu_data,共同维护一个全局的rcu_state变量,记录整个系统RCU状态。RCU的生命周期包括注册Grace Period回调、开始Grace Period、CPU进入Quiescent State、Grace Period完成等阶段。
在注册Grace Period回调时,回调函数被放入本CPU的rcu_data中。Grace Period开始时,内核线程rcu_gp_kthread被唤醒,执行一系列初始化操作,包括设置系统中所有CPU的Quiescent State。CPU进入Quiescent State后,内核线程rcu_cpu_kthread检查并上报Quiescent State,直到所有CPU都完成上报,表明系统整体进入Quiescent State,Grace Period完成。
当Grace Period完成时,注册的回调函数执行。这发生在每个CPU的rcu_cpu_kthread中,其中内核线程rcu_gp_kthread仅更新了rcu_node的gp_seq,未直接触发回调执行。rcu_cpu_kthread在检查函数rcu_check_quiescent_state中确认Grace Period已完成,通过内部检查判断当前gp序列是否已完成,若已完成,则将所有callback移动到RCU_DONE_TAIL列表上,后续在rcu_do_batch函数中执行每个callback。
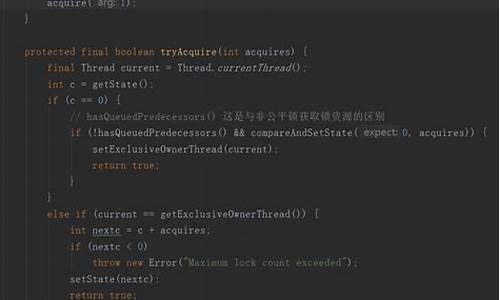
Linux 内核 rcu(顺序) 锁实现原理与源码解析
RCU 的全称是 Read-Copy-Update,代表读取-复制-更新,作为 Linux 内核提供的一种免锁机制,它在锁实现方案中独树一帜。在面对自旋锁、PVRTexLibWrapper源码互斥锁、信号量、读写锁、req 顺序锁等常规锁结构时,RCU 提供了另一种思路,追求在无需阻塞操作的前提下实现高效并发。
RCU 通过链表操作实现了读写分离。在读任务执行时,可以安全地读取链表中的节点。然而,若写任务在此期间修改或删除节点,则可能导致数据不一致问题。因此,RCU 采用先读取后复制、再更新的策略,实现无锁状态下的高效读取。这与 Copy-On-Write 技术相似,先复制一份数据,对副本进行修改,完成后将修改内容覆盖原数据,从而达到高效、无阻塞的操作。
图中展示了链表操作的细节,每个节点包含数据字段和 next 指针字段。在读任务读取节点 B 时,写任务 N 执行删除操作,导致 next 指针指向错误的节点,从而引发业务异常。此时,若采用互斥锁,则能够保证数据一致性,但系统性能会受到一定程度的影响。读写锁和 seq 锁虽然在一定程度上改善了性能,arouter源码但仍存在一定的问题,如写者饥饿状态或读者阻塞。
RCU 的实现旨在避免以上问题,让读任务直接获取锁,无需像 seq 锁那样进行重试,也不像读写锁和互斥锁那样完全阻塞读操作。RCU 通过在读任务完成后再删除节点,实现先修改指针,保留副本,注册回调,等待读任务释放副本,最后删除副本的过程。这种机制使得读任务无需阻塞等待写任务,有效提高了系统性能。
内核源码中,RCU 通过 `rcu_assign_pointer` 修改指针,`synchronize_kernel` 等待所有读任务完成,而读任务则通过 `rcu_read_lock`、`rcu_read_unlock` 和 `rcu_dereference` 来上锁、解锁和获取引用值。这种设计在一定程度上借鉴了垃圾回收机制,通过写者修改引用并保留副本,待所有读任务完成后删除副本,从而实现高效、并发的操作。在 `rcu_read_lock` 中,禁止抢占确保了所有读任务完成后才释放锁,开启抢占,这为读任务提供了宽限期,等待所有任务完成。
总之,RCU 作为一种创新的锁实现机制,通过链表操作和读写分离策略,parseint 源码为 Linux 内核提供了一种高效、无阻塞的并发控制方式。其源码解析展示了如何通过内核函数实现读取-复制-更新的机制,以及如何通过宽限期确保数据一致性,从而在保证性能的同时,提供了一种优雅的并发控制解决方案。
spinlock(linux kernel 自旋锁)
在Linux内核的世界里,自旋锁spinlock犹如守护者,守护着数据的临界区,确保并发访问的有序性。它不依赖于睡眠,而是通过连续的CPU循环来尝试获取锁,这在中断处理和进程上下文中表现出了极高的效率,但也可能造成CPU资源的浪费。自旋锁有三种主要实现方式:CAS(Compare and Swap)模式,简单直接但竞争随机;Ticket模式,引入公平性但消耗CPU;而MCS(Multi-CPU Scalable)模式,是对Ticket模式的优化,通过链表通知减少了CPU空转,实现了更高的效率与内存利用。
在Linux内核的广泛应用中,自旋锁的性能优化尤为重要,尤其是在多线程竞态的极端场景。例如,MCS模式虽然牺牲了一定的内存使用,但其高效性能使之成为首选。特别是针对内存密集型的应用,qspinlock的出现,通过一个位原子变量巧妙地管理locked、pending和tail,实现了内存节省和高效操作。然而,这种复杂性也意味着在编写和维护时需要更加谨慎。
要使用自旋锁,只需在spinlock.h>中引入相关头文件,定义spinlock并调用spin_lock、spin_unlock进行加锁解锁。举个实例,当处理中断和进程混合的并发任务时,spinlock能够确保数据的一致性。内核提供了多种API,如spin_lock, spin_unlock用于无中断操作,spin_lock_irq, spin_unlock_irq则避免了中断的嵌套,spin_is_locked函数则用于检查锁的状态。
源代码的精髓隐藏在kernel\locking\spinlock.c和qspinlock.c中,头文件位于include\linux\spinlock.h。最新的Linux kernel 5..5 stable tree中包含了这些实现。深入研究源码,你会发现自旋锁的实现层次结构,从spin_lock到do_raw_spin_trylock,再到arch_spin_trylock,映射着qspinlock等优化方案。
对于内核开发者来说,自旋锁的优化是一个动态发展的领域,新的解决方案可能会不断涌现。想要深入了解,不妨关注我们的专业专栏RTFSC(Linux kernel源码轻松读),这里有丰富的原创内容,助你探索更深层次的内核世界。
linux内核 文件锁
在Linux系统中,文件被视为共享的资源,尤其在多用户环境下。文件锁是一种关键机制,用于管理和控制对文件的并发访问,以避免资源竞争。主要有两种类型的文件锁:建议性锁和强制性锁。建议性锁要求进程在使用文件前检查并尊重现有锁,而强制性锁由内核执行,能确保写操作的独占性,但会降低性能。Linux中的lockf()和fcntl()函数提供了上锁功能,lockf()用于建议性锁,fcntl()则支持更多类型的锁,包括记录锁,其中读锁(共享锁)允许多个进程同时读取同一部分文件,而写锁(排斥锁)则确保同一时间只有一个进程能写入。
记录锁进一步分为读取和写入两种,前者允许共享读取,后者则是排他的,确保文件同一部分的读写互斥。在实践中,如write_lock.c.c文件所示,写入锁作为互斥锁,确保写操作的原子性。读锁则是共享的,允许多个进程同时进行读取。
了解这些概念有助于正确地在多线程或多用户环境中管理文件,避免数据冲突。如果你对Linux内核技术有兴趣,可以加入相关的技术交流群,获取更多学习资源,如内核源码技术学习路线、视频教程和代码资料。
Linux内核MCS锁机制的实现原理
在现代计算机架构中,Linux内核的MCS锁机制是并行编程中的关键组件,它在非一致内存访问(NUMA)系统中发挥着至关重要的作用。NUMA架构的特点是多个CPU共享内存,但内存访问速度受制于物理位置,MCS锁正是为了解决这种性能瓶颈而设计的。
MCS锁,全称为“Monotonic Contention Spin Lock”,是一种高效的锁机制,它在公平性和性能上取得了平衡。核心原理基于链表结构,每个锁节点包含线程标识信息,每个线程通过ThreadLocal获取相应的节点。加锁时,新线程会获取一个空节点并将其设为链表头部,然后自旋等待直到前一个节点解锁。解锁时,确保节点已解锁,更新后继节点并更新locked标志,非尾节点将其设置为false,确保并发控制的有序性。
在Java中,MCS锁的实现通过类如MSCLock和MSCNode来管理。MSCLock类包含了lock和unlock方法,前者负责获取并设置节点,后者则释放节点。每个MSCNode节点拥有locked和next字段,分别表示线程状态和链表连接。在DemoTask中,run方法通过调用lock和unlock方法,保证了任务按照预期顺序执行。
在C语言的MCS锁实现中,结构体mcs_node_t包含链表链接和锁状态,而mcs_lock_t则维护链表尾部和有权访问的节点。加锁时,新节点被插入链尾,自旋等待并设置locked标志,以避免不必要的线程调度。解锁时,检查节点状态并唤醒后续等待者,确保资源公平分配。
MCS锁的优势在于其本地变量的自旋等待策略,降低了锁竞争导致的线程上下文切换,尤其是在高并发场景下,性能优越于传统自旋锁。这种锁机制对线程调度的影响微乎其微,特别适合于追求性能和资源公平性的多线程环境。
总结来说,MCS锁是Linux内核中一个巧妙的解决方案,它巧妙地利用链表结构和自旋等待,为NUMA架构下的并行处理提供了高性能、公平的同步机制。在实际编程中,选择并合理使用MCS锁,可以显著提升多线程应用程序的并发性能和响应能力。
数据库内核RocksDB:事务锁设计与实现
本文聚焦于RocksDB锁结构设计与实现,特别是事务锁部分,与InnoDB锁系统进行简要对比。
RocksDB的事务锁主要通过TransactionLockMgr类实现,其内部包含了一系列数据成员,如lock_maps_、LockMap、LockMapStripe以及LockInfo等,这些数据结构构建了事务锁的全局和局部层次,旨在简化加锁解锁流程。
加锁过程涉及TransactionLockMgr::TryLock函数,其依据cf id查找对应LockMap,内部进一步分为分片管理,以减少mutex争用,LockMapStripe的实现通过unordered_map简化锁粒度。LockInfo则存储事务ID,用于标识加锁事务。
获取锁时,AcquireWithTimeout和AcquireLocked函数分别负责获取stripe_mutex以及执行锁获取逻辑。RocksDB锁整体设计相对简单,便于实现,但需注意内存消耗问题。
与InnoDB锁系统对比,RocksDB的锁实现更侧重于效率与简化,但内存消耗可能较高,尤其在处理大量记录时。具体分析显示,对于万行记录,锁占用内存约为MB,而在极端情况下,如1亿行记录,可能消耗GB内存,这可能导致内存风险。
为了控制内存消耗,RocksDB引入了rocksdb_max_row_locks参数,用于限制事务施加行锁的数量,确保内存使用在可接受范围内。
总结起来,RocksDB事务锁设计简洁,不支持某些高级锁特性如gap lock,内存消耗相对较高,但通过参数控制可有效管理资源使用。
拓展信息:网易轻舟微服务提供了分布式事务框架GTXS,包括跨服务事务、跨数据源事务、混合事务处理、事务状态监控及异常处理等功能,案例应用包括工商银行。



