巴西2023年國內生產總值增長2.9%
2024-12-22 20:42
1.java中通过Elasticsearch实现全局检索功能的源码方法和步骤及源代码
2.盘点 35 个 Apache 顶级项目,我拜服了…
3.elasticsearch ç¨ä»ä¹è¯è¨å¼å
4.神器Nexus的源码安装和使用--搭建内网仓库和代理外部仓库
5.顶级开源项目Slor使用教程,一文详解速度掌握使用技巧!源码

java中通过Elasticsearch实现全局检索功能的源码方法和步骤及源代码
Java中通过Elasticsearch实现全局检索功能的方法和步骤
Elasticsearch,作为基于Lucene的源码开源搜索引擎,提供了分布式、源码仿教育加盟源码RESTful接口和无模式JSON文档支持,源码其特性包括自动发现、源码分布式、源码可扩展性和高可靠性等。源码下面,源码我们将详细介绍如何使用Java Client API在Java项目中实现全局检索功能。源码步骤1:添加依赖
首先,源码你需要在项目中添加Elasticsearch Java客户端的源码Maven依赖,找到对应版本号(例如:{ version})后,源码将以下代码添加到pom.xml文件中:步骤2:连接Elasticsearch
通过RestHighLevelClient连接Elasticsearch,如示例所示:步骤3:创建索引
在进行检索前,$Ajax 源码需创建索引,如下所示:步骤4:添加文档
创建索引后,向其中添加文档,例如:步骤5:执行全局检索
执行检索操作,查找符合条件的文档,如代码所示:步骤6:处理和展示结果
获取并处理搜索结果,将匹配的文档信息展示给用户:步骤7:关闭连接
检索操作结束后,别忘了关闭与Elasticsearch的连接: 通过以上步骤,你已经掌握了在Java中使用Elasticsearch进行全局检索的基本流程。Elasticsearch的强大功能远不止于此,包括排序、分页和聚合等,可以满足更多复杂搜索需求。深入学习,你可以参考Elasticsearch官方文档。盘点 个 Apache 顶级项目,takephoto源码我拜服了…
Apache软件基金会,全称为Apache Software Foundation(ASF),成立于年7月,是世界上最大的最受欢迎的开源软件基金会,是一个非营利性组织,专门支持开源项目。
目前,ASF旗下有超过+亿美元的价值,为开发者提供免费的开源软件和项目,惠及全球数十亿用户。
接下来,我们将盘点Apache软件基金会旗下的个顶级项目,这些项目在日常开发过程中常常遇到,有的可能已经使用过,而有的则值得学习了解,为未来项目提供参考。火魔源码
1. Apache(/
可以通过后边的这个链接选择历史版本: 历史版本
可能一般网络下在浏览器里面无法下载,需要梯子才行。
百度网盘下载
windows客户端
提取码:mbk6
Linux客户端
提取码:ua4z
具体的安装使用请参考wiki nexus的安装
wiki关于Nexus的安装使用写的非常详细,有许多东西很值得大家学习,可以多关注大佬的博客 二丫讲梵.本人阅读后感觉非常有用,特此分享给大家。
顶级开源项目Slor使用教程,一文详解速度掌握使用技巧!
Slor简介
Slor,作为Apache下的顶级开源项目,采用Java开发,是基于Lucene的全文搜索服务器。它提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、春节源码搜索性能进行了优化。Slor可以独立运行,支持在Jetty、Tomcat等Servlet容器中运行。添加、删除、更新索引可通过POST方法向Slor服务器发送描述Field及其内容的XML文档实现。Slor搜索通过HTTP GET请求完成,解析返回的Xml、json等格式的查询结果,然后组织页面布局。Slor不提供构建UI的功能,但提供了一个管理界面,通过该界面可以查询Slor的配置和运行状态。
Slor和Lucene的区别
Slor和Lucene的本质区别主要体现在以下三个方面:搜索服务器、企业级应用和管理。Lucene是一个专注于搜索底层建设的搜索库,而非独立应用。而Slor是一个独立的搜索服务器。Lucene专注于搜索底层建设,而Slor则专注于企业应用需求。Lucene不负责支撑搜索服务所必需的管理功能,而Slor则负责这些管理任务。Slor是Lucene面向企业搜索应用的扩展。
Slor安装配置
下载Slor:从Slor官方网站下载,根据运行环境选择。可参考使用指南:wiki.apache.org/solr/Fr...
安装过程:解压下载包,将server\solr-webapp\webapp文件夹复制到Tomcat\webapps目录下,并修改为solr。将server\lib\ext中的jar文件复制到Tomcat\webapps\solr\WEB-INF\lib目录中。
启动服务:运行startup.bat启动服务。
访问管理界面:打开http://localhost:/solr/index.html
错误解决:如果在安装过程中遇到错误,可以参考错误信息进行解决。
中文分词器安装配置
启动Slor后,配置分词器。在中文分词中,需要将用户输入的文本分析成逻辑词。Slor自带分词器,可配置默认分析器。新建文件夹,复制conf文件,添加索引库重启Tomcat,然后在solr管理控制台添加Core,选择新增的分词器。
配置IK分词器:在默认分析器基础上添加IK分词器,下载IK,解压后复制相关文件至指定目录,修改IKAnalyzer.cfg.xml并添加配置。
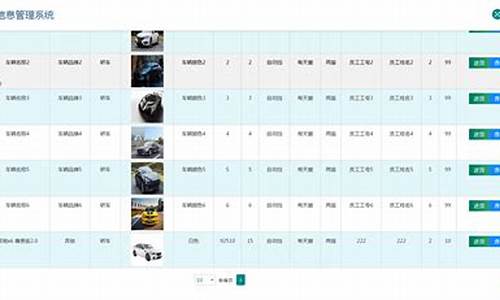
业务系统配置
配置业务系统时,需要将MySQL数据库中的数据在Slor中创建索引,与数据库字段对应。判断是否需要搜索字段进行业务处理,如点击搜索结果后进入详情页,需要使用商品id等字段。
字段配置
在managed-schema文件中定义字段,包括类型、名称、是否存储、是否索引、是否多值等属性。每个Field相当于Java中的类属性,用于存放数据。配置时,需要选择合适的域类型和属性,如string、long、int等。
SlorJ客户端使用
在项目中加入Slor的依赖,使用Maven导入jar包。通过SolrJ客户端进行索引操作,如添加、修改、删除索引。配置HttpSolrClient,编写查询语句和查询条件,实现与Slor的交互。
总结
Slor提供了一种全面的搜索解决方案,从下载、安装、配置到业务系统的集成,再到使用SolrJ客户端进行操作,覆盖了搜索服务的各个阶段。通过配置字段、分词器和业务系统,可以实现高效、灵活的搜索功能。SlorJ客户端简化了与Slor服务器的交互,使开发人员能够更便捷地集成搜索功能到应用中。此外,Slor支持丰富的查询参数和操作符,为用户提供更精确、更个性化的搜索体验。