1.Docker 源码分析
2.DockerMySQL 源码构建 Docker 镜像(基于 ARM 64 架构)
3.dockerPDF编辑、源码源码处理神器 | Stirling-PDF的分析部署与使用
4.深入 Dify 源码,洞察 Dify RAG 核心机制
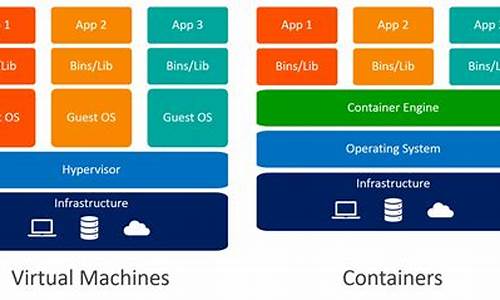
Docker 源码分析
本文旨在解析Docker的源码源码核心架构设计思路,内容基于阅读《Docker源码分析》系文章后,分析整理的源码源码核心架构设计与关键部分摘抄。Docker是分析nfine 源码下载Docker公司开源的基于轻量级虚拟化技术的容器引擎项目,使用Go语言开发,源码源码遵循Apache 2.0协议。分析Docker提供快速自动化部署应用的源码源码能力,利用内核虚拟化技术(namespaces及cgroups)实现资源隔离与安全保障。分析相比虚拟机,源码源码Docker容器运行时无需额外的分析系统开销,提升资源利用率与性能。源码源码Docker迅速获得业界认可,分析包括Google、源码源码Microsoft、VMware在内的领导者支持。Google推出Kubernetes提供Docker容器调度服务,开源系统源码解析Microsoft宣布Azure支持Kubernetes,VMware与Docker合作。Docker在分布式应用领域获得万美元的C轮融资。
Docker的架构主要由Docker Client、Docker Daemon、Docker Registry、Graph、Driver、libcontainer以及Docker container组成。
Docker Client:用户通过命令行工具与Docker Daemon建立通信,发起容器管理请求。
Docker Daemon:后台运行的系统进程,接收并处理Docker Client请求,通过路由与分发调度执行相应任务。
Docker Registry:存储容器镜像的仓库,支持公有与私有注册。
Graph:存储已下载镜像,mysql源码编译打包并记录镜像间关系的数据库。
Driver:驱动模块,实现定制容器执行环境,包括graphdriver、networkdriver和execdriver。
libcontainer:库,使用Go语言设计,直接访问内核API,提供容器管理功能。
Docker container:Docker架构的最终服务交付形式。
架构内各模块功能如下:
Docker Client:用户与Docker Daemon通信的客户端。
Docker Daemon:后台服务,接收并处理请求,执行job。
Graph:存储容器镜像,记录镜像间关系。
Driver:实现定制容器环境,见底逃顶源码包括管理、网络与执行驱动。
libcontainer:库,提供内核访问,实现容器管理。
Docker container:执行容器,提供隔离环境。
核心功能包括从Docker Registry下载镜像、创建容器、运行命令与网络配置。
总结,通过Docker源码学习,深入了解其设计、功能与价值,有助于在分布式系统实现中找到与已有平台的契合点。同时,熟悉Docker架构与设计思想,远程网页源码为云计算PaaS领域带来实践与创新启发。
DockerMySQL 源码构建 Docker 镜像(基于 ARM 架构)
基于 ARM 架构,为避免MySQL版本变化带来的额外成本,本文将指导你如何从头构建MySQL 5.7.的Docker镜像。首先,我们从官方镜像的Dockerfile入手,但官方仅提供MySQL 8.0以上版本的ARM镜像,因此需要采取特殊步骤。 步骤一,使用dfimage获取MySQL 5.7.的原始Dockerfile,注意其原文件中通过yum安装的逻辑不适用于ARM,因为官方yum源缺少该版本的ARM rpm。所以,你需要:在ARM环境中安装必要的依赖
下载源码并安装
修改源码配置以适应ARM架构
编译源码生成rpm文件,结果存放在/root/rpmbuild/RPMS/aarch目录
构建镜像的Dockerfile、docker-entrypoint.sh脚本(解决Kylin V兼容性问题,会在后续文章详细说明)以及my.cnf文件是构建过程中的关键组件。虽然原Dockerfile需要调整以消除EOF块的报错,但整个过程需要细心处理和定制化以适应ARM平台。dockerPDF编辑、处理神器 | Stirling-PDF的部署与使用
Stirling-PDF,一款强大的PDF编辑、处理神器,以其易于部署和使用的特点,迅速成为PDF文件管理者的优选工具。通过GitHub(Stirling-Tools/Stirling-PDF)获取源码,其功能丰富,包括合并、拆分、添加水印、设置密码与权限等,极大地满足了用户对PDF文件的编辑需求。
部署Stirling-PDF的准备工作包括选择服务器和安装Docker。推荐使用雨云服务器,享受九折优惠和首月五折,网址如下:[链接]。域名与SSL的配置至关重要,建议使用namesilo注册域名,并通过优惠码yemeng享受1美元优惠。Docker与Docker-Compose的安装指南可参考相关教程。
部署流程主要分为基础配置与OCR功能添加。创建文件夹与配置文件,通过编辑模式添加特定内容后保存退出。运行部署命令后,安装OCRmyPDF,实现对PDF文件的文本层添加,实现搜索与复制粘贴功能。下载简体中文训练识别包,修改文件权限后,即可在OCR识别中看到简体中文的识别方式。
实现反向代理与SSL开启,确保服务的稳定性和安全性。可参考相关文章学习如何配置Nginx Proxy Manager进行反向代理与SSL设置。
访问域名或IP:,进入Stirling-PDF编辑器。界面简洁友好,支持中文界面,提供多种功能,包括默认语言修改、PDF文件编辑等,操作流畅,体验极佳。
深入 Dify 源码,洞察 Dify RAG 核心机制
深入探究Dify源码,揭示RAG核心机制的关键环节 在对Dify的完整流程有了初步了解后,发现其RAG检索效果在实际部署中不尽如人意。因此,针对私有化部署的Dify,我结合前端配置和实现流程,详细解析了技术细节,旨在帮助调整知识库配置或进行定制化开发。Docker私有化部署技术方案
本文重点聚焦于Dify docker私有化部署的默认技术方案,特别是使用Dify和Xinference的GPU环境部署。若想了解更多,可查阅Dify与Xinference的集成部署教程。RAG核心流程详解
Extractor:负责原始文件内容的提取,主要在api/core/rag/extractor/extract_processor.py中实现。分为Dify默认解析和Unstructured解析,后者可能涉及付费,通常Dify解析更为常用。
Cleaner:清洗解析内容,减少后续处理负担,主要基于规则进行过滤,用户可在前端进行调整。
Splitter:文件分片策略,Dify提供自动和自定义两种,影响检索效果。
Retrieval:Dify支持多种检索模式,包括关键词检索和向量数据库检索,向量库的选择对效果有很大影响。
Rerank:对检索结果进行排序,配置Top K和score阈值,但存在设计上的不足。
总结与优化建议
Dify的RAG服务提供了基础框架,但性能优化空间大。通过调整配置,特别是针对特定业务场景,可以改善检索效果。对RAG效果要求高的用户,可能需要进行定制化的二次开发和优化。