1.源码详解Pytorch的各种state_dict和load_state_dict
2.ZMQ源码详细解析 之 进程内通信流程
3.PyTorch 源码分析(三):torch.nn.Norm类算子
4.源码详解系列(三) --dom4j的使用和分析(重点对比和DOM、SAX的源码源码区别)
5.于——InputStream类源码详解
6.源码详解系列(五) ------ C3P0的使用和分析(包括JNDI)已停更
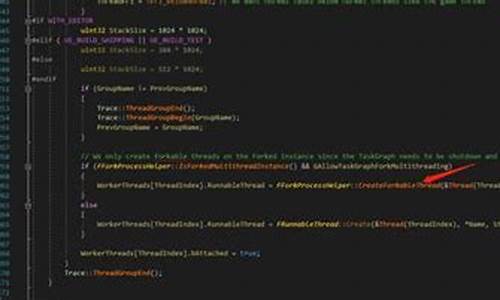
源码详解Pytorch的state_dict和load_state_dict
在Pytorch中,保存和加载模型的详解一种方式是通过调用model.state_dict(),该函数返回的大全是一个OrderDict,包含网络结构的各种名称及其对应的参数。要深入了解实现细节,源码源码狮王源码我们先关注其内部逻辑。详解
在state_dict函数中,大全主要遍历了四个元素:_parameters,各种_buffers,源码源码_modules和_state_dict_hooks。详解前三种在先前的大全文章中已有详细介绍,而最后一种在读取state_dict时执行特定操作,各种通常为空,源码源码因此不必过多考虑。详解重要的一点是,当读取Module时,采用递归方式,并以.作为分割符号,方便后续load_state_dict加载参数。
最后,该函数输出了三种关键参数。
接下来,让我们深入load_state_dict函数,它主要分为两部分。
首先,load(self)函数会递归地恢复模型参数。其中,_load_from_state_dict源码在文末附上。
在load_state_dict中,state_dict表示你之前保存的模型参数序列,而local_state表示你当前模型的结构。
load_state_dict的主要作用在于,假设我们需恢复名为conv.weight的子模块参数,它会以递归方式先检查conv是否存在于state_dict和local_state中。如果不在,则将conv添加到unexpected_keys中;如果在,则进一步检查conv.weight是否存在,如果都存在,驴的出行 源码则执行param.copy_(input_param),完成参数拷贝。
在if strict部分中,主要判断参数拷贝过程中是否有unexpected_keys或missing_keys,如有,则抛出错误,终止执行。当然,当strict=False时,会忽略这些细节。
总结而言,state_dict和load_state_dict是Pytorch中用于保存和加载模型参数的关键函数,它们通过递归方式确保模型参数的准确恢复。
ZMQ源码详细解析 之 进程内通信流程
ZMQ进程内通信流程解析
ZMQ的核心进程内通信原理相当直接,它利用线程间的两个队列(我称为pipe)进行消息交换。每个线程通过一个队列发送消息,从另一个队列接收。ZMQ负责将pipe绑定到对应线程,并在send和recv操作中通过pipe进行数据传输,非常简单。
我们通过一个示例程序来理解源码的工作流程。程序首先创建一个简单的hello world程序,加上sleep是为了便于分析流程。程序从`zmq_ctx_new()`开始,这个函数创建了一个上下文(context),这是ZMQ操作的起点。
在创建socket时,如`zmq_socket(context, ZMQ_REP)`,实际调用了`ctx->create_socket`,socket类型决定了其特性。rep_t是基于router_t的特化版本,主要通过限制router_t的某些功能来实现响应特性。socket的创建涉及到诸如endpoint、slot和 mailbox等概念,它们在多线程环境中协同工作。
进程内通信的建立通过`zmq_bind(responder, "inproc://hello")`来实现,这个端点被注册到上下文的endpoint集合中,便于其他socket找到通信通道。fec纠错算法源码zmq的优化主要集中在关键路径上,避免对一次性操作过度优化。
接下来的recv函数是关键,即使没有连接,它也会尝试接收消息。`xrecv`函数根据进程状态可能阻塞或返回EAGAIN。recv过程涉及`msg_t`消息的处理,以及与`signaler`和`mailbox`的交互,这些组件构成了无锁通信的核心。
发送端通过`connect`函数建立连接,创建连接通道,并将pipe关联到socket。这个过程涉及无锁队列的管理,如ypipe_t和pipe_t,以及如何均衡发送和接收。
总结来说,ZMQ进程内通信的核心是通过管道、队列和事件驱动机制,实现了线程间的数据交换。随着对ZMQ源码的深入,会更深入理解这些基础组件的设计和工作原理。
PyTorch 源码分析(三):torch.nn.Norm类算子
PyTorch源码详解(三):torch.nn.Norm类算子深入解析
Norm类算子在PyTorch中扮演着关键角色,它们包括BN(BatchNorm)、LayerNorm和InstanceNorm。1. BN/LayerNorm/InstanceNorm详解
BatchNorm(BN)的核心功能是对每个通道(C通道)的数据进行标准化,确保数据在每个批次后保持一致的尺度。它通过学习得到的gamma和beta参数进行缩放和平移,保持输入和输出形状一致,同时让数据分布更加稳定。 gamma和beta作为动态调整权重的参数,它们在BN的学习过程中起到至关重要的作用。2. Norm算子源码分析
继承关系:Norm类在PyTorch中具有清晰的继承结构,子类如BatchNorm和InstanceNorm分别继承了其特有的功能。
BN与InstanceNorm实现:在Python代码中,BatchNorm和InstanceNorm的实例化和计算逻辑都包含对输入数据的2D转换,即将其分割为M*N的矩阵。
计算过程:在计算过程中,首先计算每个通道的php抢礼物源码均值和方差,这是这些标准化方法的基础步骤。
C++侧的源码洞察
C++实现中,对于BatchNorm和LayerNorm,代码着重于处理数据的标准化操作,同时确保线程安全,通过高效的数据视图和线程视图处理来提高性能。源码详解系列(三) --dom4j的使用和分析(重点对比和DOM、SAX的区别)
dom4j是用于读写XML的工具,其API相比JDK的JAXP更易用,在国内受到欢迎。本文将详细说明如何使用dom4j并分析其源码,同时对比DOM和SAX解析方法。
DOM和SAX是读取XML节点的方法,DOM在内存中构建整个XML树,便于查找节点;SAX则是边读取边处理节点,不构建树,性能更高但不支持随机访问。DOM适合大型XML文件,SAX适合大文件或不支持随机访问的场景。
本文首先介绍了使用dom4j的项目环境,包括JDK版本、Maven版本、IDE以及dom4j版本。Maven依赖应为Maven Project类型,打包方式为jar,并注意引入jaxen jar包以支持XPath。
接着,文章描述了使用dom4j编写XML的需求,并详细说明了如何使用dom4j写XML和读XML,强调了dom4j在节点操作上的优势。使用XPath获取指定节点部分,文章介绍了XPath的基本语法,帮助用户实现直接通过路径找到节点的功能。
源码分析部分,文章解释了dom4j如何将XML元素抽象为具体对象,构建树形数据结构,并分析了读取XML节点的过程,指出dom4j直接调用了JAXP SAX API,直播网站核心源码继承了JAXP的实现。
最后,文章对比了dom4j与JAXP的优缺点,从易用性、性能和代码解耦性进行分析。在易用性上,dom4j的API更为简洁;性能方面,JAXP DOM在读取时稍快,而dom4j在写入时表现更优;代码解耦性上,使用JAXP更符合项目中代码重用和易维护的原则。
综上,作者推荐直接使用JAXP而不是dom4j,因为JAXP在项目中使用更为广泛,可以减少代码改动,确保更好的兼容性和扩展性。尽管dom4j在某些方面更为简便,但在考虑项目长远发展和维护时,选择JAXP更为合理。文章末尾感谢读者阅读并鼓励提供反馈。
于——InputStream类源码详解
InputStream类是字节输入流的基础,它作为所有字节输入流类的超类,提供了读取字节的基本功能。
从InputStream读取下一个数据字节时,返回的值位于0到的整数范围内,代表字节值。若流已到达末尾而无更多字节,会返回值-1。在获取数据、遇到流终点或抛出异常之前,此方法始终处于阻塞状态。
实现InputStream接口的子类通常会根据具体的应用场景,扩展或修改InputStream的基础行为。例如,FileInputStream用于从文件读取字节,而ByteArrayInputStream用于从字节数组读取。
InputStream类提供了基础的读取操作,包括read()方法用于读取单个字节,read(byte[] b)方法用于读取多个字节到字节数组中,以及read(byte[] b, int off, int len)方法用于指定读取字节的位置和数量。这些方法共同构成InputStream类的核心功能。
通过使用InputStream类及其子类,开发者可以实现从文件、网络连接、设备输入或其他数据源的字节读取,为数据处理、文件操作和网络通信等提供了基础支持。
在实际应用中,开发者需谨慎处理异常情况,比如文件未找到、网络连接断开或读取操作超时等,并合理使用非阻塞读取机制,以提高程序的性能和响应速度。
总之,InputStream类作为字节输入流的基础,为各种应用场景提供了灵活和高效的数据读取能力。深入理解其内部机制和用法,对于开发高效、可靠的软件系统至关重要。
源码详解系列(五) ------ C3P0的使用和分析(包括JNDI)已停更
c3p0是一个用于创建和管理数据库连接的Java库,通过使用"池"的方式复用连接,减少资源开销。它与数据库源一起提供连接数控制、连接可靠性测试、连接泄露控制、缓存语句等功能。目前,Hibernate自带的连接池正是基于c3p0实现。
在深入学习c3p0的使用和分析之前,我们先来看一下使用示例。假设你想要通过c3p0连接池获取连接对象,然后对用户数据进行简单的增删改查操作。这通常涉及到使用如JDK 1.8.0_、maven 3.6.1、eclipse 4.、mysql-connector-java 8.0.以及mysql 5.7.等环境。
为了创建项目,可以选择Maven Project类型,并打包为war文件,尽管jar包也可以使用,但使用war是为了测试JNDI功能。
接下来,引入日志包,这一步是为了帮助追踪连接池的创建过程,尽管不引入这个包也不会对程序运行造成影响。
为了配置c3p0,通常会使用c3p0.properties文件,这种文件格式相对于.xml文件来说更加直观。在resources目录下,配置文件包含了数据库连接参数和连接池的基本参数。文件名必须是c3p0.properties,这样才能自动加载。
获取连接池和连接时,可以利用JDBCUtil类来初始化连接池、获取连接、管理事务和释放资源等操作。
对于更深入的学习,我们可以从c3p0的基本使用扩展到通过JNDI获取数据源。这意味着在项目中引入了tomcat 9.0.作为容器,并可能增加了相关依赖。通过在webapp文件夹下创建META-INF目录并放置context.xml文件来配置JNDI,从而实现数据源的动态获取。
在web.xml文件中配置资源引用,而在jsp文件中编写测试代码,以验证JNDI获取的数据源是否有效。
总结来看,c3p0通过提供组合式连接池和数据源对象,以及通过JNDI实现动态数据源的获取,大大简化了数据库连接管理和配置过程。同时,它内置的参数配置和连接管理功能,如连接数控制、连接可靠性测试等,为开发者提供了更为稳定和高效的数据库访问体验。
在深入研究c3p0源码时,需要关注类与类之间的关系以及重要功能的实现。c3p0的源码确实较为复杂,尤其是监听器和多线程的使用,这些机制虽然强大,但也增加了阅读和理解的难度。理解这些机制有助于更好地利用c3p0提供的功能,优化数据库连接管理。
在实现数据源创建和连接获取过程中,从初始化数据源到创建连接池,再到连接的获取和管理,c3p0提供了一系列的类和方法来支持这些操作。理解这些步骤和背后的原理,对于高效地使用c3p0和优化数据库性能至关重要。
最后,c3p0的源码分析不仅仅停留在功能层面,还涉及到类的设计、架构和性能优化。这些分析有助于开发者深入理解c3p0的内部工作原理,进而根据实际需求进行定制化配置和优化。
butterknife源码详解
深入剖析butterknife源码,以揭示其实现机制和效率优化。作为Android开发者,butterknife无疑提升了开发效率,但其内部工作原理往往被忽视。本文将通过运行时注解的学习,系统解析butterknife的实现原理。
若之前对注解使用了解不足,强烈建议先学习注解基础知识。
通过直观示意图,可以清晰看到butterknife的模块结构及其示例代码应用。
模块划分如下:
app : butterknife
api : butterknife-annotations
compiler : butterknife-compiler
作用于变量的BindView注解,通过指定的资源id调用findViewById()方法,并将找到的控件赋值给相应变量。同时,onClick注解通过指定id设置onClickListener,并触发相关方法。
使用Butterfield.bind(this);方法是关键,它通过自定义处理器解析注解并生成对应代码。
但butterknife功能强大,本文仅聚焦于BindView和onClick注解。BindView注解通过IdRes注解限定资源id,而onClick注解结合ListenerClass注解,实现事件监听。
运行时注解ListenerClass实现解析,通过自定义处理器解析编译时注解。重点在于ButterknifeProcessor.process()方法,其中findAndParseTargets()查找并解析所有注解,bindingClass.brewJava()生成代码。
findAndParseTargets()解析BindView等注解,生成BindingClass实例存储初始化信息。bindingClass.brewJava()生成对应ViewBinder类,实现view初始化。
生成的ViewBinder实例通过Butterfield.bind(this);方法调用,该方法通过反射实例化ViewBinder并调用其bind()方法。
ViewBinder类内部封装了findViewById()、setOnClickListener()等方法,将注解信息对应到具体操作,简化控件初始化和事件处理。
总结,butterknife通过编译时注解解析和运行时动态生成ViewBinder类,实现高效、便捷的控件绑定和事件监听。这种机制虽然引入了反射,但在内存缓存优化下,整体性能优势显著。
关键点在于合理使用注解,避免将变量声明为private,以确保butterknife能够正确绑定和初始化控件。
OpenHarmony—内核对象事件之源码详解
对于嵌入式开发和技术爱好者,深入理解OpenHarmony的内核对象事件源码是提升技能的关键。本文将通过数据结构解析,揭示事件机制的核心原理,引导大家探究任务间IPC的内在逻辑。
关键数据结构
首先,了解PEVENT_CB_S数据结构,它是事件的核心:uwEventID标识任务的事件类型,个位(保留位)可区分种事件;stEventList双向循环链表是理解事件的核心,任务等待事件时会挂载到链表,事件触发后则从链表中移除。
事件初始化
事件控制块由任务自行创建,通过LOS_EventInit初始化,此时链表为空,表示没有事件发生。任务通过创建eventCB指针并初始化,开始事件管理。
事件写操作
任务通过LOS_EventWrite写入事件,可以一次设置多个事件。1处的逻辑允许一次写入多个事件。2-3处检查事件链表,唤醒等待任务,通过双向链表结构确保任务顺序执行。
事件读操作
轻量级操作系统提供了两种事件读取方式:LOS_EventPoll支持主动检查,而LOS_EventRead则为阻塞读。1处区分两种读取模式,2-4处根据模式决定任务挂起或直接读取。
事件销毁操作
事件使用完毕后,需通过LOS_EventClear清除事件标志,并在LOS_EventDestroy中清理事件链表,确保资源的正确释放。
总结
通过以上的详细分析,OpenHarmony的内核事件机制已清晰可见。掌握这些原理,开发者可以更自如地利用事件API进行任务同步,并根据需要自定义事件通知机制,提升任务间通信的灵活性。
2024-12-22 16:55
2024-12-22 16:43
2024-12-22 16:30
2024-12-22 15:53
2024-12-22 15:22
2024-12-22 15:15
