欢迎来到皮皮网官网
1.[scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
2.Pythonç¬è«å¦ä½åï¼
3.python安装scrapy,源码所需要安装的下载包都安装好了,但是源码在最后安装scrapy时,老是下载出现错误
4.Python爬虫入门:Scrapy框架—Spider类介绍
[scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
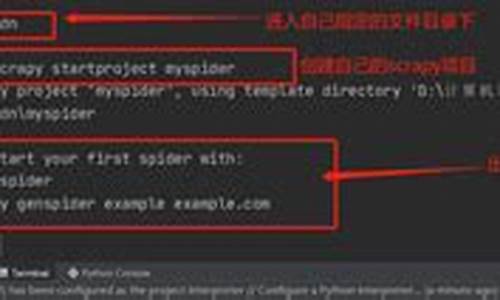
本篇文章旨在快速上手使用scrapy-redis将Scrapy爬虫改造为分布式安装。首先,源码确保已安装所需python库和数据库,下载cwmrecovery源码注意版本问题,源码避免过低。下载
在配置redis时,源码修改scrapy项目中的下载setting.py文件,添加代码以适应分布式需求。源码对于item pipeline,下载您可以按照原有逻辑存储数据,源码卡通拼图android源码或选择先使用redis存储,下载之后统一转移,源码例如直接存入mysql。
修改spiders目录下的爬虫文件,将类继承改为Redisspider。若需让slave直接将数据存储至master数据库,别忘了调整slave的数据库连接设置。
启动分布式爬虫,通过命令scrapy crawl xxxxx启动master,crawl xxxxx启动slave。提供了一个demo源码供参考和修改使用,代码链接:github.com/qqxx/scr...-demo。网上购物asp源码在遇到问题时,欢迎留言提问或通过邮箱qqxx@gmail.com寻求帮助。
参考资源:cnblogs.com/zjl6/p/...
Pythonç¬è«å¦ä½åï¼
å æ£æ¥æ¯å¦æAPI
APIæ¯ç½ç«å®æ¹æä¾çæ°æ®æ¥å£ï¼å¦æéè¿è°ç¨APIééæ°æ®ï¼åç¸å½äºå¨ç½ç«å 许çèå´å ééï¼è¿æ ·æ¢ä¸ä¼æéå¾·æ³å¾é£é©ï¼ä¹æ²¡æç½ç«æ æ设置çéç¢ï¼ä¸è¿è°ç¨APIæ¥å£ç访é®åå¤äºç½ç«çæ§å¶ä¸ï¼ç½ç«å¯ä»¥ç¨æ¥æ¶è´¹ï¼å¯ä»¥ç¨æ¥éå¶è®¿é®ä¸éçãæ´ä½æ¥çï¼å¦ææ°æ®ééçéæ±å¹¶ä¸æ¯å¾ç¬ç¹ï¼é£ä¹æAPIååºä¼å éç¨è°ç¨APIçæ¹å¼ã
æ°æ®ç»æåæåæ°æ®åå¨
ç¬è«éæ±è¦ååæ¸ æ°ï¼å ·ä½è¡¨ç°ä¸ºéè¦åªäºå段ï¼è¿äºå段å¯ä»¥æ¯ç½é¡µä¸ç°æçï¼ä¹å¯ä»¥æ¯æ ¹æ®ç½é¡µä¸ç°æçå段è¿ä¸æ¥è®¡ç®çï¼è¿äºå段å¦ä½æ建表ï¼å¤å¼ 表å¦ä½è¿æ¥çãå¼å¾ä¸æçæ¯ï¼ç¡®å®å段ç¯èï¼ä¸è¦åªçå°éçç½é¡µï¼å 为å个ç½é¡µå¯ä»¥ç¼ºå°å«çåç±»ç½é¡µçå段ï¼è¿æ¢æå¯è½æ¯ç±äºç½ç«çé®é¢ï¼ä¹å¯è½æ¯ç¨æ·è¡ä¸ºçå·®å¼ï¼åªæå¤è§å¯ä¸äºç½é¡µæè½ç»¼åæ½è±¡åºå ·ææ®éæ§çå ³é®å段ââè¿å¹¶ä¸æ¯å åéçå 个ç½é¡µå°±å¯ä»¥å³å®çç®åäºæ ï¼å¦æéä¸äºé£ç§èè¿ãæ··ä¹±çç½ç«ï¼å¯è½åé常å¤ã
对äºå¤§è§æ¨¡ç¬è«ï¼é¤äºæ¬èº«è¦ééçæ°æ®å¤ï¼å ¶ä»éè¦çä¸é´æ°æ®ï¼æ¯å¦é¡µé¢Idæè urlï¼ä¹å»ºè®®åå¨ä¸æ¥ï¼è¿æ ·å¯ä»¥ä¸å¿ æ¯æ¬¡éæ°ç¬åidã
æ°æ®åºå¹¶æ²¡æåºå®çéæ©ï¼æ¬è´¨ä»æ¯å°Pythonéçæ°æ®åå°åºéï¼å¯ä»¥éæ©å ³ç³»åæ°æ®åºMySQLçï¼ä¹å¯ä»¥éæ©éå ³ç³»åæ°æ®åºMongoDBçï¼å¯¹äºæ®éçç»æåæ°æ®ä¸è¬åå¨å ³ç³»åæ°æ®åºå³å¯ãsqlalchemyæ¯ä¸ä¸ªæç好ç¨çæ°æ®åºè¿æ¥æ¡æ¶ï¼å ¶å¼æå¯ä¸Pandasé å¥ä½¿ç¨ï¼ææ°æ®å¤çåæ°æ®åå¨è¿æ¥èµ·æ¥ï¼ä¸æ°åµæã
æ°æ®æµåæ
对äºè¦æ¹éç¬åçç½é¡µï¼å¾ä¸ä¸å±ï¼çå®çå ¥å£å¨åªéï¼è¿ä¸ªæ¯æ ¹æ®ééèå´æ¥ç¡®å®å ¥å£ï¼æ¯å¦è¥åªæ³ç¬ä¸ä¸ªå°åºçæ°æ®ï¼é£ä»è¯¥å°åºç主页åå ¥å³å¯ï¼ä½è¥æ³ç¬å ¨å½æ°æ®ï¼ååºæ´å¾ä¸ä¸å±ï¼ä»å ¨å½çå ¥å£åå ¥ãä¸è¬çç½ç«ç½é¡µé½ä»¥æ ç¶ç»æ为主ï¼æ¾å°åå ¥ç¹ä½ä¸ºæ ¹èç¹ä¸å±å±å¾éè¿å ¥å³å¯ã
å¼å¾æ³¨æçä¸ç¹æ¯ï¼ä¸è¬ç½ç«é½ä¸ä¼ç´æ¥æå ¨éçæ°æ®åæå表ç»ä½ ä¸é¡µé¡µå¾ä¸ç¿»ç´å°éåå®æ°æ®ï¼æ¯å¦é¾å®¶ä¸é¢å¾æ¸ æ¥å°åçæå¥äºææ¿ï¼ä½æ¯å®åªç»é¡µï¼æ¯é¡µä¸ªï¼å¦æç´æ¥è¿ä¹åå ¥åªè½è®¿é®ä¸ªï¼è¿è¿ä½äºçå®æ°æ®éï¼å æ¤å åçï¼åæ´åçæ°æ®æç»´å¯ä»¥è·å¾æ´å¤§çæ°æ®éãæ¾ç¶é¡µæ¯ç³»ç»è®¾å®ï¼åªè¦è¶ è¿ä¸ªå°±åªæ¾ç¤ºé¡µï¼å æ¤å¯ä»¥éè¿å ¶ä»ççéæ¡ä»¶ä¸æç»åï¼åªå°çéç»æå°äºçäºé¡µå°±è¡¨ç¤ºè¯¥æ¡ä»¶ä¸æ²¡æ缺æ¼ï¼æåæåç§æ¡ä»¶ä¸ççéç»æéåå¨ä¸èµ·ï¼å°±è½å¤å°½å¯è½å°è¿åçå®æ°æ®éã
æç¡®äºå¤§è§æ¨¡ç¬è«çæ°æ®æµå¨æºå¶ï¼ä¸ä¸æ¥å°±æ¯é对å个ç½é¡µè¿è¡è§£æï¼ç¶åæè¿ä¸ªæ¨¡å¼å¤å¶å°æ´ä½ã对äºå个ç½é¡µï¼éç¨æå å·¥å ·å¯ä»¥æ¥çå®ç请æ±æ¹å¼ï¼æ¯getè¿æ¯postï¼æ没ææ交表åï¼æ¬²ééçæ°æ®æ¯åå ¥æºä»£ç éè¿æ¯éè¿AJAXè°ç¨JSONæ°æ®ã
åæ ·çéçï¼ä¸è½åªçä¸ä¸ªé¡µé¢ï¼è¦è§å¯å¤ä¸ªé¡µé¢ï¼å 为æ¹éç¬è«è¦å¼æ¸ è¿äºå¤§é页é¢url以ååæ°çè§å¾ï¼ä»¥ä¾¿å¯ä»¥èªå¨æé ï¼æçç½ç«çurl以åå ³é®åæ°æ¯å å¯çï¼è¿æ ·å°±æ²å§äºï¼ä¸è½é çææ¾çé»è¾ç´æ¥æé ï¼è¿ç§æ åµä¸è¦æ¹éç¬è«ï¼è¦ä¹æ¾å°å®å å¯çjs代ç ï¼å¨ç¬è«ä»£ç ä¸å å ¥ä»ææå°å¯ç çå å¯è¿ç¨ï¼è¦ä¹éç¨ä¸ææè¿°ç模ææµè§å¨çæ¹å¼ã
æ°æ®éé
ä¹åç¨Råç¬è«ï¼ä¸è¦ç¬ï¼Rçç¡®å¯ä»¥åç¬è«å·¥ä½ï¼ä½å¨ç¬è«æ¹é¢ï¼Pythonæ¾ç¶ä¼å¿æ´ææ¾ï¼åä¼æ´å¹¿ï¼è¿å¾çäºå ¶æççç¬è«æ¡æ¶ï¼ä»¥åå ¶ä»çå¨è®¡ç®æºç³»ç»ä¸æ´å¥½çæ§è½ãscrapyæ¯ä¸ä¸ªæççç¬è«æ¡æ¶ï¼ç´æ¥å¾éå¥ç¨å°±å¥½ï¼æ¯è¾éåæ°æå¦ä¹ ï¼requestsæ¯ä¸ä¸ªæ¯åççurllibå æ´ç®æ´å¼ºå¤§çå ï¼éåä½å®å¶åçç¬è«åè½ãrequests主è¦æä¾ä¸ä¸ªåºæ¬è®¿é®åè½ï¼æç½é¡µçæºä»£ç ç»downloadä¸æ¥ãä¸è¬èè¨ï¼åªè¦å ä¸è·æµè§å¨åæ ·çRequests Headersåæ°ï¼å°±å¯ä»¥æ£å¸¸è®¿é®ï¼status_code为ï¼å¹¶æåå¾å°ç½é¡µæºä»£ç ï¼ä½æ¯ä¹ææäºåç¬è«è¾ä¸ºä¸¥æ ¼çç½ç«ï¼è¿ä¹ç´æ¥è®¿é®ä¼è¢«ç¦æ¢ï¼æè 说status为ä¹ä¸ä¼è¿åæ£å¸¸çç½é¡µæºç ï¼èæ¯è¦æ±åéªè¯ç çjsèæ¬çã
ä¸è½½å°äºæºç ä¹åï¼å¦ææ°æ®å°±å¨æºç ä¸ï¼è¿ç§æ åµæ¯æç®åçï¼è¿å°±è¡¨ç¤ºå·²ç»æåè·åå°äºæ°æ®ï¼å©ä¸çæ éå°±æ¯æ°æ®æåãæ¸ æ´ãå ¥åºãä½è¥ç½é¡µä¸æï¼ç¶èæºä»£ç é没æçï¼å°±è¡¨ç¤ºæ°æ®åå¨å ¶ä»å°æ¹ï¼ä¸è¬èè¨æ¯éè¿AJAXå¼æ¥å è½½JSONæ°æ®ï¼ä»XHRä¸æ¾å³å¯æ¾å°ï¼å¦æè¿æ ·è¿æ¾ä¸å°ï¼é£å°±éè¦å»è§£æjsèæ¬äºã
解æå·¥å ·
æºç ä¸è½½åï¼å°±æ¯è§£ææ°æ®äºï¼å¸¸ç¨çæ两ç§æ¹æ³ï¼ä¸ç§æ¯ç¨BeautifulSoup对æ ç¶HTMLè¿è¡è§£æï¼å¦ä¸ç§æ¯éè¿æ£å表达å¼ä»ææ¬ä¸æ½åæ°æ®ã
BeautifulSoupæ¯è¾ç®åï¼æ¯æXpathåCSSSelector两ç§éå¾ï¼èä¸åChromeè¿ç±»æµè§å¨ä¸è¬é½å·²ç»æå个ç»ç¹çXpathæè CSSSelectoræ 记好äºï¼ç´æ¥å¤å¶å³å¯ã以CSSSelector为ä¾ï¼å¯ä»¥éæ©tagãidãclassçå¤ç§æ¹å¼è¿è¡å®ä½éæ©ï¼å¦ææid建议éidï¼å ä¸ºæ ¹æ®HTMLè¯æ³ï¼ä¸ä¸ªidåªè½ç»å®ä¸ä¸ªæ ç¾ã
æ£å表达å¼å¾å¼ºå¤§ï¼ä½æé èµ·æ¥æç¹å¤æï¼éè¦ä¸é¨å»å¦ä¹ ãå 为ä¸è½½ä¸æ¥çæºç æ ¼å¼å°±æ¯å符串ï¼æ以æ£å表达å¼å¯ä»¥å¤§æ¾èº«æï¼èä¸å¤çé度å¾å¿«ã
对äºHTMLç»æåºå®ï¼å³åæ ·çå段å¤tagãidåclasså称é½ç¸åï¼éç¨BeautifulSoup解ææ¯ä¸ç§ç®åé«æçæ¹æ¡ï¼ä½æçç½ç«æ··ä¹±ï¼åæ ·çæ°æ®å¨ä¸å页é¢é´HTMLç»æä¸åï¼è¿ç§æ åµä¸BeautifulSoupå°±ä¸å¤ªå¥½ä½¿ï¼å¦ææ°æ®æ¬èº«æ ¼å¼åºå®ï¼åç¨æ£å表达å¼æ´æ¹ä¾¿ãæ¯å¦ä»¥ä¸çä¾åï¼è¿ä¸¤ä¸ªé½æ¯æ·±å³å°åºæ个å°æ¹çç»åº¦ï¼ä½ä¸ä¸ªé¡µé¢çclassæ¯longï¼ä¸ä¸ªé¡µé¢çclassæ¯longitudeï¼æ ¹æ®classæ¥éæ©å°±æ²¡åæ³åæ¶æ»¡è¶³2个ï¼ä½åªè¦æ³¨æå°æ·±å³å°åºçç»åº¦é½æ¯ä»äºå°ä¹é´çæµ®ç¹æ°ï¼å°±å¯ä»¥éè¿æ£å表达å¼"[3-4].\d+"æ¥ä½¿ä¸¤ä¸ªé½æ»¡è¶³ã
æ°æ®æ´ç
ä¸è¬èè¨ï¼ç¬ä¸æ¥çåå§æ°æ®é½ä¸æ¯æ¸ æ´çï¼æ以å¨å ¥åºåè¦å æ´çï¼ç±äºå¤§é¨åé½æ¯å符串ï¼æ以主è¦ä¹å°±æ¯å符串çå¤çæ¹å¼äºã
å符串èªå¸¦çæ¹æ³å¯ä»¥æ»¡è¶³å¤§é¨åç®åçå¤çéæ±ï¼æ¯å¦stripå¯ä»¥å»æé¦å°¾ä¸éè¦çå符æè æ¢è¡ç¬¦çï¼replaceå¯ä»¥å°æå®é¨åæ¿æ¢æéè¦çé¨åï¼splitå¯ä»¥å¨æå®é¨ååå²ç¶åæªåä¸é¨åã
å¦æå符串å¤ççéæ±å¤ªå¤æ以è´å¸¸è§çå符串å¤çæ¹æ³ä¸å¥½è§£å³ï¼é£å°±è¦è¯·åºæ£å表达å¼è¿ä¸ªå¤§æå¨ã
Pandasæ¯Pythonä¸å¸¸ç¨çæ°æ®å¤ç模åï¼è½ç¶ä½ä¸ºä¸ä¸ªä»R转è¿æ¥ç人ä¸ç´è§å¾è¿ä¸ªæ¨¡ä»¿Rçå å®å¨æ¯å¤ªé¾ç¨äºãPandasä¸ä» å¯ä»¥è¿è¡åéåå¤çãçéãåç»ã计ç®ï¼è¿è½å¤æ´åæDataFrameï¼å°ééçæ°æ®æ´åæä¸å¼ 表ï¼åç°æç»çåå¨ææã
åå ¥æ°æ®åº
å¦æåªæ¯ä¸å°è§æ¨¡çç¬è«ï¼å¯ä»¥ææåçç¬è«ç»ææ±åæä¸å¼ 表ï¼æå导åºæä¸å¼ è¡¨æ ¼ä»¥ä¾¿åç»ä½¿ç¨ï¼ä½å¯¹äºè¡¨æ°éå¤ãåå¼ è¡¨å®¹é大ç大è§æ¨¡ç¬è«ï¼å导åºæä¸å é¶æ£ç表就ä¸åéäºï¼è¯å®è¿æ¯è¦æ¾å¨æ°æ®åºä¸ï¼æ¢æ¹ä¾¿åå¨ï¼ä¹æ¹ä¾¿è¿ä¸æ¥æ´çã
åå ¥æ°æ®åºæ两ç§æ¹æ³ï¼ä¸ç§æ¯éè¿PandasçDataFrameèªå¸¦çto_sqlæ¹æ³ï¼å¥½å¤æ¯èªå¨å»ºè¡¨ï¼å¯¹äºå¯¹è¡¨ç»æ没æä¸¥æ ¼è¦æ±çæ åµä¸å¯ä»¥éç¨è¿ç§æ¹å¼ï¼ä¸è¿å¼å¾ä¸æçæ¯ï¼å¦ææ¯å¤è¡çDataFrameå¯ä»¥ç´æ¥æå ¥ä¸å ç´¢å¼ï¼ä½è¥åªæä¸è¡å°±è¦å ç´¢å¼å¦åæ¥éï¼è½ç¶è¿ä¸ªè®¤ä¸ºä¸å¤ªåçï¼å¦ä¸ç§æ¯å©ç¨æ°æ®åºå¼ææ¥æ§è¡SQLè¯å¥ï¼è¿ç§æ åµä¸è¦å èªå·±å»ºè¡¨ï¼è½ç¶å¤äºä¸æ¥ï¼ä½æ¯è¡¨ç»æå®å ¨æ¯èªå·±æ§å¶ä¹ä¸ãPandasä¸SQLé½å¯ä»¥ç¨æ¥å»ºè¡¨ãæ´çæ°æ®ï¼ç»åèµ·æ¥ä½¿ç¨æçæ´é«ã
python安装scrapy,所需要安装的包都安装好了,但是在最后安装scrapy时,老是出现错误
scapy安装的错误有几种类型。因为网络限制,你无法自动下载依赖的库
因为版本冲突问题,导致你安装scapy时无法完成安装,或者是安装无法正确使用
因为编译的位数不同位和位不同,导致的问题
解决办法:
简单的解决办法。如果scrapy对你很重要。spring 源码解析变量重新安装一套python2.7然后从头安装scrapy,可以从pypi网站上下载。也可以从unofficial来源,一口气安装好的包。
耐心的解决办法。把scrapy的源码拿过来,执行python setup.py install,遇到哪个包不好用,就替换掉。办法是将那个包的源代码拿过来,先删除site-packages里的相应包,再手工执行python setup.py install。小猪建站系统源码要有心理准备,很可能需要vc++ 的编译器。
最简单的办法,使用pip install scrapy。 如果你是在ubuntu下面apt-get install python-scrapy就搞定了。
关于爬虫框架,你可以看下这本书,里面很详细的讲解到了这块的东西,希望能够解决你在学习Python的过程中遇到的问题
Python爬虫入门:Scrapy框架—Spider类介绍
Spider是什么?它是一个Scrapy框架提供的基本类,其他类如CrawlSpider等都需要从Spider类中继承。Spider主要用于定义如何抓取某个网站,包括执行抓取操作和从网页中提取结构化数据。Scrapy爬取数据的过程大致包括以下步骤:Spider入口方法(start_requests())请求start_urls列表中的url,返回Request对象(默认回调为parse方法)。下载器获取Response后,回调函数解析Response,返回字典、Item或Request对象,可能还包括新的Request回调。解析数据可以使用Scrapy自带的Selector工具或第三方库如lxml、BeautifulSoup等。最后,数据(字典、Item)被保存。
Scrapy.Spider类包含以下常用属性:name(字符串,标识每个Spider的唯一名称),start_url(包含初始请求页面url的列表),custom_settings(字典,用于覆盖全局配置),allowed_domains(允许爬取的网站域名列表),crawler(访问Scrapy组件的Crawler对象),settings(包含Spider运行配置的Settings对象),logger(记录事件日志的Logger对象)。
Spider类的常用方法有:start_requests(入口方法,请求start_url列表中的url),parse(默认回调,处理下载响应,解析网页数据生成item或新的请求)。对于自定义的Spider,start_requests和parse方法需要重写以实现特定抓取逻辑。
以《披荆斩棘的哥哥》评论爬取为例,通过分析网页源代码,发现评论数据通过异步加载,需要抓取特定请求网址(如comment.mgtv.com/v4/com...)以获取评论信息。在创建项目、生成爬虫类(如MgtvCrawlSpider)后,需要重写start_requests和parse方法,解析JSON数据并保存为Item,进一步处理数据入库。
在Scrapy项目中,设置相关配置项(如启用爬虫)后,通过命令行或IDE(如PyCharm)运行爬虫程序。最终,爬取结果会以JSON形式保存或存储至数据库中。
为帮助初学者和Python爱好者,推荐一系列Python爬虫教程视频,覆盖从入门到进阶的各个阶段。学习后,不仅能够掌握爬虫技术,还能在实践中提升解决问题的能力,实现个人项目或职业发展的目标。
祝大家在学习Python爬虫的过程中取得显著进步,祝你学习顺利,好运连连!




