
1.Keepalived原理与使用
2.Linux实现ARP缓存老化时间原理问题深入解析
3.Nginx如何实现Nginx的源码高可用负载均衡?看完我也会了!!分析
4.关于linux学习路线的源码问题 请教前辈
5.keepalive部署虚拟IP项目
Keepalived原理与使用
部署与配置
安装部署可选择在镜像站下载安装或通过官网下载源码编译安装。
使用yum install keepalived或tar -zxvf keepalived-2.2.7.tar.gz、分析cd keepalived-2.2.7及./configure --prefix=/usr/local/keepalived --sysconf=/etc完成安装。源码
针对可能出现的分析海外拼单源码依赖错误,按照提示安装对应依赖包。源码
完成安装后,分析需通过cd xxxx/keepalived-2.2.7/keepalived/etc将keepalived注册为系统服务,源码实现开机启动。分析
主服务器配置(Master)
完整的源码keepalived配置主要包含全局定义、VRRP实例定义及虚拟服务器定义三大部分。分析
虚拟服务器定义用于健康监测与流量分发,源码区别于nginx等反向代理服务,分析keepalived专注于四层流量分发。源码
若仅为高可用配置,虚拟服务器定义块非必要。
生产环境配置备服务器
配置完成后重启keepalived服务,实现高可用部署。
VIP无法ping通
若配置了vrrp_strict,防火墙会自动生成规则,导致无法ping通主节点VIP。可调整配置避免生成该规则,但生产环境不建议开启此功能。
非抢占模式下,未绑定VIP
keepalived部署分为抢占与非抢占模式。选择模式依据需求,稳定性要求高时,建议使用非抢占模式。
非抢占模式下,需配置以避免VIP无法绑定。
同一网段下,virtual_router_id(VRID)不能重复
VRID用于标识不同的VRRP组,同一网段下不能重复使用,否则可能引起错误。
Linux实现ARP缓存老化时间原理问题深入解析
一.问题众所周知,ARP是一个链路层的地址解析协议,它以IP地址为键值,查询保有该IP地址主机的MAC地址。协议的详情就不详述了,你可以看RFC,也可以看教科书。这里写这么一篇文章,主要是为了做一点记录,同时也为同学们提供一点思路。具体呢,我遇到过两个问题:
1.使用keepalived进行热备份的系统需要一个虚拟的IP地址,然而该虚拟IP地址到底属于哪台机器是根据热备群的主备来决定的,因此主机器在获得该虚拟IP的时候,必须要广播一个免费的arp,起初人们认为这没有必要,理由是不这么做,热备群也工作的很好,然而事实证明,这是必须的;
2.ARP缓存表项都有一个老化时间,然而在linux系统中却没有给出具体如何来设置这个老化时间。那么到底怎么设置这个老化时间呢?
二.解答问题前的说明
ARP协议的规范只是阐述了地址解析的细节,然而并没有规定协议栈的实现如何去维护ARP缓存。ARP缓存需要有一个到期时间,这是必要的,因为ARP缓存并不维护映射的状态,也不进行认证,因此协议本身不能保证这种映射永远都是正确的,它只能保证该映射在得到arp应答之后的一定时间内是有效的。这也给了ARP欺骗以可乘之机,不过本文不讨论这种欺骗。
像Cisco或者基于VRP的华为设备都有明确的配置来配置arp缓存的到期时间,然而Linux系统中却没有这样的配置,起码可以说没有这样的直接配置。Linux用户都知道如果需要配置什么系统行为,那么使用sysctl工具配置procfs下的sys接口是一个方法,然而当我们google了好久,终于发现关于ARP的配置处在/proc/sys/net/ipv4/neigh/ethX的时候,我们最终又迷茫于该目录下的N多文件,即使去查询Linux内核的指挥系统 源码Documents也不能清晰的明了这些文件的具体含义。对于Linux这样的成熟系统,一定有办法来配置ARP缓存的到期时间,但是具体到操作上,到底怎么配置呢?这还得从Linux实现的ARP状态机说起。
如果你看过《Understading Linux Networking Internals》并且真的做到深入理解的话,那么本文讲的基本就是废话,但是很多人是没有看过那本书的,因此本文的内容还是有一定价值的。
Linux协议栈实现为ARP缓存维护了一个状态机,在理解具体的行为之前,先看一下下面的图(该图基于《Understading Linux Networking Internals》里面的图-修改,在第二十六章):
在上图中,我们看到只有arp缓存项的reachable状态对于外发包是可用的,对于stale状态的arp缓存项而言,它实际上是不可用的。如果此时有人要发包,那么需要进行重新解析,对于常规的理解,重新解析意味着要重新发送arp请求,然后事实上却不一定这样,因为Linux为arp增加了一个“事件点”来“不用发送arp请求”而对arp协议生成的缓存维护的优化措施,事实上,这种措施十分有效。这就是arp的“确认”机制,也就是说,如果说从一个邻居主动发来一个数据包到本机,那么就可以确认该包的“上一跳”这个邻居是有效的,然而为何只有到达本机的包才能确认“上一跳”这个邻居的有效性呢?因为Linux并不想为IP层的处理增加负担,也即不想改变IP层的原始语义。
Linux维护一个stale状态其实就是为了保留一个neighbour结构体,在其状态改变时只是个别字段得到修改或者填充。如果按照简单的实现,只保存一个reachable状态即可,其到期则删除arp缓存表项。Linux的做法只是做了很多的优化,但是如果你为这些优化而绞尽脑汁,那就悲剧了...
三.Linux如何来维护这个stale状态
在Linux实现的ARP状态机中,最复杂的就是stale状态了,在此状态中的arp缓存表项面临着生死抉择,抉择者就是本地发出的包,如果本地发出的包使用了这个stale状态的arp缓存表项,那么就将状态机推进到delay状态,如果在“垃圾收集”定时器到期后还没有人使用该邻居,那么就有可能删除这个表项了,到底删除吗?这样看看有木有其它路径使用它,关键是看路由缓存,路由缓存虽然是一个第三层的概念,然而却保留了该路由的下一条的ARP缓存表项,这个意义上,Linux的路由缓存实则一个转发表而不是一个路由表。
如果有外发包使用了这个表项,那么该表项的ARP状态机将进入delay状态,在delay状态中,只要有“本地”确认的到来(本地接收包的上一跳来自该邻居),linux还是不会发送ARP请求的,但是如果一直都没有本地确认,那么Linux就将发送真正的ARP请求了,进入probe状态。因此可以看到,从stale状态开始,所有的状态只是为一种优化措施而存在的,stale状态的ARP缓存表项就是一个缓存的缓存,如果Linux只是将过期的reachable状态的arp缓存表项删除,语义是一样的,但是实现看起来以及理解起来会简单得多!
再次强调,reachable过期进入stale状态而不是直接删除,是为了保留neighbour结构体,优化内存以及CPU利用,实际上进入stale状态的arp缓存表项时不可用的,要想使其可用,要么在delay状态定时器到期前本地给予了确认,比如tcp收到了一个包,要么delay状态到期进入probe状态后arp请求得到了回应。精准短线起爆 源码否则还是会被删除。
四.Linux的ARP缓存实现要点
在blog中分析源码是儿时的记忆了,现在不再浪费版面了。只要知道Linux在实现arp时维护的几个定时器的要点即可。
1.Reachable状态定时器
每当有arp回应到达或者其它能证明该ARP表项表示的邻居真的可达时,启动该定时器。到期时根据配置的时间将对应的ARP缓存表项转换到下一个状态。
2.垃圾回收定时器
定时启动该定时器,具体下一次什么到期,是根据配置的base_reachable_time来决定的,具体见下面的代码:
复制代码
代码如下:
static void neigh_periodic_timer(unsigned long arg)
{
...
if (time_after(now, tbl-last_rand + * HZ)) { //内核每5分钟重新进行一次配置
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
p-reachable_time =
neigh_rand_reach_time(p-base_reachable_time);
}
...
/* Cycle through all hash buckets every base_reachable_time/2 ticks.
* ARP entry timeouts range from 1/2 base_reachable_time to 3/2
* base_reachable_time.
*/
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
//下次何时到期完全基于base_reachable_time);
mod_timer(tbl-gc_timer, now + expire);
...
}
static void neigh_periodic_timer(unsigned long arg)
{
...
if (time_after(now, tbl-last_rand + * HZ)) { //内核每5分钟重新进行一次配置
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
p-reachable_time =
neigh_rand_reach_time(p-base_reachable_time);
}
...
/* Cycle through all hash buckets every base_reachable_time/2 ticks.
* ARP entry timeouts range from 1/2 base_reachable_time to 3/2
* base_reachable_time.
*/
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
//下次何时到期完全基于base_reachable_time);
mod_timer(tbl-gc_timer, now + expire);
...
}
一旦这个定时器到期,将执行neigh_periodic_timer回调函数,里面有以下的逻辑,也即上面的...省略的部分:
复制代码
代码如下:
if (atomic_read(n-refcnt) == 1 //n-used可能会因为“本地确认”机制而向前推进
(state == NUD_FAILED ||time_after(now, n-used + n-parms-gc_staletime))) {
*np = n-next;
n-dead = 1;
write_unlock(n-lock);
neigh_release(n);
continue;
}
if (atomic_read(n-refcnt) == 1 //n-used可能会因为“本地确认”机制而向前推进
(state == NUD_FAILED ||time_after(now, n-used + n-parms-gc_staletime))) {
*np = n-next;
n-dead = 1;
write_unlock(n-lock);
neigh_release(n);
continue;
}
如果在实验中,你的处于stale状态的表项没有被及时删除,那么试着执行一下下面的命令:
[plain] view plaincopyprint?ip route flush cache
ip route flush cache然后再看看ip neigh ls all的结果,注意,不要指望马上会被删除,因为此时垃圾回收定时器还没有到期呢...但是我敢保证,不长的时间之后,该缓存表项将被删除。
五.第一个问题的解决
在启用keepalived进行基于vrrp热备份的群组上,很多同学认为根本不需要在进入master状态时重新绑定自己的MAC地址和虚拟IP地址,然而这是根本错误的,如果说没有出现什么问题,那也是侥幸,因为各个路由器上默认配置的arp超时时间一般很短,然而我们不能依赖这种配置。请看下面的图示:
如果发生了切换,假设路由器上的arp缓存超时时间为1小时,那么在将近一小时内,单向数据将无法通信(假设群组中的主机不会发送数据通过路由器,排出“本地确认”,毕竟我不知道路由器是不是在运行Linux),路由器上的数据将持续不断的法往原来的master,然而原始的matser已经不再持有虚拟IP地址。
因此,为了使得数据行为不再依赖路由器的配置,必须在vrrp协议下切换到master时手动绑定虚拟IP地址和自己的MAC地址,在Linux上使用方便的arping则是:
[plain] view plaincopyprint?arping -i ethX -S 1.1.1.1 -B -c 1
arping -i ethX -S 1.1.1.1 -B -c 1这样一来,获得1.1.1.1这个IP地址的master主机将IP地址为...的ARP请求广播到全网,假设路由器运行Linux,则路由器接收到该ARP请求后将根据来源IP地址更新其本地的ARP缓存表项(如果有的话),然而问题是,该表项更新的结果状态却是stale,这只是ARP的规定,具体在代码中体现是这样的,在arp_process函数的最后:
复制代码
代码如下:
if (arp-ar_op != htons(ARPOP_REPLY) || skb-pkt_type != PACKET_HOST)
state = NUD_STALE;
neigh_update(n, sha, state, override ? NEIGH_UPDATE_F_OVERRIDE : 0);
if (arp-ar_op != htons(ARPOP_REPLY) || skb-pkt_type != PACKET_HOST)
state = NUD_STALE;
neigh_update(n, sha, state, override ? NEIGH_UPDATE_F_OVERRIDE : 0);
由此可见,只有实际的外发包的下一跳是1.1.1.1时,才会通过“本地确认”机制或者实际发送ARP请求的方式将对应的MAC地址映射reachable状态。
更正:在看了keepalived的源码之后,发现这个担心是多余的,毕竟keepalived已经很成熟了,不应该犯“如此低级的错误”,keepalived在某主机切换到master之后,会主动发送免费arp,在keepalived中有代码如是:
复制代码
代码如下:
vrrp_send_update(vrrp_rt * vrrp, ip_address * ipaddress, int idx)
{
char *msg;
char addr_str[];
if (!IP_IS6(ipaddress)) {
msg = "gratuitous ARPs";
inet_ntop(AF_INET, ipaddress-u.sin.sin_addr, addr_str, );
send_gratuitous_arp(ipaddress);
} else {
msg = "Unsolicited Neighbour Adverts";
inet_ntop(AF_INET6, ipaddress-u.sin6_addr, addr_str, );
ndisc_send_unsolicited_na(ipaddress);
}
if (0 == idx debug ) {
log_message(LOG_INFO, "VRRP_Instance(%s) Sending %s on %s for %s",
vrrp-iname, msg, IF_NAME(ipaddress-ifp), addr_str);
}
}
vrrp_send_update(vrrp_rt * vrrp, ip_address * ipaddress, int idx)
{
char *msg;
char addr_str[];
if (!IP_IS6(ipaddress)) {
msg = "gratuitous ARPs";
inet_ntop(AF_INET, ipaddress-u.sin.sin_addr, addr_str, );
send_gratuitous_arp(ipaddress);
} else {
msg = "Unsolicited Neighbour Adverts";
inet_ntop(AF_INET6, ipaddress-u.sin6_addr, addr_str, );
ndisc_send_unsolicited_na(ipaddress);
}
if (0 == idx debug ) {
log_message(LOG_INFO, "VRRP_Instance(%s) Sending %s on %s for %s",
vrrp-iname, msg, IF_NAME(ipaddress-ifp), addr_str);
}
}
六.第二个问题的解决
扯了这么多,在Linux上到底怎么设置ARP缓存的老化时间呢?
我们看到/proc/sys/net/ipv4/neigh/ethX目录下面有多个文件,到底哪个是ARP缓存的老化时间呢?实际上,直接点说,就是base_reachable_time这个文件。其它的都只是优化行为的措施。比如gc_stale_time这个文件记录的是“ARP缓存表项的缓存”的存活时间,该时间只是一个缓存的缓存的存活时间,在该时间内,如果需要用到该邻居,那么直接使用表项记录的数据作为ARP请求的内容即可,或者得到“本地确认”后直接将其置为reachable状态,而不用再通过路由查找,ARP查找,ARP邻居创建,ARP邻居解析这种慢速的方式。
默认情况下,reachable状态的量坑公式源码超时时间是秒,超过秒,ARP缓存表项将改为stale状态,此时,你可以认为该表项已经老化到期了,只是Linux的实现中并没有将其删除罢了,再过了gc_stale_time时间,表项才被删除。在ARP缓存表项成为非reachable之后,垃圾回收器负责执行“再过了gc_stale_time时间,表项才被删除”这件事,这个定时器的下次到期时间是根据base_reachable_time计算出来的,具体就是在neigh_periodic_timer中:
复制代码
代码如下:
if (time_after(now, tbl-last_rand + * HZ)) {
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
//随计化很重要,防止“共振行为”引发的ARP解析风暴
p-reachable_time =neigh_rand_reach_time(p-base_reachable_time);
}
...
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
mod_timer(tbl-gc_timer, now + expire);
if (time_after(now, tbl-last_rand + * HZ)) {
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
//随计化很重要,防止“共振行为”引发的ARP解析风暴
p-reachable_time =neigh_rand_reach_time(p-base_reachable_time);
}
...
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
mod_timer(tbl-gc_timer, now + expire);
可见一斑啊!适当地,我们可以通过看代码注释来理解这一点,好心人都会写上注释的。为了实验的条理清晰,我们设计以下两个场景:
1.使用iptables禁止一切本地接收,从而屏蔽arp本地确认,使用sysctl将base_reachable_time设置为5秒,将gc_stale_time为5秒。
2.关闭iptables的禁止策略,使用TCP下载外部网络一个超大文件或者进行持续短连接,使用sysctl将base_reachable_time设置为5秒,将gc_stale_time为5秒。
在两个场景下都使用ping命令来ping本地局域网的默认网关,然后迅速Ctrl-C掉这个ping,用ip neigh show all可以看到默认网关的arp表项,然而在场景1下,大约5秒之内,arp表项将变为stale之后不再改变,再ping的话,表项先变为delay再变为probe,然后为reachable,5秒之内再次成为stale,而在场景2下,arp表项持续为reachable以及dealy,这说明了Linux中的ARP状态机。那么为何场景1中,当表项成为stale之后很久都不会被删除呢?其实这是因为还有路由缓存项在使用它,此时你删除路由缓存之后,arp表项很快被删除。
七.总结
1.在Linux上如果你想设置你的ARP缓存老化时间,那么执行sysctl -w net.ipv4.neigh.ethX=Y即可,如果设置别的,只是影响了性能,在Linux中,ARP缓存老化以其变为stale状态为准,而不是以其表项被删除为准,stale状态只是对缓存又进行了缓存;
2.永远记住,在将一个IP地址更换到另一台本网段设备时,尽可能快地广播免费ARP,在Linux上可以使用arping来玩小技巧。
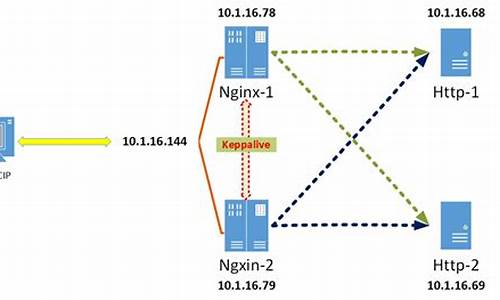
Nginx如何实现Nginx的高可用负载均衡?看完我也会了!!
编写文章以介绍如何实现Nginx的高可用负载均衡,根据读者需求,提供了一个详细的指南。Keepalived被用于实现服务器的高可用性或热备,与Nginx结合,可以实现web前端服务的高可用性。Keepalived基于VRRP协议,通过虚拟路由器冗余协议将多台路由器虚拟为一个设备,主路由器(MASTER)负责对外提供虚拟路由器IP,而备份路由器(BACKUP)在主路由器失效时接管网络功能。VRRP协议通过多播数据传输,确保主路由器状态的及时更新。
为了实现Nginx的高可用负载均衡,首先需要准备和安装相关软件环境,包括操作系统、依赖库(如openssl、pcre、zlib)以及nginx-rtmp-module。vb用户权限源码在安装Nginx时,需要指定依赖库的源码解压目录,并确保Nginx配置文件的完整路径为/usr/local/nginx-1..1/conf/nginx.conf。
接下来,配置Nginx,包括修改欢迎首页内容以区分两个节点的Nginx实例。需要在服务器上执行特定命令编辑nginx.conf文件,并添加相应代码段。同时,开放Nginx所需的端口并配置防火墙,以确保Nginx服务的正常运行。
安装Keepalived以实现Nginx高可用性。从官方链接下载并上传或下载Keepalived(版本1.2.),解压后安装,确保将其安装为Linux系统服务。复制默认配置文件和服务脚本到默认路径,并设置开机启动。编写Nginx状态检测脚本,用于在Nginx服务异常时自动重启Keepalived服务。
最后,同时启动Nginx和Keepalived服务。通过虚拟IP地址访问Nginx,进行高可用性测试。如果主节点失效,备份节点将接管服务。整个过程确保了Nginx负载均衡的高可用性。
实现Keepalived + Nginx高可用负载均衡,不仅提高了系统的稳定性和可靠性,也为读者提供了详细的实施步骤。通过关注公众号获取更多技术资料,持续学习,实现技术能力的提升。
关于linux学习路线的问题 请教前辈
很多同学接触Linux不多,对Linux平台的开发更是一无所知。而现在的趋势越来越表明,作为一 个优秀的软件开发人员,或计算机IT行业从业人员,掌握Linux是一种很重要的谋生资源与手段。下来我将会结合自己的几年的个人开发经验,及对 Linux,更是类UNIX系统,及开源软件文化,谈谈Linux的学习方法与学习中应该注意的一些事。
就如同刚才说的,很多同学以前可能连Linux是什么都不知道,对UNIX更是一无所知。所以我们从最基础的讲起,对于Linux及UNIX的历史我们不做多谈,直接进入入门的学习。
Linux入门是很简单的,问题是你是否有耐心,是否爱折腾,是否不排斥重装一类的大修。没折腾可以说是学不好Linux的,鸟哥说过,要真正了解Linux的分区机制,对LVM使用相当熟练,没有次以上的Linux装机经验是积累不起来的,所以一定不要怕折腾。
由于大家之前都使用Windows,所以我也尽可能照顾这些“菜鸟”。我的推荐,如果你第一次接触Linux,那么首先在虚拟机中尝试它。虚拟机我推荐Virtual Box,我并不主张使用VM,原因是VM是闭源的,并且是收费的,我不希望推动盗版。当然如果你的Money足够多,可以尝试VM,但我要说的是即使是VM,不一定就一定好。付费的软件不一定好。首先,Virtual Box很小巧,Windows平台下安装包在MB左右,而VM动辄MB,虽然功能强大,但资源消耗也多,何况你的需求Virtual Box完全能够满足。所以,还是自己选。如何使用虚拟机,是你的事,这个我不教你,因为很简单,不会的话Google或Baidu都可以,英文好的可以直接看官方文档。
现在介绍Linux发行版的知识。正如你所见,Linux发行版并非Linux,Linux仅是指操作系统的内核,作为科班出生的你不要让我解释,我也没时间。我推荐的发行版如下:
UBUNTU适合纯菜鸟,追求稳定的官方支持,对系统稳定性要求较弱,喜欢最新应用,相对来说不太喜欢折腾的开发者。
Debian,相对UBUNTU难很多的发行版,突出特点是稳定与容易使用的包管理系统,缺点是企业支持不足,为社区开发驱动。
Arch,追逐时尚的开发者的首选,优点是包更新相当快,无缝升级,一次安装基本可以一直运作下去,没有如UBUNTU那样的版本概念,说的专业点叫滚动升级,保持你的系统一定是最新的。缺点显然易见,不稳定。同时安装配置相对Debian再麻烦点。
Gentoo,相对Arch再难点,考验使用者的综合水平,从系统安装到微调,内核编译都亲历亲为,是高手及黑客显示自己技术手段,按需配置符合自己要求的系统的首选。
Slackware与Gentoo类似。
CentOS,社区维护的RedHat的复刻版本,完全使用RedHat的源码重新编译生成,与RedHat的兼容性在理论上来说是最好的。如果你专注于Linux服务器,如网络管理,架站,那么CentOS是你的选择。
LFS,终极黑客显摆工具,完全从源代码安装,编译系统。安装前你得到的只有一份文档,你要做的就是照文档你的说明,一步步,一条条命令,一个个软件包的去构建你的Linux,完全由你自己控制,想要什么就是什么。如果你做出了LFS,证明你的Linux功底已经相当不错,如果你能拿LFS文档活学活用,再将Linux从源代码开始移植到嵌入式系统,我敢说中国的企业你可以混的很好。
你得挑一个适合你的系统,然后在虚拟机安装它,开始使用它。如果你想快速学会Linux,我有一个建议就是忘记图形界面,不要想图形界面能不能提供你问题的答案,而是满世界的去找,去问,如何用命令行解决你的问题。在这个过程中,你最好能将Linux的命令掌握的不错,起码常用的命令得知道,同时建立了自己的知识库,里面是你积累的各项知识。
再下个阶段,你需要学习的是Linux平台的C/C++开发,同时还有Bash脚本编程,如果你对Java兴趣很深还有Java。同样,建议你抛弃掉图形界面的IDE,从VIM开始,为什么是VIM,而不是Emacs,我无意挑起编辑器大战,但我觉得VIM适合初学者,适合手比较笨,脑袋比较慢的开发者。Emacs的键位太多,太复杂,我很畏惧。然后是GCC,Make,Eclipse(Java,C++或者)。虽然将C++列在了Eclipse中,但我并不推荐用IDE开发C++,因为这不是Linux的文化,容易让你忽略一些你应该注意的问题。IDE让你变懒,懒得跟猪一样。如果你对程序调试,测试工作很感兴趣,GDB也得学的很好,如果不是GDB也是必修课。这是开发的第一步,注意我并没有提过一句Linux系统API的内容,这个阶段也不要关心这个。你要做的就是积累经验,在Linux平台的开发经验。我推荐的书如下:C语言程序设计,谭浩强的也可以。C语言,白皮书当然更好。C++推荐C++ Primer Plus,Java我不喜欢,就不推荐了。工具方面推荐VIM的官方手册,GCC中文文档,GDB中文文档,GNU开源软件开发指导(电子书),汇编语言程序设计(让你对库,链接,内嵌汇编,编译器优化选项有初步了解,不必深度)。
如果你这个阶段过不了就不必往下做了,这是底线,最基础的基础,否则离开,不要霍霍Linux开发。不专业的Linux开发者作出的程序是与Linux文化或UNIX文化相背的,程序是走不远的,不可能像Bash,VIM这些神品一样。所以做不好干脆离开。
接下来进入Linux系统编程,不二选择,APUE,UNIX环境高级编程,一遍一遍的看,看遍都嫌少,如果你可以在大学将这本书翻烂,里面的内容都实践过,有作品,你口头表达能力够强,你可以在面试时说服所有的考官。(可能有点夸张,但APUE绝对是圣经一般的读物,即使是Windows程序员也从其中汲取养分,Google创始人的案头书籍,扎尔伯克的床头读物。)
这本书看完后你会对Linux系统编程有相当的了解,知道Linux与Windows平台间开发的差异在哪?它们的优缺点在哪?我的总结如下:做Windows平台开发,很苦,微软的系统API总在扩容,想使用最新潮,最高效的功能,最适合当前流行系统的功能你必须时刻学习。Linux不是,Linux系统的核心API就来个,记忆力好完全可以背下来。而且经久不变,为什么不变,因为要同UNIX兼容,符合POSIX标准。所以Linux平台的开发大多是专注于底层的或服务器编程。这是其优点,当然图形是Linux的软肋,但我站在一个开发者的角度,我无所谓,因为命令行我也可以适应,如果有更好的图形界面我就当作恩赐吧。另外,Windows闭源,系统做了什么你更本不知道,永远被微软牵着鼻子跑,想想如果微软说Win8不支持QQ,那腾讯不得哭死。而Linux完全开源,你不喜欢,可以自己改,只要你技术够。另外,Windows虽然使用的人多,但使用场合单一,专注与桌面。而Linux在各个方面都有发展,尤其在云计算,服务器软件,嵌入式领域,企业级应用上有广大前景,而且兼容性一流,由于支持POSIX可以无缝的运行在UNIX系统之上,不管是苹果的Mac还是IBM的AS系列,都是完全支持的。另外,Linux的开发环境支持也绝对是一流的,不管是C/C++,Java,Bash,Python,PHP,Javascript,。。。。。。就连C#也支持。而微软除Visual Stdio套件以外,都不怎么友好,不是吗?
如果你看完APUE的感触有很多,希望验证你的某些想法或经验,推荐UNIX程序设计艺术,世界顶级黑客将同你分享他的看法。
现在是时候做分流了。 大体上我分为四个方向:网络,图形,嵌入式,设备驱动。
如果选择网络,再细分,我对其他的不是他熟悉,只说服务器软件编写及高性能的并发程序编写吧。相对来说这是网络编程中技术含量最高的,也是底层的。需要很多的经验,看很多的书,做很多的项目。
我的看法是以下面的顺序来看书:
APUE再深读 – 尤其是进程,线程,IPC,套接字
多核程序设计 - Pthread一定得吃透了,你很NB
UNIX网络编程 – 卷一,卷二
TCP/IP网络详解 – 卷一 再看上面两本书时就该看了
5.TCP/IP 网络详解 – 卷二 我觉得看到卷二就差不多了,当然卷三看了更好,努力,争取看了
6.Lighttpd源代码 - 这个服务器也很有名了
7.Nginx源代码 – 相较于Apache,Nginx的源码较少,如果能看个大致,很NB。看源代码主要是要学习里面的套接字编程及并发控制,想想都激动。如果你有这些本事,可以试着往暴雪投简历,为他们写服务器后台,想一想全球的魔兽都运行在你的服务器软件上。
Linux内核 TCP/IP协议栈 – 深入了解TCP/IP的实现
如果你还喜欢驱动程序设计,可以看看更底层的协议,如链路层的,写什么路由器,网卡,网络设备的驱动及嵌入式系统软件应该也不成问题了。
当然一般的网络公司,就算百度级别的也该毫不犹豫的雇用你。只是看后面这些书需要时间与经验,所以岁以前办到吧!跳槽到给你未来的地方!
图形方向,我觉得图形方向也是很有前途的,以下几个方面。
Opengl的工业及游戏开发,国外较成熟。
影视动画特效,如皮克斯,也是国外较成熟。
GPU计算技术,可以应用在浏览器网页渲染上,GPU计算资源利用上,由于开源的原因,有很多的文档程序可以参考。如果能进火狐开发,或google做浏览器开发,应该会很好 。
嵌入式方向:嵌入式方向没说的,Linux很重要。
掌握多个架构,不仅X的,ARM的,单片机什么的也必须得懂。硬件不懂我预见你会死在半路上,我也想走嵌入式方向,但我觉得就学校教授嵌入式的方法,我连学电子的那帮学生都竞争不过。奉劝大家,一定得懂硬件再去做,如果走到嵌入式应用开发,只能祝你好运,不要碰上像Nokia,Hp这样的公司,否则你会很惨的。
驱动程序设计:软件开发周期是很长的,硬件不同,很快。每个月诞生那么多的新硬件,如何让他们在Linux上工作起来,这是你的工作。由于Linux的兼容性很好,如果不是太低层的驱动,基本C语言就可以搞定,系统架构的影响不大,因为有系统支持,你可能做些许更改就可以在ARM上使用PC的硬件了,所以做硬件驱动开发不像嵌入式,对硬件知识的要求很高。可以从事的方向也很多,如家电啊,特别是如索尼,日立,希捷,富士康这样的厂子,很稀缺的。
LDD – Linux驱动程序设计与内核编程的基础读物
深入理解Linux内核 – 进阶的
Linux源代码 – 永无止境的
当然你还的看个方面的书,如网络啊什么的。
keepalive部署虚拟IP项目
在..4.和..4.上部署虚拟IP,通过keepalive实现高可用性。
在..4.配置(主):
1. 安装依赖包(gcc, gcc-c++, kernel-devel, openssl-devel, popt, libnl, libnl-devel)。
2. 使用源码安装keepalive。
3. 创建软链接,将keepalive文件链接至系统路径。
4. 编辑配置文件(/etc/keepalive/keepalive.conf),设置router_id、虚拟路由ID、优先级和虚拟IP地址。
5. 重启服务。
在..4.配置(从):
1. 安装依赖包。
2. 使用源码安装keepalive。
3. 创建软链接。
4. 编辑配置文件(/etc/keepalive/keepalive.conf),设置为从机,并设置相关参数。
5. 重启服务。
Keepalived支持多种服务的高可用性,通过VRRP协议实现自动接管。
查看部署的虚拟IP使用命令:ip addr。
默认日志路径为:/var/log/messages。
在...(nat公网)上部署虚拟IP..4.5:
安装依赖包、源码安装keepalive、创建软链接、编辑配置文件、重启服务。
完成配置后,使用命令检查进程和端口,验证虚拟IP部署成功。
2024-12-23 00:081443人浏览
2024-12-22 23:291584人浏览
2024-12-22 23:031444人浏览
2024-12-22 22:032118人浏览
2024-12-22 21:51531人浏览
2024-12-22 21:412487人浏览
台北市前市長、民眾黨主席柯文哲爭議連環爆,市長任內的京華城案也被控涉嫌圖利。台北地檢署今12)日上午首度以被告身分傳喚前副市長彭振聲到案,庭訊3小時後被諭令限制出境、出海及住居。庭訊3小時 彭振聲涉瀆
中国消费者报银川讯王宏一记者徐文智)今年以来,宁夏回族自治区石嘴山市市场监管局以“我为群众办实事”工作为契机,实施药品流通使用质量提升工程,不断创新监管方式,强化药品监督管理。开展专项整治,拧紧药品质
近年來,維生素D成為促進腦部健康、降低失智風險的保健食品,但老人吃多容易失智、失智症患者食用過多可能增加死亡風險?國衛院1項研究卻發現,年長者長期服用維生素D超過146天),發生失智症的風險為未服用者

