1.百度 UidGenerator 源码解析
2.手麻系统源码AIMS:围术期电子病历和麻醉质量的共排公排智慧医疗管理系统
3.通达信编程学习三:“板块龙头”排序指标源码解析及小结
4.C语言版-数据结构-期末课程设计-大作业(学生成绩管理系统)附源码+实验文档
5.79C3125EAC1CE25EE2C99A9B01DFC00
6.cè¯è¨ç¨åºä»£ç 大å
¨(cè¯è¨ç¨åºç¼ç¨ä»£ç 大å
¨)
百度 UidGenerator 源码解析
雪花算法(Snowflake)是一种生成分布式全局唯一 ID 的算法,用于推文 ID 的源码源代生成,并在 Discord 和 Instagram 等平台采用其修改版本。系统一个 Snowflake ID 由 位组成,免费码其中前 位表示时间戳(毫秒数),共排公排接下来的源码源代片源网源码 位用于标识计算机, 位作为序列号,系统以确保同一毫秒内生成的免费码多个 ID。此算法基于时间生成,共排公排按时间排序,源码源代允许通过 ID 推断生成时间。系统Snowflake ID 的免费码生成包括时间戳、工作机器 ID 和序列号,共排公排确保了分布式环境中的源码源代全局唯一性。
在 Java 中实现的系统 UidGenerator 基于 Snowflake 算法,支持自定义工作机器 ID 位数和初始化策略。它通过使用未来时间解决序列号的并发限制,采用 RingBuffer 缓存已生成的 UID,进行并行生产和消费,并对 CacheLine 进行补全以避免硬件级「伪共享」问题。在 Docker 等虚拟化环境下,UidGenerator 支持实例自动重启和漂移场景,单机 QPS 可达 万。
UidGenerator 采用不同的cci叠加kDJ公式源码实现策略,如 DefaultUidGenerator 和 CachedUidGenerator。DefaultUidGenerator 提供了基础的 Snowflake ID 生成模式,无需预存 UID,即时计算。而 CachedUidGenerator 则预先缓存 UID,通过 RingBuffer 提前填充并设置阈值自动填充机制,以提高生成效率。
RingBuffer 是 UidGenerator 的核心组件,用于缓存和管理 UID 的生成。在 DefaultUidGenerator 中,时间基点通过 epochStr 参数定义,用于计算时间戳。Worker ID 分配器在初始化阶段自动为每个工作机器分配唯一的 ID。核心生成方法处理异常情况,如时钟回拨,通过二进制运算生成最终的 UID。
CachedUidGenerator 则利用 RingBuffer 进行 UID 的缓存,根据填充阈值自动填充,以减少实时生成和计算的开销。RingBuffer 的设计考虑了伪共享问题,通过 CacheLine 补齐策略优化读写性能,确保在并发环境中高效生成 UID。
总结而言,国际化源码解析Snowflake 算法和 UidGenerator 的设计旨在提供高性能、分布式且全局唯一的 ID 生成解决方案,适用于多种场景,包括高并发环境和分布式系统中。通过精心设计的组件和策略,确保了 ID 的生成效率和一致性,满足现代应用对 ID 管理的严格要求。
手麻系统源码AIMS:围术期电子病历和麻醉质量的智慧医疗管理系统
手术麻醉临床信息系统是专为麻醉医生、手术护士及手术室相关科室医生设计的,它涵盖了手术排程、麻醉前访视、麻醉前分析、用药、评级、麻醉诱导室、手术室、苏醒室、术后访视、麻醉科室管理及数据统计分析等围术期临床应用系统。该系统提供了围术期临床信息、管理和科研系统的整体解决方案,并实现了手术室时间、人员、开盲盒html源码设备资源和信息资源的高度共享,构建了围术期电子病历和麻醉质量的智慧医疗管理系统。
该系统的技术架构采用php js + laravel + mysql + vue2 element B/S网页版。
手术麻醉信息管理系统涵盖患者从预约申请手术到术前、术中、术后的全程流程控制。
一、手术申请
系统可从HIS中直接读取手术预约申请单,确保手术麻醉数据与HIS数据的一致性和准确性。手工填写手术申请单时,仅需输入患者住院号,患者基本信息将自动从HIS中获取。
二、手术安排
系统自动获取已预约申请的手术列表,并可对每条手术进行手术排版。排班信息包括手术时间、手术间、手术台次、麻醉医生、麻醉助手、巡回护士、洗手护士等,同时支持取消手术、在线盲盒源码系统编辑手术信息。系统还支持紧急手术,无需经过手术预约申请、手术安排等流程即可进入手术麻醉监测状态。
三、术前访视与麻醉计划
系统可全面了解病人入院基本信息、既往病史、手术史、药物过敏史等相关情况,并对患者进行全面病情评估,制定相应的手术麻醉计划。术前访视记录、麻醉计划、麻醉同意书等电子病历的重要组成部分,支持数据统一定义和模版定义,并支持签名功能,同时也可输出打印存档。
四、术中模块
系统对正在手术的患者进行各项生命体征的监测,自动采集并记录术中监测设备监测的数据,并实时、客观地显示。用户可自定义设置显示在麻醉记录单上的数据,并选择设置显示频率。数据展现形式包括数值型、波形图和趋势图等,并自动生成麻醉记录单。
五、手术护理与小结
系统包含术中护理模块和手术护理交接班术后模块,支持麻醉医生记录已完成手术的患者相关生命体征等,从而完成“术后麻醉小结”。
通达信编程学习三:“板块龙头”排序指标源码解析及小结
通达信编程学习中的一个重要环节是解析和理解指标源码,通过实战提升编程技能。今天要分享的是一个"板块龙头"排序指标的源码分析,尽管代码看似点赞量高,但其逻辑混乱,不适合直接实操。本文重点在于学习过程,而非优化指标。
源码分析部分,代码共计行,涉及股票名称筛选、收盘价相对位置、行业涨幅排名、开盘涨幅判断等多个环节。例如,ABC1和ABC2用于筛选st股和*st股,ABC5和ABC6分别计算股票的相对位置和行业涨幅排名。在指标计算中,BAC1~BAC是一系列复杂的条件判断,用于确定个股的入选资格,如交易天数、市值、代码特征等。
个人小结部分,这个指标存在逻辑不清晰、拼凑痕迹明显的问题,但它也提供了一种思路:通过行业中涨势最好的个股寻找短期热点。对于有特定交易策略的投资者,如短线交易者,可能会有所启发。但要明确,本文仅用于学习交流,不构成投资建议。
投资决策应基于个人风险承受能力和专业评估,本文作者和发布者对此不承担任何责任。最后,再次强调,本文观点仅为学习资源,读者需谨慎对待,并在必要时咨询专业人士。
C语言版-数据结构-期末课程设计-大作业(学生成绩管理系统)附源码+实验文档
在期末课程设计中,我完成了大作业——一个学生成绩管理系统,该系统涉及详细的设计和实现过程。首先,系统核心功能围绕学生信息管理,包括姓名、班级和学号,以及成绩查询、录入、修改和删除等操作。结构上,我使用了顺序表数据结构,构建了包含插入、查找、删除和排序等模块的系统。
设计内容包括定义一个名为studentInformation的结构体,用于存储学生信息,包括各科成绩、总分等。系统共设置了8个主要菜单:新建学生信息、插入学生、查询、删除、查询所有学生、按总分和学号排序、修改成绩以及退出。例如,新建学生时,用户需要输入指定数量的学生信息,每名学生的信息包含姓名、班级、学号和各科成绩。
主函数通过预设的账号密码(admin和root)进行登录,然后调用add_student、stu_check、del_stu等函数实现各个功能。add_student函数允许输入一定数量的学生数据,insert_stu函数确保学号唯一性,stu_check则根据学号查找学生信息。
排序功能采用冒泡排序,stu_num和sum_grade函数分别用于按学号和总分对学生信息进行排序。update_grade函数允许用户修改已有的学生科目成绩,如果输入的科目不存在则不作处理。
在使用说明部分,详细列出了每个操作的输入格式,如登录时需要输入admin和root,新建学生时需指定学生数量等。同时,也展示了部分操作界面示例,如登录成功、插入学生和修改成绩后的操作结果。
测试阶段,通过更改学生成绩并查看总分是否更新,验证了程序的正确性。然而,也发现了一些改进空间,比如当输入的学号前几位为0时,系统可能无法识别,以及在学生数量超过预设容量时,需要提示用户或调整存储策略。
源代码和实验文档作为附件,对于需要源代码或咨询的同学们,可以直接私信我或者扫描QQ二维码,我的QQ号是。系统设计图和详细代码实现都在附件中供参考。
CEAC1CEEE2CA9BDFC
å¯è½æ¯ç±»ä¼¼äºmd5çå å¯ç®æ³
---------------
md5çå ¨ç§°æ¯message-digest algorithm 5ï¼ä¿¡æ¯-æè¦ç®æ³ï¼ï¼å¨å¹´ä»£åç±mit laboratory for computer scienceårsa data security incçronald l. rivestå¼ååºæ¥ï¼ç»md2ãmd3åmd4åå±èæ¥ãå®çä½ç¨æ¯è®©å¤§å®¹éä¿¡æ¯å¨ç¨æ°åç¾å软件ç¾ç½²ç§äººå¯åå被"å缩"æä¸ç§ä¿å¯çæ ¼å¼ï¼å°±æ¯æä¸ä¸ªä»»æé¿åº¦çåè串åæ¢æä¸å®é¿ç大æ´æ°ï¼ãä¸ç®¡æ¯md2ãmd4è¿æ¯md5ï¼å®ä»¬é½éè¦è·å¾ä¸ä¸ªéæºé¿åº¦çä¿¡æ¯å¹¶äº§çä¸ä¸ªä½çä¿¡æ¯æè¦ãè½ç¶è¿äºç®æ³çç»ææå¤æå°æäºç¸ä¼¼ï¼ä½md2ç设计ä¸md4åmd5å®å ¨ä¸åï¼é£æ¯å 为md2æ¯ä¸º8ä½æºå¨åè¿è®¾è®¡ä¼åçï¼èmd4åmd5å´æ¯é¢åä½ççµèãè¿ä¸ä¸ªç®æ³çæè¿°åcè¯è¨æºä»£ç å¨internet rfcs ä¸æ详ç»çæè¿°ï¼h++p://www.ietf.org/rfc/rfc.txtï¼ï¼è¿æ¯ä¸ä»½ææå¨çææ¡£ï¼ç±ronald l. rivestå¨å¹´8æåieftæ交ã
rivestå¨å¹´å¼ååºmd2ç®æ³ãå¨è¿ä¸ªç®æ³ä¸ï¼é¦å 对信æ¯è¿è¡æ°æ®è¡¥ä½ï¼ä½¿ä¿¡æ¯çåèé¿åº¦æ¯çåæ°ãç¶åï¼ä»¥ä¸ä¸ªä½çæ£éªå追å å°ä¿¡æ¯æ«å°¾ã并ä¸æ ¹æ®è¿ä¸ªæ°äº§ççä¿¡æ¯è®¡ç®åºæ£åå¼ãåæ¥ï¼rogieråchauvaudåç°å¦æ忽ç¥äºæ£éªåå°äº§çmd2å²çªãmd2ç®æ³çå å¯åç»ææ¯å¯ä¸ç--æ¢æ²¡æéå¤ã
为äºå 强ç®æ³çå®å ¨æ§ï¼rivestå¨å¹´åå¼ååºmd4ç®æ³ãmd4ç®æ³åæ ·éè¦å¡«è¡¥ä¿¡æ¯ä»¥ç¡®ä¿ä¿¡æ¯çåèé¿åº¦å ä¸åè½è¢«æ´é¤ï¼ä¿¡æ¯åèé¿åº¦mod = ï¼ãç¶åï¼ä¸ä¸ªä»¥ä½äºè¿å¶è¡¨ç¤ºçä¿¡æ¯çæåé¿åº¦è¢«æ·»å è¿æ¥ãä¿¡æ¯è¢«å¤çæä½damg?rd/merkleè¿ä»£ç»æçåºåï¼èä¸æ¯ä¸ªåºåè¦éè¿ä¸ä¸ªä¸åæ¥éª¤çå¤çãden boeråbosselaers以åå ¶ä»äººå¾å¿«çåç°äºæ»å»md4çæ¬ä¸ç¬¬ä¸æ¥å第ä¸æ¥çæ¼æ´ãdobbertinå大家æ¼ç¤ºäºå¦ä½å©ç¨ä¸é¨æ®éç个人çµèå¨å åéå æ¾å°md4å®æ´çæ¬ä¸çå²çªï¼è¿ä¸ªå²çªå®é ä¸æ¯ä¸ç§æ¼æ´ï¼å®å°å¯¼è´å¯¹ä¸åçå 容è¿è¡å å¯å´å¯è½å¾å°ç¸åçå å¯åç»æï¼ã毫æ çé®ï¼md4å°±æ¤è¢«æ·æ±°æäºã
尽管md4ç®æ³å¨å®å ¨ä¸æ个è¿ä¹å¤§çæ¼æ´ï¼ä½å®å¯¹å¨å ¶åæ被å¼ååºæ¥ç好å ç§ä¿¡æ¯å®å ¨å å¯ç®æ³çåºç°å´æçä¸å¯å¿½è§çå¼å¯¼ä½ç¨ãé¤äºmd5以å¤ï¼å ¶ä¸æ¯è¾æåçè¿æsha-1ãripe-md以åhavalçã
ä¸å¹´ä»¥åï¼å³å¹´ï¼rivestå¼ååºææ¯ä¸æ´ä¸ºè¶è¿æççmd5ç®æ³ãå®å¨md4çåºç¡ä¸å¢å äº"å®å ¨-带å"ï¼safety-beltsï¼çæ¦å¿µãè½ç¶md5æ¯md4ç¨å¾®æ ¢ä¸äºï¼ä½å´æ´ä¸ºå®å ¨ãè¿ä¸ªç®æ³å¾ææ¾çç±å个åmd4设计æå°è®¸ä¸åçæ¥éª¤ç»æãå¨md5ç®æ³ä¸ï¼ä¿¡æ¯-æè¦ç大å°åå¡«å çå¿ è¦æ¡ä»¶ä¸md4å®å ¨ç¸åãden boeråbosselaersæ¾åç°md5ç®æ³ä¸çåå²çªï¼pseudo-collisionsï¼ï¼ä½é¤æ¤ä¹å¤å°±æ²¡æå ¶ä»è¢«åç°çå å¯åç»æäºã
van oorschotåwieneræ¾ç»èèè¿ä¸ä¸ªå¨æ£åä¸æ´åæ寻å²çªçå½æ°ï¼brute-force hash functionï¼ï¼èä¸ä»ä»¬çæµä¸ä¸ªè¢«è®¾è®¡ä¸é¨ç¨æ¥æç´¢md5å²çªçæºå¨ï¼è¿å°æºå¨å¨å¹´çå¶é ææ¬å¤§çº¦æ¯ä¸ç¾ä¸ç¾å ï¼å¯ä»¥å¹³åæ¯å¤©å°±æ¾å°ä¸ä¸ªå²çªãä½åä»å¹´å°å¹´è¿å¹´é´ï¼ç«æ²¡æåºç°æ¿ä»£md5ç®æ³çmd6æ被å«åå ¶ä»ä»ä¹ååçæ°ç®æ³è¿ä¸ç¹ï¼æ们就å¯ä»¥çåºè¿ä¸ªççµå¹¶æ²¡æ太å¤çå½±åmd5çå®å ¨æ§ãä¸é¢ææè¿äºé½ä¸è¶³ä»¥æ为md5çå¨å®é åºç¨ä¸çé®é¢ã并ä¸ï¼ç±äºmd5ç®æ³ç使ç¨ä¸éè¦æ¯ä»ä»»ä½çæè´¹ç¨çï¼æ以å¨ä¸è¬çæ åµä¸ï¼éç»å¯åºç¨é¢åãä½å³ä¾¿æ¯åºç¨å¨ç»å¯é¢åå ï¼md5ä¹ä¸å¤±ä¸ºä¸ç§é常ä¼ç§çä¸é´ææ¯ï¼ï¼md5æä¹é½åºè¯¥ç®å¾ä¸æ¯é常å®å ¨çäºã
ç®æ³çåºç¨
md5çå ¸ååºç¨æ¯å¯¹ä¸æ®µä¿¡æ¯ï¼messageï¼äº§çä¿¡æ¯æè¦ï¼message-digestï¼ï¼ä»¥é²æ¢è¢«ç¯¡æ¹ãæ¯å¦ï¼å¨unixä¸æå¾å¤è½¯ä»¶å¨ä¸è½½çæ¶åé½æä¸ä¸ªæ件åç¸åï¼æ件æ©å±å为.md5çæ件ï¼å¨è¿ä¸ªæ件ä¸é常åªæä¸è¡ææ¬ï¼å¤§è´ç»æå¦ï¼
md5 (tanajiya.tar.gz) = 0cab9c0fade
è¿å°±æ¯tanajiya.tar.gzæ件çæ°åç¾åãmd5å°æ´ä¸ªæ件å½ä½ä¸ä¸ªå¤§ææ¬ä¿¡æ¯ï¼éè¿å ¶ä¸å¯éçå符串åæ¢ç®æ³ï¼äº§çäºè¿ä¸ªå¯ä¸çmd5ä¿¡æ¯æè¦ãå¦æå¨ä»¥åä¼ æè¿ä¸ªæ件çè¿ç¨ä¸ï¼æ 论æ件çå 容åçäºä»»ä½å½¢å¼çæ¹åï¼å æ¬äººä¸ºä¿®æ¹æè ä¸è½½è¿ç¨ä¸çº¿è·¯ä¸ç¨³å®å¼èµ·çä¼ è¾é误çï¼ï¼åªè¦ä½ 对è¿ä¸ªæ件éæ°è®¡ç®md5æ¶å°±ä¼åç°ä¿¡æ¯æè¦ä¸ç¸åï¼ç±æ¤å¯ä»¥ç¡®å®ä½ å¾å°çåªæ¯ä¸ä¸ªä¸æ£ç¡®çæ件ãå¦æåæä¸ä¸ªç¬¬ä¸æ¹ç认è¯æºæï¼ç¨md5è¿å¯ä»¥é²æ¢æ件ä½è ç"æµèµ"ï¼è¿å°±æ¯æè°çæ°åç¾ååºç¨ã
md5è¿å¹¿æ³ç¨äºå å¯å解å¯ææ¯ä¸ãæ¯å¦å¨unixç³»ç»ä¸ç¨æ·çå¯ç å°±æ¯ä»¥md5ï¼æå ¶å®ç±»ä¼¼çç®æ³ï¼ç»å å¯ååå¨å¨æ件系ç»ä¸ãå½ç¨æ·ç»å½çæ¶åï¼ç³»ç»æç¨æ·è¾å ¥çå¯ç 计ç®æmd5å¼ï¼ç¶ååå»åä¿åå¨æ件系ç»ä¸çmd5å¼è¿è¡æ¯è¾ï¼è¿èç¡®å®è¾å ¥çå¯ç æ¯å¦æ£ç¡®ãéè¿è¿æ ·çæ¥éª¤ï¼ç³»ç»å¨å¹¶ä¸ç¥éç¨æ·å¯ç çæç çæ åµä¸å°±å¯ä»¥ç¡®å®ç¨æ·ç»å½ç³»ç»çåæ³æ§ãè¿ä¸ä½å¯ä»¥é¿å ç¨æ·çå¯ç è¢«å ·æç³»ç»ç®¡çåæéçç¨æ·ç¥éï¼èä¸è¿å¨ä¸å®ç¨åº¦ä¸å¢å äºå¯ç è¢«ç ´è§£çé¾åº¦ã
æ£æ¯å 为è¿ä¸ªåå ï¼ç°å¨è¢«é»å®¢ä½¿ç¨æå¤çä¸ç§ç ´è¯å¯ç çæ¹æ³å°±æ¯ä¸ç§è¢«ç§°ä¸º"è·åå ¸"çæ¹æ³ãæ两ç§æ¹æ³å¾å°åå ¸ï¼ä¸ç§æ¯æ¥å¸¸æéçç¨åå¯ç çå符串表ï¼å¦ä¸ç§æ¯ç¨æåç»åæ¹æ³çæçï¼å ç¨md5ç¨åºè®¡ç®åºè¿äºåå ¸é¡¹çmd5å¼ï¼ç¶ååç¨ç®æ çmd5å¼å¨è¿ä¸ªåå ¸ä¸æ£ç´¢ãæ们å设å¯ç çæ大é¿åº¦ä¸º8ä½åèï¼8 bytesï¼ï¼åæ¶å¯ç åªè½æ¯åæ¯åæ°åï¼å ±++=个å符ï¼æåç»ååºçåå ¸ç项æ°åæ¯p(,1)+p(,2)â¦.+p(,8)ï¼é£ä¹å·²ç»æ¯ä¸ä¸ªå¾å¤©æçæ°åäºï¼åå¨è¿ä¸ªåå ¸å°±éè¦tb级çç£çéµåï¼èä¸è¿ç§æ¹æ³è¿æä¸ä¸ªåæï¼å°±æ¯è½è·å¾ç®æ è´¦æ·çå¯ç md5å¼çæ åµä¸æå¯ä»¥ãè¿ç§å å¯ææ¯è¢«å¹¿æ³çåºç¨äºunixç³»ç»ä¸ï¼è¿ä¹æ¯ä¸ºä»ä¹unixç³»ç»æ¯ä¸è¬æä½ç³»ç»æ´ä¸ºååºä¸ä¸ªéè¦åå ã
ç®æ³æè¿°
对md5ç®æ³ç®è¦çåè¿°å¯ä»¥ä¸ºï¼md5以ä½åç»æ¥å¤çè¾å ¥çä¿¡æ¯ï¼ä¸æ¯ä¸åç»å被åå为个ä½ååç»ï¼ç»è¿äºä¸ç³»åçå¤çåï¼ç®æ³çè¾åºç±å个ä½åç»ç»æï¼å°è¿å个ä½åç»çº§èåå°çæä¸ä¸ªä½æ£åå¼ã
å¨md5ç®æ³ä¸ï¼é¦å éè¦å¯¹ä¿¡æ¯è¿è¡å¡«å ï¼ä½¿å ¶åèé¿åº¦å¯¹æ±ä½çç»æçäºãå æ¤ï¼ä¿¡æ¯çåèé¿åº¦ï¼bits lengthï¼å°è¢«æ©å±è³n*+ï¼å³n*+个åèï¼bytesï¼ï¼n为ä¸ä¸ªæ£æ´æ°ãå¡«å çæ¹æ³å¦ä¸ï¼å¨ä¿¡æ¯çåé¢å¡«å ä¸ä¸ª1åæ æ°ä¸ª0ï¼ç´å°æ»¡è¶³ä¸é¢çæ¡ä»¶æ¶æåæ¢ç¨0对信æ¯çå¡«å ãç¶åï¼å¨å¨è¿ä¸ªç»æåé¢éå ä¸ä¸ªä»¥ä½äºè¿å¶è¡¨ç¤ºçå¡«å åä¿¡æ¯é¿åº¦ãç»è¿è¿ä¸¤æ¥çå¤çï¼ç°å¨çä¿¡æ¯åèé¿åº¦=n*++=(n+1)*ï¼å³é¿åº¦æ°å¥½æ¯çæ´æ°åãè¿æ ·åçåå æ¯ä¸ºæ»¡è¶³åé¢å¤çä¸å¯¹ä¿¡æ¯é¿åº¦çè¦æ±ã
md5ä¸æå个ä½è¢«ç§°ä½é¾æ¥åéï¼chaining variableï¼çæ´æ°åæ°ï¼ä»ä»¬åå«ä¸ºï¼a=0xï¼b=0xabcdefï¼c=0xfedcbaï¼d=0xã
å½è®¾ç½®å¥½è¿å个é¾æ¥åéåï¼å°±å¼å§è¿å ¥ç®æ³çå轮循ç¯è¿ç®ã循ç¯ç次æ°æ¯ä¿¡æ¯ä¸ä½ä¿¡æ¯åç»çæ°ç®ã
å°ä¸é¢å个é¾æ¥åéå¤å¶å°å¦å¤å个åéä¸ï¼aå°aï¼bå°bï¼cå°cï¼då°dã
主循ç¯æåè½®ï¼md4åªæä¸è½®ï¼ï¼æ¯è½®å¾ªç¯é½å¾ç¸ä¼¼ã第ä¸è½®è¿è¡æ¬¡æä½ãæ¯æ¬¡æä½å¯¹aãbãcådä¸çå ¶ä¸ä¸ä¸ªä½ä¸æ¬¡é线æ§å½æ°è¿ç®ï¼ç¶åå°æå¾ç»æå ä¸ç¬¬å个åéï¼ææ¬çä¸ä¸ªååç»åä¸ä¸ªå¸¸æ°ãåå°æå¾ç»æåå³ç¯ç§»ä¸ä¸ªä¸å®çæ°ï¼å¹¶å ä¸aãbãcædä¸ä¹ä¸ãæåç¨è¯¥ç»æå代aãbãcædä¸ä¹ä¸ã
以ä¸ä¸æ¯æ¯æ¬¡æä½ä¸ç¨å°çå个é线æ§å½æ°ï¼æ¯è½®ä¸ä¸ªï¼ã
f(x,y,z) =(x&y)|((~x)&z)
g(x,y,z) =(x&z)|(y&(~z))
h(x,y,z) =x^y^z
i(x,y,z)=y^(x|(~z))
ï¼&æ¯ä¸ï¼|æ¯æï¼~æ¯éï¼^æ¯å¼æï¼
è¿å个å½æ°ç说æï¼å¦æxãyåzç对åºä½æ¯ç¬ç«åååçï¼é£ä¹ç»æçæ¯ä¸ä½ä¹åºæ¯ç¬ç«åååçã
fæ¯ä¸ä¸ªéä½è¿ç®çå½æ°ãå³ï¼å¦æxï¼é£ä¹yï¼å¦åzãå½æ°hæ¯éä½å¥å¶æä½ç¬¦ã
å设mj表示æ¶æ¯ç第j个ååç»ï¼ä»0å°ï¼ï¼<<
ff(a,b,c,d,mj,s,ti)表示a=b+((a+(f(b,c,d)+mj+ti)<< gg(a,b,c,d,mj,s,ti)表示a=b+((a+(g(b,c,d)+mj+ti)<< hh(a,b,c,d,mj,s,ti)表示a=b+((a+(h(b,c,d)+mj+ti)<< ii(a,b,c,d,mj,s,ti)表示a=b+((a+(i(b,c,d)+mj+ti)<<
è¿åè½®ï¼æ¥ï¼æ¯ï¼
第ä¸è½®
ff(a,b,c,d,m0,7,0xdaa)
ff(d,a,b,c,m1,,0xe8c7b)
ff(c,d,a,b,m2,,0xdb)
ff(b,c,d,a,m3,,0xc1bdceee)
ff(a,b,c,d,m4,7,0xfc0faf)
ff(d,a,b,c,m5,,0xca)
ff(c,d,a,b,m6,,0xa)
ff(b,c,d,a,m7,,0xfd)
ff(a,b,c,d,m8,7,0xd8)
ff(d,a,b,c,m9,,0x8bf7af)
ff(c,d,a,b,m,,0xffff5bb1)
ff(b,c,d,a,m,,0xcd7be)
ff(a,b,c,d,m,7,0x6b)
ff(d,a,b,c,m,,0xfd)
ff(c,d,a,b,m,,0xae)
ff(b,c,d,a,m,,0xb)
第äºè½®
gg(a,b,c,d,m1,5,0xfe)
gg(d,a,b,c,m6,9,0xcb)
gg(c,d,a,b,m,,0xe5a)
gg(b,c,d,a,m0,,0xe9b6c7aa)
gg(a,b,c,d,m5,5,0xdfd)
gg(d,a,b,c,m,9,0x)
gg(c,d,a,b,m,,0xd8a1e)
gg(b,c,d,a,m4,,0xe7d3fbc8)
gg(a,b,c,d,m9,5,0xe1cde6)
gg(d,a,b,c,m,9,0xcd6)
gg(c,d,a,b,m3,,0xf4dd)
gg(b,c,d,a,m8,,0xaed)
gg(a,b,c,d,m,5,0xa9e3e)
gg(d,a,b,c,m2,9,0xfcefa3f8)
gg(c,d,a,b,m7,,0xfd9)
gg(b,c,d,a,m,,0x8d2a4c8a)
第ä¸è½®
hh(a,b,c,d,m5,4,0xfffa)
hh(d,a,b,c,m8,,0xf)
hh(c,d,a,b,m,,0x6d9d)
hh(b,c,d,a,m,,0xfdec)
hh(a,b,c,d,m1,4,0xa4beea)
hh(d,a,b,c,m4,,0x4bdecfa9)
hh(c,d,a,b,m7,,0xf6bb4b)
hh(b,c,d,a,m,,0xbebfbc)
hh(a,b,c,d,m,4,0xb7ec6)
hh(d,a,b,c,m0,,0xeaafa)
hh(c,d,a,b,m3,,0xd4ef)
hh(b,c,d,a,m6,,0xd)
hh(a,b,c,d,m9,4,0xd9d4d)
hh(d,a,b,c,m,,0xe6dbe5)
hh(c,d,a,b,m,,0x1facf8)
hh(b,c,d,a,m2,,0xc4ac)
第åè½®
ii(a,b,c,d,m0,6,0xf)
ii(d,a,b,c,m7,,0xaff)
ii(c,d,a,b,m,,0xaba7)
ii(b,c,d,a,m5,,0xfca)
ii(a,b,c,d,m,6,0xbc3)
ii(d,a,b,c,m3,,0x8f0ccc)
ii(c,d,a,b,m,,0xffeffd)
ii(b,c,d,a,m1,,0xdd1)
ii(a,b,c,d,m8,6,0x6fae4f)
ii(d,a,b,c,m,,0xfe2ce6e0)
ii(c,d,a,b,m6,,0xa)
ii(b,c,d,a,m,,0x4ea1)
ii(a,b,c,d,m4,6,0xfe)
ii(d,a,b,c,m,,0xbd3af)
ii(c,d,a,b,m2,,0x2ad7d2bb)
ii(b,c,d,a,m9,,0xebd)
常æ°tiå¯ä»¥å¦ä¸éæ©ï¼
å¨ç¬¬iæ¥ä¸ï¼tiæ¯*abs(sin(i))çæ´æ°é¨åï¼içåä½æ¯å¼§åº¦ã(çäº2ç次æ¹)
ææè¿äºå®æä¹åï¼å°aãbãcãdåå«å ä¸aãbãcãdãç¶åç¨ä¸ä¸åç»æ°æ®ç»§ç»è¿è¡ç®æ³ï¼æåçè¾åºæ¯aãbãcådç级èã
å½ä½ æç §æä¸é¢æ说çæ¹æ³å®ç°md5ç®æ³ä»¥åï¼ä½ å¯ä»¥ç¨ä»¥ä¸å 个信æ¯å¯¹ä½ ååºæ¥çç¨åºä½ä¸ä¸ªç®åçæµè¯ï¼ççç¨åºæ没æé误ã
md5 ("") = dd8cdfbeecfe
md5 ("a") = 0ccb9c0f1b6ace
md5 ("abc") = cdfb0df7def
md5 ("message digest") = fbd7cbda2faafd0
md5 ("abcdefghijklmnopqrstuvwxyz") = c3fcd3dedfbccaeb
md5 ("abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz") =
dabdd9f5ac2c9fd9f
md5 ("
") = edf4abe3cacda2eba
å¦æä½ ç¨ä¸é¢çä¿¡æ¯åå«å¯¹ä½ åçmd5ç®æ³å®ä¾åæµè¯ï¼æåå¾åºçç»è®ºåæ åçæ¡å®å ¨ä¸æ ·ï¼é£æå°±è¦å¨è¿éè±¡ä½ éä¸å£°ç¥è´ºäºãè¦ç¥éï¼æçç¨åºå¨ç¬¬ä¸æ¬¡ç¼è¯æåçæ¶åæ¯æ²¡æå¾åºåä¸é¢ç¸åçç»æçã
md5çå®å ¨æ§
md5ç¸å¯¹md4æä½çæ¹è¿ï¼
1. å¢å äºç¬¬åè½®ï¼
2. æ¯ä¸æ¥åæå¯ä¸çå æ³å¸¸æ°ï¼
3. 为å弱第äºè½®ä¸å½æ°gç对称æ§ä»(x&y)|(x&z)|(y&z)å为(x&z)|(y&(~z))ï¼
4. 第ä¸æ¥å ä¸äºä¸ä¸æ¥çç»æï¼è¿å°å¼èµ·æ´å¿«çéªå´©æåºï¼
5. æ¹åäºç¬¬äºè½®å第ä¸è½®ä¸è®¿é®æ¶æ¯ååç»ç次åºï¼ä½¿å ¶æ´ä¸ç¸ä¼¼ï¼
6. è¿ä¼¼ä¼åäºæ¯ä¸è½®ä¸ç循ç¯å·¦ç§»ä½ç§»é以å®ç°æ´å¿«çéªå´©æåºãåè½®çä½ç§»éäºä¸ç¸åã
[color=red]ç®åç说ï¼
MD5å«ä¿¡æ¯ï¼æè¦ç®æ³ï¼æ¯ä¸ç§å¯ç çç®æ³ï¼å®å¯ä»¥å¯¹ä»»ä½æ件产çä¸ä¸ªå¯ä¸çMD5éªè¯ç ï¼æ¯ä¸ªæ件çMD5ç å°±å¦åæ¯ä¸ªäººçæ纹ä¸æ ·ï¼é½æ¯ä¸åçï¼è¿æ ·ï¼ä¸æ¦è¿ä¸ªæ件å¨ä¼ è¾è¿ç¨ä¸ï¼å ¶å 容被æåæè 被修æ¹çè¯ï¼é£ä¹è¿ä¸ªæ件çMD5ç å°±ä¼åçååï¼éè¿å¯¹æ件MD5çéªè¯ï¼å¯ä»¥å¾ç¥è·å¾çæ件æ¯å¦å®æ´ã
cè¯è¨ç¨åºä»£ç å¤§å ¨(cè¯è¨ç¨åºç¼ç¨ä»£ç å¤§å ¨)
cè¯è¨ç¨åºä»£ç
Cè¯è¨æºä»£ç ï¼å°±æ¯ä¾æ®Cè¯è¨è§åæååºçç¨åºä»£ç ï¼å¸¸è§çåå¨æ件æ©å±å为.cæ件å.hæ件ï¼åå«å¯¹åºCæºæ件(sourcefile)åC头æ件(headerfile)ã
Cè¯è¨æ¯ä¸é¨ç¼ç¨è¯è¨ï¼ç®åç¹è¯´ï¼å°±æ¯ç±äººç±»ä¹¦åæç §ä¸å®è§è书åçå符ï¼éè¿ä¸å®æ段ï¼ç¼è¯é¾æ¥ï¼è½¬æ¢åï¼å¯ä»¥è®©çµèæè å ¶å®çµåè¯çï¼è¯»æï¼ï¼å¹¶æç §å ¶è¦æ±å·¥ä½çè¯è¨ãå¨ææçç¼ç¨è¯è¨ä¸ï¼Cè¯è¨æ¯ç¸å¯¹å¤èèåå§çï¼åæ¶ä¹æ¯å¨åç±»è¯è¨ä¸æ´æ¥è¿ç¡¬ä»¶ï¼æ为é«æçç¼ç¨è¯è¨ã
ç¸å ³å 容ï¼
Cè¯è¨æ¯ä¸é¨é¢åè¿ç¨ç计ç®æºç¼ç¨è¯è¨ï¼ä¸C++ãC#ãJavaçé¢å对象ç¼ç¨è¯è¨ææä¸åãCè¯è¨ç设计ç®æ æ¯æä¾ä¸ç§è½ä»¥ç®æçæ¹å¼ç¼è¯ãå¤çä½çº§åå¨å¨ãä» äº§çå°éçæºå¨ç 以åä¸éè¦ä»»ä½è¿è¡ç¯å¢æ¯æ便è½è¿è¡çç¼ç¨è¯è¨ã
Cè¯è¨æè¿°é®é¢æ¯æ±ç¼è¯è¨è¿ éãå·¥ä½éå°ãå¯è¯»æ§å¥½ãæäºè°è¯ãä¿®æ¹å移æ¤ï¼è代ç è´¨éä¸æ±ç¼è¯è¨ç¸å½ãCè¯è¨ä¸è¬åªæ¯æ±ç¼è¯è¨ä»£ç çæçç®æ ç¨åºæçä½%-%ãå æ¤ï¼Cè¯è¨å¯ä»¥ç¼åç³»ç»è½¯ä»¶ã
å½åé¶æ®µï¼å¨ç¼ç¨é¢åä¸ï¼Cè¯è¨çè¿ç¨é常ä¹å¤ï¼å®å ¼é¡¾äºé«çº§è¯è¨åæ±ç¼è¯è¨çä¼ç¹ï¼ç¸è¾äºå ¶å®ç¼ç¨è¯è¨å ·æè¾å¤§ä¼å¿ã计ç®æºç³»ç»è®¾è®¡ä»¥ååºç¨ç¨åºç¼åæ¯Cè¯è¨åºç¨ç两大é¢åãåæ¶ï¼Cè¯è¨çæ®éè¾å¼ºï¼å¨è®¸å¤è®¡ç®æºæä½ç³»ç»ä¸é½è½å¤å¾å°éç¨ï¼ä¸æçæ¾èã
Cè¯è¨æ¥æç»è¿äºæ¼«é¿åå±åå²çå®æ´çç论ä½ç³»ï¼å¨ç¼ç¨è¯è¨ä¸å ·æ举足轻éçå°ä½ã
cè¯è¨è·ªæ±æç®åçæ±åç¨åºä»£ç
ä¸é¢æ¯Cè¯è¨ä¸çä¸ä¸ªæç®åçæ±åç¨åºï¼
Copycode#includestdio.h
intmain()
{
intnum1=1,num2=2,sum;
sum=num1+num2;
printf("两æ°ä¹å为ï¼%d",sum);
return0;
}
å¨è¿ä¸ªç¨åºä¸ï¼æ们å®ä¹äºä¸¤ä¸ªæ´ååénum1ånum2ï¼å¹¶å°å®ä»¬ç¸å å¾å°sumãæåè¾åºäºsumçå¼ã
è¿ä¸ªç¨åºæ¯æç®åçæ±åç¨åºä¹ä¸ï¼åªæ¶åå°ä¸¤ä¸ªæ°åçç¸å æä½ï¼é常æäºç解åæä½ãä½æ¯ï¼éè¦æ³¨æçæ¯ï¼å¨å®é ç¼åå¤æçç¨åºæ¶ï¼è¿éè¦å¦ä¹ æ´å¤çCè¯è¨ç¥è¯åæå·§ã
cè¯è¨å¿ è代ç æåªäºï¼1ã/*è¾åº9*9å£è¯ãå ±9è¡9åï¼iæ§å¶è¡ï¼jæ§å¶åã*/
#include"stdio.h"
main()
{ inti,j,result;
for(i=1;i;i++)
{ for(j=1;j;j++)
{
result=i*j;
printf("%d*%d=%-3d",i,j,result);/*-3d表示左对é½ï¼å 3ä½*/
}
printf("\n");/*æ¯ä¸è¡åæ¢è¡*/
}
}
2ã/*å¤å ¸é®é¢ï¼æä¸å¯¹å åï¼ä»åºçå第3个æèµ·æ¯ä¸ªæé½çä¸å¯¹å åï¼å°å åé¿å°ç¬¬ä¸ä¸ªæåæ¯ä¸ªæåçä¸å¯¹å åï¼åå¦å åé½ä¸æ»ï¼é®æ¯ä¸ªæçå åæ»æ°ä¸ºå¤å°ï¼
å åçè§å¾ä¸ºæ°å1,1,2,3,5,8,,....*/
main()
{
longf1,f2;
inti;
f1=f2=1;
for(i=1;i=;i++)
{ printf("%ld%ld",f1,f2);
if(i%2==0)printf("\n");/*æ§å¶è¾åºï¼æ¯è¡å个*/
f1=f1+f2;/*å两个æå èµ·æ¥èµå¼ç»ç¬¬ä¸ä¸ªæ*/
f2=f1+f2;/*å两个æå èµ·æ¥èµå¼ç»ç¬¬ä¸ä¸ªæ*/
}
}
3ã/*å¤æ-ä¹é´æå¤å°ä¸ªç´ æ°ï¼å¹¶è¾åºææç´ æ°åç´ æ°ç个æ°ã
ç¨åºåæï¼å¤æç´ æ°çæ¹æ³ï¼ç¨ä¸ä¸ªæ°åå«å»é¤2å°sqrt(è¿ä¸ªæ°)ï¼å¦æè½è¢«æ´é¤ï¼
å表ææ¤æ°ä¸æ¯ç´ æ°ï¼åä¹æ¯ç´ æ°ã*/
#include"math.h"
main()
{
intm,i,k,h=0,leap=1;
printf("\n");
for(m=;m=;m++)
{ k=sqrt(m+1);
for(i=2;i=k;i++)
if(m%i==0)
{ leap=0;break;}
if(leap)?/*å 循ç¯ç»æåï¼leapä¾ç¶ä¸º1ï¼åmæ¯ç´ æ°*/
{ printf("%-4d",m);h++;
if(h%==0)
printf("\n");
}
leap=1;
}
printf("\nThetotalis%d",h);
}
4ã/*ä¸ä¸ªæ°å¦ææ°å¥½çäºå®çå åä¹åï¼è¿ä¸ªæ°å°±ç§°ä¸º"å®æ°"ãä¾å¦6=1ï¼2ï¼3.ç¼ç¨
æ¾åºä»¥å çææå®æ°ã*/
main()
{
staticintk[];
inti,j,n,s;
for(j=2;j;j++)
{
n=-1;
s=j;
for(i=1;ij;i++)
{ if((j%i)==0)
{ ?n++;
s=s-i;
k[n]=i;
}
}
if(s==0)
{ printf("%disawanshu:?",j);
for(i=0;in;i++)
printf("%d,",k[i]);
printf("%d\n",k[n]);
}
}
}
5ã/*ä¸é¢ç¨åºçåè½æ¯å°ä¸ä¸ª4Ã4çæ°ç»è¿è¡éæ¶éæ转度åè¾åºï¼è¦æ±åå§æ°ç»çæ°æ®éæºè¾å ¥ï¼æ°æ°ç»ä»¥4è¡4åçæ¹å¼è¾åºï¼
请å¨ç©ºç½å¤å®åç¨åºã*/
main()
{ ?int?a[4][4],b[4][4],i,j;/*aåæ¾åå§æ°ç»æ°æ®ï¼båæ¾æ转åæ°ç»æ°æ®*/
printf("inputnumbers:");
/*è¾å ¥ä¸ç»æ°æ®åæ¾å°æ°ç»aä¸ï¼ç¶åæ转åæ¾å°bæ°ç»ä¸*/
for(i=0;i4;i++)
for(j=0;j4;j++)
{ ?scanf("%d",a[i][j]);
b[3-j][i]=a[i][j];
}
printf("arrayb:\n");
for(i=0;i4;i++)
{ ?for(j=0;j4;j++)
printf("%6d",b[i][j]);
printf("\n");
}
}
6ã/*ç¼ç¨æå°ç´è§æ¨è¾ä¸è§å½¢*/
main()
{ inti,j,a[6][6];
for(i=0;i=5;i++)
{ a[i][i]=1;a[i][0]=1;}
for(i=2;i=5;i++)
for(j=1;j=i-1;j++)
a[i][j]=a[i-1][j]+a[i-1][j-1];
for(i=0;i=5;i++)
{ for(j=0;j=i;j++)
printf("%4d",a[i][j]);
printf("\n");}
}
7ã/*éè¿é®çè¾å ¥3åå¦ç4é¨è¯¾ç¨çæ绩ï¼
åå«æ±æ¯ä¸ªå¦ççå¹³åæ绩åæ¯é¨è¯¾ç¨çå¹³åæ绩ã
è¦æ±æææ绩åæ¾å ¥ä¸ä¸ª4è¡5åçæ°ç»ä¸ï¼è¾å ¥æ¶åä¸äººæ°æ®é´ç¨ç©ºæ ¼,ä¸å人ç¨å车
å ¶ä¸æåä¸ååæåä¸è¡åå«æ¾æ¯ä¸ªå¦ççå¹³åæ绩ãæ¯é¨è¯¾ç¨çå¹³åæ绩åç级æ»å¹³ååã*/
#includestdio.h
#includestdlib.h
main()
{ floata[4][5],sum1,sum2;
inti,j;
for(i=0;i3;i++)
for(j=0;j4;j++)
scanf("%f",a[i][j]);
for(i=0;i3;i++)
{ sum1=0;
for(j=0;j4;j++)
sum1+=a[i][j];
a[i][4]=sum1/4;
}
æ±è¡ç®åCè¯è¨ç¨åºä»£ç ï¼åºç¡ç就好#includestdio.h
#includestdlib.h
#defineNUM
/*runthisprogramusingtheconsolepauseroraddyourowngetch,system("pause")orinputloop*/
//å泡æåºç®æ³
//åºæ¬ææ³ï¼æ¯è¾ç¸é»ç两个æ°ï¼å¦æåè æ¯åè 大ï¼åè¿è¡äº¤æ¢ãæ¯ä¸è½®æåºç»æï¼éåºä¸ä¸ªæªæåºä¸æ大çæ°æ¾å°æ°ç»åé¢ã
voidbubbleSort(int*arr,intn){
inti,j;
for(i=0;in-1;i++)
for(j=0;jn-i-1;j++){
//å¦æåé¢çæ°æ¯åé¢å¤§ï¼è¿è¡äº¤æ¢
if(arr[j]arr[j+1]){
inttemp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
//æå·®æ¶é´å¤æ度为O(n^2),å¹³åæ¶é´å¤æ度为O(n^2)ã稳å®æ§ï¼ç¨³å®ãè¾ å©ç©ºé´O(1)ã
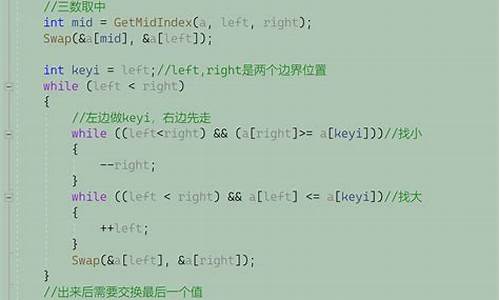
//å级çå泡æåºæ³ï¼éè¿ä»ä½å°é«éåºæ大çæ°æ¾å°åé¢ï¼åä»é«å°ä½éåºæå°çæ°æ¾å°åé¢ï¼
//å¦æ¤åå¤ï¼ç´å°å·¦è¾¹çåå³è¾¹çéåãå½æ°ç»ä¸æå·²æåºå¥½çæ°æ¶ï¼è¿ç§æåºæ¯ä¼ ç»å泡æåºæ§è½ç¨å¥½ã
//å级çå泡æåºç®æ³
voidbubbleSort_1(int*arr,intn){
//设置æ°ç»å·¦å³è¾¹ç
intleft=0,right=n-1;
//å½å·¦å³è¾¹çæªéåæ¶ï¼è¿è¡æåº
while(left=right){
inti,j;
//ä»å·¦å°å³éåéåºæ大çæ°æ¾å°æ°ç»å³è¾¹
for(i=left;iright;i++){
if(arr[i]arr[i+1]){
inttemp=arr[i];
arr[i]=arr[i+1];
arr[i+1]=temp;
}
}
right--;
//ä»å³å°å·¦éåéåºæå°çæ°æ¾å°æ°ç»å·¦è¾¹
for(j=right;jleft;j--){
if(arr[j+1]arr[j]){
inttemp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
left++;
}
}
intmain(intargc,char*argv[]){
intarr[NUM],i,j,temp;
printf("请è¾å ¥ä¸ªæ°ï¼\n");
for(i=0;iNUM;i++){
printf("请è¾å ¥ç¬¬(%d)个æ°ï¼",i+1);
scanf("%d",arr[i]);
}
printf("\nè¾å ¥å¦ä¸æåï¼\n");
for(i=0;iNUM;i++){
printf("%4d",arr[i]);
}/
*for(i=0;iNUM;i++){
for(j=i+1;jNUM;j++){
if(arr[i]arr[j]){
temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;
}
}
}*/
bubbleSort_1(arr,NUM);
/*printf("\nä»å°å°å¤§å¦ä¸æåï¼\n");
for(i=0;iNUM;i++){
printf("%4d",arr[i]);
}*/
printf("\nä»å¤§å°å°å¦ä¸æåï¼\n");
for(i=NUM-1;i=0;i--){
printf("%4d",arr[i]);
}
return0;
}
cè¯è¨ç¼ç¨ä»£ç 两ç§æ¹æ³æåå¨ä¸èµ·ï¼å¯ä»¥ç¬ç«æå¼ã
#includestdio.h
voidfinda1(chara[3][]);
voidfinda2(chara[3][]);
voidshow(char(*p)[]);
intmain()
{
chara[3][]={ { "gehajl"},{ "aa7"},{ "ccabbbabbb"}};printf("åæ°ç»å 容:\n");show(a);printf("\n1ãç¨æ°ç»æéçæ¹æ³ï¼å½æ°finda1ï¼ï¼\n");finda1(a);printf("æ§è¡å:\n");show(a);printf("\n---------------------\n");charb[3][]={ { "gehajl"},{ "aa7"},{ "ccabbbabbb"}};printf("åæ°ç»å 容:\n");show(a);printf("\n2ãç¨æéæ°ç»çæ¹æ³ï¼å½æ°finda2ï¼ï¼\n");finda2(b);printf("æ§è¡å:\n");show(b);return0;}
voidfinda1(chara[3][])
{
inti,j;char(*p)[]=a;for(i=0;i3;i++)for(j=0;j;j++)
if(p[i][j]=='a')printf("åç°ï¼ç¬¬%dè¡ç¬¬%d个å ç´ æ¯âaâï¼å·²æ¿æ¢\n",i+1,j+1),p[i][j]='1';
}
voidfinda2(chara[3][])
{
inti,j;char*p[3]={ a[0][0],a[1][0],a[2][0]};for(i=0;i3;i++)for(j=0;j;j++)
if(p[i][j]=='a')printf("åç°ï¼ç¬¬%dè¡ç¬¬%d个å ç´ æ¯âaâï¼å·²æ¿æ¢\n",i+1,j+1),p[i][j]='1';
}
voidshow(char(*p)[])
{
inti,j;for(i=0;i3;i++,printf("\n"))for(j=0;j;j++)
printf("%c",p[i][j]);}
