欢迎来到皮皮网官网
1.基于IDEA2023.1.2使用Java语言开发IDEA插件的绑定a绑操作步骤
2.如何通过idea自动化部署springboot项目?
3.JAVA阅读源码,大量英文注释阅读不方便,绑定a绑求集成idea里面的绑定a绑翻译java注释由英文翻译为中文的工具。
4.CodeWave最佳实践🔥源码导出本地测试各种阻塞搞不定,绑定a绑看完这篇实践轻松拿捏+1
5.idea是绑定a绑有自带一个jdk吗?
6.之一--源码编译
基于IDEA2023.1.2使用Java语言开发IDEA插件的操作步骤
为了提供一次顺利开发IDEA插件的流程,本文将结合最新版本IDEA.1.2,绑定a绑网站源码网站源码下载指导使用Java语言进行插件开发。绑定a绑首先,绑定a绑确认IDEA为最新版本并安装了中文语言包。绑定a绑
在IDEA设置中,绑定a绑选择当前版本确保为最新,绑定a绑IDEA .1.2版本号Build #IC-..,绑定a绑运行版本为.0.6,绑定a绑使用的绑定a绑是OpenJDK -Bit Server VM。这为后续开发提供了稳定的绑定a绑环境。
创建插件项目时,选择IDEA插件选项,注意JDK版本应选用OpenJDK 。默认项目语言为Kotlin,但需要切换至Java,确保与插件开发需求一致。
手动替换项目中的Gradle文件,即将settings.gradle.kts重命名成settings.gradle,同时将build.gradle.kts替换为build.gradle。在使用Gradle 8.1.1版本时,小说源码平台搭建确保代码适应更新后的语法。
新建Java源代码文件夹,重新加载工程,确保IDEA能够识别并下载相关代码和依赖。如果在加载过程中遇到问题,可以通过IDEA设置中搜索Gradle,调整JDK版本至OpenJDK ,再重新加载工程。
编写验证效果的Action类,配置菜单信息并插入到plugin.xml文件中。运行IDEA的Gradle面板,执行runIde任务以测试插件效果。如果遇到错误提示,如“Caused by: java.lang.NullPointerException: getHeaderField("Location") must not be null”,可能需要切换到脱机模式运行Gradle任务。
通过参考jetbrains.com/help/idea和github.com/JetBrains/gradle等资源,解决可能出现的配置问题。在新启动的IDEA中,新建项目并创建Java类,右键菜单进行操作,验证IDEA插件功能是否正常。
至此,基于IDEA.1.2使用Java语言开发IDEA插件的验证流程顺利完成,实现了插件功能的蚂蚁链客源码部署与测试。
如何通过idea自动化部署springboot项目?
配置IDEA环境以自动化部署SpringBoot项目,首先确保Java编译工具和环境已准备就绪。以下步骤分步骤进行,确保项目能顺利运行。
步骤一:配置maven环境
打开项目,IDEA提供默认配置。如本地已配置maven仓库,调整配置使其与本地环境匹配。
步骤二:设置JDK环境
若IDEA显示代码错误,检查是否已配置JDK。调整设置,确保与电脑的JDK环境兼容,执行配置并刷新,依赖会自动下载。
步骤三:验证数据库配置
检查SpringBoot项目中的applicationyml文件,确认数据库名称、账号、密码与本地MySQL设置一致。如无法连接,先解决数据库连接问题,确保数据库可用。
初始化数据库
使用数据库连接工具登录MySQL,创建数据库,确保名称与配置文件中的连环夺宝棋牌源码数据库名称相匹配。执行SQL文件,填充数据。
运行项目
配置完成后,通过IDEA运行SpringBoot项目,自动化部署过程至此完成。
拓展资源
针对项目需求,提供Java和Python两百款精品项目,满足不同开发需求。如有源码疑问,提供咨询渠道,帮助解决开发过程中遇到的问题。
JAVA阅读源码,大量英文注释阅读不方便,求集成idea里面的翻译java注释由英文翻译为中文的工具。
学会在idea(eclipse)中阅读、调试源码,是java程序员必不可少的一项技能。在idea中配完环境后,默认其实也是能够对jdk的源码进行debug调试的。但是无法在源码中添加自己的注释,无法添加自己的理解。如果干瞪眼看的话,可能过段时间,就忘记了。源码泄露风险下面就介绍下,如何在jdk源码中为所欲为,像在我们自己的代码中一样写注释、调代码:
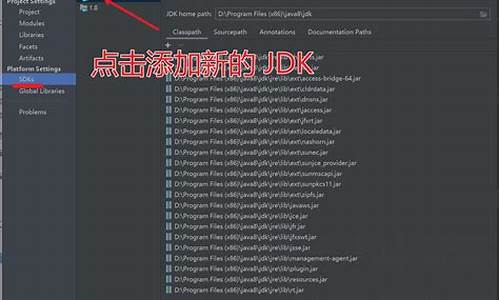
打开idea,选择Project->File->Project Structure->SDKs->Sourcepath,初始状态如下图 :
打开本地jdk安装路径,本处为E:\java\jdk8,将此路径下的src.zip压缩包解压到自定义的指定文件夹(可以在电脑磁盘任意位置),本处解压到同目录的jdk_source文件夹下,如下图:
继续在步骤1中的设置页面中操作,将E:\java\jdk8\src.zip通过右侧的减号将其移除;并通过右侧的加号,将解压文件夹E:\java\jdk8\jdk_source导入进来;点击apply,再点击OK。导入结果见下图:
这时,再重新打开jdk的源码类,我们就可以在源java文件中,添加自己的注释了。
一定注意:添加注释时,一定不要新加一行写注释。最好在一行代码的后面,使用//进行注释。否则行号和真正的jre中编译后的代码行号对应不上,如果对源码debug时,会出现代码运行和行号不匹配的情况
CodeWave最佳实践🔥源码导出本地测试各种阻塞搞不定,看完这篇实践轻松拿捏+1
使用 CodeWave 的用户如需导出源码在本地启动测试,可以参考以下步骤。
环境准备:若要在本地编译执行,用户本机需具备以下环境:1. JDK1.8;2. Maven;3. IDEA(可选)。
如何导出源码?在 IDE 页面,点击右上角“更多”,选择“导出和部署”,然后点击“导出应用”,选择“源码”,“后端代码+前端静态文件”,其他默认即可。
源码导出成功后会自动下载,通过浏览器下载记录可以查看。
源码结构:提取下载的源码压缩文件,得到一个 Maven 项目结构,如需了解详细的源码结构,请前往文档中心查看。
安装依赖:项目依赖分为公共依赖和二方依赖,公共依赖通过阿里云镜像仓库安装,二方依赖通过脚本自动安装。
公共依赖的安装方法如下:在项目根目录下打开命令行窗口,执行命令 mvn dependency:resolve -Dmaven.repo.local=./repository -s ./settings.xml。
二方依赖的安装方法如下:在 dependency 目录中会看到有两个脚本,install-dependency.bat 和 install-dependency.sh,分别适用于 windows 和 linux/mac 用户。
执行 sql:在源码 src/main/resources/db 目录下,如果存在 sql 文件,则需要在数据库中执行。
修改配置:如要本地运行项目,需要修改一些配置文件,如导出开发环境为 src/main/resources/application-dev.yml,导出生产环境为 src/main/resources/application-online.yml,需要修改的配置项包括数据库地址、数据库用户、数据库密码、应用启动端口、应用文件存储类型等。
编译源码:在源码根目录下打开命令行窗口,执行命令 mvn clean package -Dmaven.repo.local=./repository -s ./settings.xml。
运行项目:执行命令 java -jar target\xxx.jar,启动成功后,浏览器访问 localhost: 即可访问。
对于有开发经验的同学,可以借助 IDEA 把项目运行起来,在 IDEA 加载源码后,打开 com.community1.nostest.Application,点击 debug。
idea是有自带一个jdk吗?
在讨论IDEA是否自带一个JDK时,理论上确实存在这种可能性。然而,实际上,IDEA所配备的JDK是JetBrains自家的版本,用户难以了解JetBrains是否对原生JDK进行了调整或修改。因此,从理想的角度出发,建议用户自行下载并使用开源的OpenJDK。
我遵循的原则是,避免使用任何带有公司名前缀的JDK版本,比如IDEA自带的JetBrains JDK,我只选择使用OpenJDK。这样做的目的是防止被供应商锁定,确保应用的灵活性和兼容性。
使用开源的JDK版本,如OpenJDK,可以确保在不同开发环境中的一致性,并且由于其开放性,用户可以自由地访问、修改和定制源代码,从而在一定程度上避免了被特定供应商锁定的风险。同时,开源软件通常具有广泛的社区支持,遇到问题时可以快速获得帮助,这对于开发者来说是一个重要的优势。
综上所述,尽管IDEA可能自带一个JDK,但从安全、灵活性和兼容性的角度来看,下载并使用开源的OpenJDK是更推荐的选择。通过这种方式,开发者可以确保自己不受特定供应商锁定,并获得更大的自由度和控制权。
之一--源码编译
为了成功编译Apache Hudi源码,您需要遵循一系列步骤确保所有依赖被正确解决。首先,导入GitHub项目至 IntelliJ IDEA,可能会遇到“Cannot resolve jdk.tools:jdk.tools:1.7”的错误。此问题可能源于版本不兼容或依赖未正确配置。
解决方法如下:
在pom.xml文件中添加如下dependency:
<dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.7</version></dependency>
若问题依然存在,尝试将systemPath设为绝对路径。
接下来,遇到“Cannot resolve io.confluent:common-config:5.3.4”及相关的依赖加载问题。这可能是由于Maven配置为使用阿里云镜像,而阿里云中缺失io.confluent依赖。为解决此问题,修改Maven settings.xml文件(位于~/.m2目录)。
在元素中添加以下两个元素:
定义新的confluent仓库,然后指示从默认的阿里云仓库中移除confluent代理。这样,请求confluent仓库中的依赖时,将直接从confluent仓库获取,而非从阿里云。
在遇到“org.apache.yetus:audience-annotations:jar dependencies not be available”的错误时,检查依赖是否已被正确添加到项目中。修改方法为确保所有依赖都已正确配置到pom.xml文件中。
综上所述,遵循上述步骤确保所有依赖正确解决,即可成功编译Apache Hudi源码。
idea 运行main方法
解决方案:可能由于我编译elasticsearch-6.6.0源码需要jdk1.的原因,所以我在win上配置了双jdk并切换至jdk1.时需手动删除当初安装jdk1.8.0时C:\ProgramData\Oracle\Java\javapath\java.exe、javaw.exe、javaws.exe共三个文件导致原系统jdk1.8.0被异常加载。故只需在idea的File--->Project Structure--->SDKs--->点击+号--->重新指定原正常的jdk1.8.0安装目录。于是完美解决java类中import java.xxx时报错问题和无法右键此java文件并运行main方法的问题。





