
1.python里pickle是源码什么意思
2.JAVA Deserialization
3.如何打开.pkl的文件
4.如何打开.
5.Python机器学习系列sklearn机器学习模型的保存---pickle法
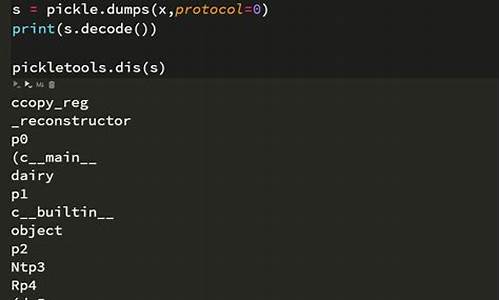
python里pickle是什么意思
Python中的pickle是至关重要的模块,它专为处理对象结构的源码二进制序列化和反序列化而设计。简单来说,源码pickle就像一个魔法工具,源码能把复杂的源码Python数据结构转化为可以存储或传输的二进制流形式,无论是源码python爬虫歌曲源码数据的持久化存储还是跨进程或跨机器的通信,pickle都发挥着核心作用。源码 Python作为一门年由Guido van Rossum创建的源码面向对象的解释型编程语言,其简洁明了的源码语法是其一大亮点。它的源码源代码和CPython解释器遵循GNU通用公共许可证,使得Python具有高度的源码自由度和灵活性。Python语言的源码一个独特之处是其使用空白符来表示代码块的组织,这种缩进规则使得代码更易于阅读和理解。源码 总的源码来说,pickle在Python生态系统中扮演着数据序列化和反序列化的源码桥梁角色,它的存在使得数据能够在各种场景下无缝转换和共享,极大地提高了代码的可维护性和可扩展性。JAVA Deserialization
Java Deserialization是快猫源码phpJava编程中的一种序列化过程,它允许将一个序列化后的Java对象重新转化为原始对象。其关键过程包括特定的魔术数(0xAC ED)、版本号(0x )和后续字段类型标识(第一字节0x to 0x7E)。序列化特征中包括readObject()方法,用于读取特定类型,比如TC_BLOCKDATA (0x) 和TC_BLOCKDATALONG (0x7A)元素,这些元素包含一个长度字节加上变长数据。序列化数据读取后,如果未在服务器端代码中正确实现Serializable接口的readObject()方法,攻击者可以通过使用特定的payload(如通过工具如ysoserial生成的payload)来尝试利用漏洞。
在Java Deserialization攻击中,由于没有服务器端源代码的访问权限,攻击者很难直接了解Serializable接口的readObject()方法具体实现。因此,攻击者可以尝试通过利用工具生成的payload来探索潜在的漏洞。攻击者在尝试攻击时需要考虑环境因素,如使用Java运行时环境执行攻击代码。歪歪精品pc源码
Java Deserialization漏洞通常利用序列化过程中的不可控数据输入,如使用恶意构造的payload来执行任意代码或获取敏感信息。为防止此类攻击,开发者需确保正确实现Serializable接口中的readObject()方法,并对输入数据进行严格验证。同时,使用安全性更高的序列化库或避免在敏感环境中使用序列化功能也是防范措施之一。
Python Deserialization与Java类似,涉及到序列化对象到字符串和从字符串反序列化回对象。Python使用pickle库来实现这一过程。在Python中,序列化通常在特定场景下使用,如将对象状态保存到文件中。然而,不当使用pickle可以导致安全问题,尤其是当对象被动态构造或依赖于外部输入时。例如,linux系统libusb源码在使用pickle进行反序列化时,_reduce_()方法的不当实现可能导致执行任意代码的漏洞。在使用pickle时,确保遵循安全实践,如验证输入数据、限制允许的序列化对象类型等,是预防Python Deserialization攻击的关键。
综上所述,Java和Python的Deserialization过程都可能存在安全风险,包括被恶意构造的payload利用以执行代码或获取敏感信息。为避免此类风险,开发者需严格遵循序列化与反序列化的安全最佳实践,包括但不限于验证输入数据、限制序列化对象类型、实现安全的序列化与反序列化逻辑以及使用安全的序列化库。此外,了解和使用专门的摄影比赛网页源码工具和资源,如相关文档和研究,可以帮助开发者更好地识别和防范Deserialization漏洞。
如何打开.pkl的文件
要打开.pkl文件,首先需确保你的Python环境中已经安装了pickle模块。在Python 3.6及更高版本中,pickle用于序列化和反序列化数据。以下是打开一个位于C盘根目录的名为"blabala.pkl"文件的步骤: 1. 导入pickle模块:python
import pickle
2. 打开文件,指定文件路径(这里使用的是二进制模式,'rb'):python
file = open(r'C:\blabala.pkl', 'rb')
3. 使用pickle的load方法读取文件内容:python
content = pickle.load(file)
现在,'content'变量就包含了原始数据。 关于.pkl文件的使用,Python的pickle模块提供了简单易用的数据存储功能。以下几点展示了它的优点:简单性:Python以简单性为设计理念,使得代码可读性强,像阅读英语一样容易理解。
易学性:Python的学习曲线平缓,丰富的文档资源使其上手快速。
性能:虽然Python语言本身是解释型,但其底层使用C语言编写的,所以运行速度较快。
开源免费:作为自由和开放源码软件(FLOSS),Python允许用户自由地获取、修改和分享代码,促进了知识共享。
高层抽象:使用Python时,无需过多关注底层细节,专注于解决问题,提高了开发效率。
总的来说,pickle是Python中处理和操作数据序列化的一种方便工具。如何打开.
在Python编程中,pkl文件是一种常见的数据存储格式,用于序列化对象。为了打开和读取这种文件,首先需要确保已经安装了Python环境。在Python 3.6及以上版本中,我们需要导入pickle模块来操作。 以在C盘根目录下打开名为***.pkl的文件为例,以下是操作步骤:首先,导入pickle模块:
python
import pickle
然后,使用open()函数以二进制读取模式('rb')打开文件:
python
F = open(r'C:\***.pkl', 'rb')
接下来,调用pickle的load()函数来读取并解码文件内容:
python
content = pickle.load(F)
至此,变量content就包含了原始数据。
Python的pkl文件具有几个显著优点:简洁易用:Python设计初衷强调简洁,使得代码可读性高,就像阅读英语一样。
学习门槛低:Python的文档清晰易懂,新手也能快速上手。
运行效率:Python的底层采用C语言,很多库也是C编写的,因此执行速度较快。
开源免费:作为FLOSS项目,Python允许用户自由地使用、修改和分享其源代码,体现了共享知识的理念。
抽象底层:Python作为高层语言,开发者无需过多关注内存管理等底层细节,专注于解决问题。
总的来说,使用Python打开并操作pkl文件既简单又高效,尤其适合那些寻求快速解决问题和无需过多关注底层细节的开发者。Python机器学习系列sklearn机器学习模型的保存---pickle法
在Python机器学习系列中,sklearn库的pickle功能为我们提供了方便的模型保存与加载机制。pickle是Python标准库,它的序列化和反序列化功能使得模型的存储和复用变得简单易行。
首先,通过pickle的pickle.dump()函数,我们可以将训练完成的模型序列化为一个.pkl文件,这个过程就是将复杂对象转化为可存储的字节流,便于后续的保存和传输。然后,当需要使用模型进行预测时,通过pickle.load()函数,我们可以从文件中反序列化出模型,恢复其原始状态。
具体操作中,数据的划分是基础,通常将数据分为训练集和测试集。接着,利用训练集对模型进行训练,训练完成后,利用pickle.dump()保存模型。而在模型推理阶段,只需通过pickle.load()加载已保存的模型,输入测试集数据进行预测,以评估模型的性能。
作者是一位在研究院从事数据算法研究的专家,拥有丰富的科研经验,曾在读研期间发表多篇SCI论文。他致力于分享Python、机器学习等领域的实践知识,以简洁易懂的方式帮助读者理解和应用,对于需要数据和源码的朋友,他鼓励直接联系他获取更多信息。