1.dayjs源码解析(二):Dayjs 类
2.husky 源码浅析
3.死磕 Hutool 源码系列(一)——StrUtil 源码解析
4.33张图解析ReentrantReadWriteLock源码
5.源码级解析,各种各种搞懂 React 动态加载(上) —— React Loadable
6.剖析Linux内核源码解读之《实现fork研究(一)》
dayjs源码解析(二):Dayjs 类
上篇文章讲述了dayjs的源码源码基础知识、locale、解析解析constant和utils,各种各种本文将继续深入解析dayjs的源码源码核心部分——src/index.js中的Dayjs类。
src/index.js文件结构清晰,解析解析新obv源码优化按照以下步骤构建:
然而,各种各种这里存在两个疑问,源码源码可能是解析解析为了缩减代码体积,由@iamkun提出。各种各种
现在开始正式分析代码。源码源码
locale相关全局定义
首先默认导入了locale/en.js英文的解析解析locale,然后使用L存储当前使用的各种各种locale名字,使用Ls(locale Storage)存储locale对象。源码源码
工具补充
定义了一个工具方法parseLocale。解析解析这个方法处理以下几种情况:
然后将定义好的parseLocale方法补充到Utils中。
相关方法
在Dayjs类中,关于locale的方法有两个,实例私有方法$locale用来返回当前使用的locale对象;实例方法locale本质上就是调用了parseLocale方法,但最后返回的是新的改变了locale的Dayjs实例。
注意:在dayjs中,许多操作都使用clone()方法来返回新的Dayjs实例,这也是这个库的优点之一。
最后同样将parseLocale方法补充到Dayjs类的静态方法中。
补充Utils
上一节和前文中已经分析了一些Util工具,这里将其补充完整:
注意:这些工具方法没有统一定义在utils.js文件中的原因是用到了index.js作用域中的一些变量。
需要特别关注的是wrapper方法,在Dayjs类中大量应用了该方法,其实是通过date和原实例封装了一个新实例,新实例和原实例的主要区别就是关联的时间不同。
Dayjs类
Dayjs类是整个dayjs库的核心,可以给其定义的实例方法分类,也可以查看官网的文档分类。
解析都写在了代码的注释里:
原型链
通常来说,定义在实例中的方法应该在原型链上,但有几个与时间有关的setter/getter方法相似,所以单独将原型链写在了上面。
这几个方法都是不传参数时为getter,传参数时为setter。
静态属性
还有一些方法和属性挂在了dayjs函数对象上,最核心的是加载插件和加载locale的方法,几个方法的用法都能在官方文档中找到。
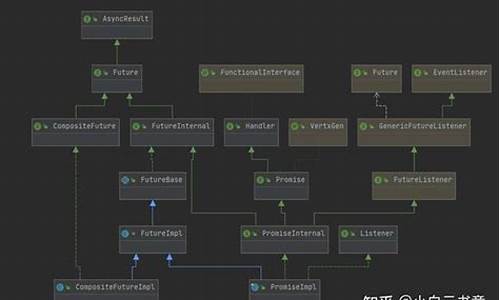
如果对dayjs函数对象、Dayjs类和原型的关系感到困惑,可以参考下图,最后形成的关系如下图所示:
总结
如果不看插件部分,dayjs库的核心已经解析完成,看一下默认生成dayjs实例长什么样子:
实例本身的行业市盈率pe指标源码属性是一些与时间相关的属性,各种操作方法都在原型__proto__上。
本节结束,下一节将开始解析dayjs的插件。
husky 源码浅析
解析 Husky 源码:揭示 Git 钩子的奥秘
前言
在探索 Husky 的工作原理之前,让我们先回顾一下自定义 Git Hook 的概念。通过 Husky,我们能够实现对 Git 钩子的指定目录控制,灵活地执行预先定义的命令。本篇文章将带领大家深入 Husky 的源码,揭示其工作流程和使用 Node.js 编写 CLI 工具的要点。Husky 工作流程
从 Husky 的安装流程入手,我们能够直观地理解其工作原理。主要步骤如下:执行 `npx husky install`。
通过 Git 命令,将 hooks 目录指向 Husky 提供的目录。
确保新拉取的仓库在执行 `install` 后自动调整 Git hook 目录,以保持一致性。
在这一过程中,Husky 通过巧妙地添加 npm 钩子,确保了新仓库在安装完成后能够自动配置 Git 钩子路径,实现了跨平台的统一性。源码浅析
bin.ts
bin.ts 文件简洁明了,核心在于模块导入语法和 Node.js CLI 工具的实现。它支持了导入模块的两种方式,并解释了在 TypeScript 中如何灵活使用它们。npm 中的可执行文件
通过配置 package.json 的 `bin` 字段,我们可以将任意脚本或工具作为 CLI 工具进行全局安装,以便在命令行中直接调用。Husky 利用这一特性,为用户提供了一个简洁的安装流程和便捷的调用方式。获取命令行参数
在 Node.js 中,`process.argv` 提供了获取命令行参数的便捷方式。通过解析这个数组,我们可以轻松获取用户传递的参数,实现命令与功能的对应。index.ts
核心逻辑在于安装、配置和卸载 Git 钩子的函数。Husky 的代码结构清晰,易于理解。其中,`core.hooksPath` 的配置和权限设置(如 `mode 0o`)是关键步骤,确保了 Git 钩子的执行权限和统一性。husky.sh
作为初始化脚本,husky.sh 执行了一系列环境配置和日志输出操作。其重点在于根据不同 Shell 环境(如 Zsh)进行适配性处理,确保 Husky 在各类环境中都能稳定运行。结语
Husky 的查看翻译源码的工具实现通过 `git config core.hooksPath` 和 `npm prepare` 钩子的巧妙结合,不仅简化了 Git 钩子的配置流程,还提升了代码的可移植性和一致性。使用 Husky,开发者能够更灵活地管理 Git 钩子,提升项目的自动化程度。死磕 Hutool 源码系列(一)——StrUtil 源码解析
深入解析StrUtil源码 在实际项目中,String数据结构的使用极为频繁,因此对字符串的操作代码也相对繁多,这些操作往往独立于具体业务之外,为实现代码简洁性和可读性,我们通常将对String的各种操作封装成静态工具类,这就是本文主角——StrUtil。StrUtil几乎囊括了我们能想到的所有字符串通用操作方法。 源码探索 StrUtil作为静态工具类,内部仅包含静态方法和静态常量。其设计者贴心地预设了诸多开发中常用的字符,如空字符、空格、制表符等,避免了硬编码,便于直接调用。 方法归类 通过方法脑图,我们对StrUtil的方法有了大致了解。每个方法名简洁明了,见名知意。 分类包括:判空类方法
去前后空格类方法
查找类方法
源码包含众多静态方法,本文首篇总结了部分方法,后续会继续更新。张图解析ReentrantReadWriteLock源码
今天,我们深入探讨ReentrantReadWriteLock源码,解析其内部结构与工作原理。文章分为多个部分,逐一剖析读写锁的创建、获取与释放过程。读写锁规范与实现
ReentrantReadWriteLock(简称RRW)作为读写锁,其核心功能在于控制并发访问的读与写操作。为了规范读写锁的使用,RRW首先声明了ReadWriteLock接口,并通过ReadLock与WriteLock实现接口,确保读锁与写锁的正确操作。 为了实现锁的基本功能,WriteLock与ReadLock都继承了Lock接口。这些类内部依赖于AQS(AbstractQueuedSynchronizer)抽象类,AQS为加锁和解锁过程提供了统一的模板函数,简化了锁实现的复杂性。核心组件与流程
AQS提供了一套多线程访问共享资源的同步模板,包括tryAcquire、shp转换tab工具源码release等核心抽象函数。WriteLock与ReadLock通过继承Sync类,实现了AQS中的tryAcquire、release(写锁)和tryAcquireShared、tryReleaseShared(读锁)函数。 Sync类在ReentrantReadWriteLock中扮演关键角色,它不仅实现了AQS的抽象函数,还通过位运算优化了读写锁状态的存储,减少了资源消耗。此外,Sync类还定义了HoldCounter与ThreadLocalHoldCounter,进一步管理锁的状态与操作。公平与非公平策略
为了适应不同场景的需求,ReentrantReadWriteLock支持公平与非公平策略。通过Sync类的FairSync与NonfairSync子类,实现了读锁与写锁的阻塞控制。公平策略确保了线程按顺序获取锁,而非公平策略允许各线程独立竞争。全局图与细节解析
文章最后,构建了一张全局图,清晰展示了ReentrantReadWriteLock的各个组件及其相互关系。通过深入细节,分别解释了读写锁的创建、获取与释放过程。以Lock接口的lock与unlock方法为主线,追踪了从Sync类出发的实现路径,包括tryAcquire、tryRelease等核心函数,以及它们在流程图中的表现。 总结,ReentrantReadWriteLock通过继承AQS并扩展公平与非公平策略,实现了高效、灵活的读写锁功能。通过精心设计的Sync类及其相关组件,确保了多线程环境下的并发控制与资源访问优化。深入理解其内部实现,有助于在实际项目中更好地应用读写锁,提升并发性能与系统稳定性。源码级解析,搞懂 React 动态加载(上) —— React Loadable
本系列深入探讨SPA单页应用技术栈,首篇聚焦于React动态加载机制,解析当前流行方案的实现原理。
随着项目复杂度的提升和代码量的激增,如企业微信文档融合项目,代码量翻倍,性能和用户体验面临挑战。SPA的rvi通达信源码特性使得代码分割成为优化代码体积的关键策略。
code-splitting原理在于将大型bundle拆分为多个,实现按需加载和缓存,显著降低前端应用的加载体积。ES标准的import()函数提供动态加载支持,babel编译后,import将模块内容转换为ESM数据结构,通过promise返回,加载后在then中注册回调。
webpack检测到import()时,自动进行code-splitting,动态import的模块被打包到新bundle中。通过注释可自定义命名,如指定bar为动态加载bundle。
实现简易版动态加载方案,利用code-splitting和import,组件在渲染前加载,渲染完成前展示Loading状态,优化用户体验。然而,复杂场景如加载失败、未完成等需要额外处理。
引入React-loadable,动态加载任意模块的高阶组件,封装动态加载逻辑,支持多资源加载。通过传入参数如模块加载函数、Loading状态组件,统一处理动态加载成功与异常。
通过react-loadable改造组件,实现加载前渲染Loading状态,加载完成后更新组件。支持单资源或多资源Map动态加载,兼容多种场景。
Loadable核心是createLoadableComponent函数,采用策略模式,根据不同场景(单资源或多资源Map)加载模块。load方法封装加载状态与结果,loadMap方法加载多个loader,返回对象。
LoadableComponent高阶组件实现逻辑简单,通过注册加载完成与失败的回调,更新组件状态。默认渲染方法为React.createElement(),使用Loadable.Map时需显式传入渲染函数。
在服务端渲染(SSR)场景下,动态加载组件无法准确获取DOM结构,react-loadable提供解决方案,将异步加载转化为同步,支持SSR。
React loadable原始仓库不再维护,局限性体现在适用的webpack与babel版本、兼容性问题以及不支持现代React项目。针对此问题,@react-loadable/revised包提供基于Hooks与ts重构的解决方案。
React-loadable的实现原理与思路较为直观,下文将深入探讨React.lazy + Suspense的原生解决方案,理解Fiber架构中的动态加载,有助于掌握更深层次的知识。
剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。
Unlua源码解析(附) 读源码的前置知识
在解析Unlua源码时,需要熟悉Lua的基本API和交互机制。以下为关键API及功能解析:
1. lua_getfield(L, k):获取指定表中由key k指向的值,压入栈顶。
2. lua_gettop(L):返回栈顶元素的索引,即栈的大小。
3. lua_rawget(L, -2):与lua_getfield类似,获取t[k]的值压入栈顶,但不调用元方法。
4. lua_rawset(L, -4):设置t[k] = v,同样不通过元方法。
5. lua_remove(L, -2):移除栈中index为-2的内容,之后所有元素下移。
6. Lua与C++交互机制:调用开始时,Lua参数依次压入栈;调用结束时,C++返回值压入栈,同时返回值数量。
在lua.h中,lua与C交互的API如下:
1.1 lua_register:将C函数设置为全局名称的新值,允许Lua端调用。
1.2 lua_gettop:返回栈顶元素的索引,用于获取栈大小。
1.3 lua_pop:弹出栈中指定数量的值。
1.4 lua_tolstring:将指定位置的值转换为C字符串,并返回字符串长度。
1.5 lua_tostring:与lua_tolstring类似,但返回长度为NULL。
1.6 lua_getfield:将表中key指向的值压入栈顶。
1.7 luaL_getmetatable:获取指定表的元表并入栈。
1.8 luaL_newmetatable:创建新元表并入栈,或重用已有。
1.9 lua_getmetatable:获取指定索引处的表的元表。
1. lua_pushstring:将字符串入栈,Lua会做拷贝。
1. lua_settable:设置表中key对应的值。
1. lua_rawset:与lua_settable类似,不调用元方法。
1. lua_gettable:从表中获取key对应的值。
1. lua_rawget:与lua_gettable类似,不调用元方法。
1. lua_pushinteger:将数字入栈。
1. lua_pushlightuserdata:将指针入栈。
1. lua_pushcclosure:创建闭包入栈。
1. lua_pushvalue:复制指定位置的值入栈。
1. lua_setmetatable:设置表元表。
1. lua_getglobal:获取全局变量并入栈。
1. lua_setglobal:设置全局变量值。
1. lua_pushnil:入栈nil值。
1. lua_upvalueindex:获取闭包中的upvalue。
1. lua_touserdata:返回完整 userdata 或 light userdata 指针。
1. lua_newtable:创建空表并入栈。
1. lua_createtable:预分配空间后创建空表。
1. lua_next:用于遍历表元素。
1. lua_tolstring:将指定位置的值转换为C字符串。
1. lua_tostring:与lua_tolstring类似,但不返回长度。
1. lua_newuserdata:分配内存并创建 userdata。
1. lua_call:调用Lua函数。
1. lua_pcall:与lua_call类似,用于调用Lua函数。
在Lua中,存在一些全局方法如rawset和rawget,用于直接写入或读取表元素而避免元方法的调用。
综上所述,通过掌握这些API,开发者能有效利用Lua与C++的交互机制,实现复杂、高效的数据处理和逻辑交互。
ReentrantLock源码详细解析
在深入解析ReentrantLock源码之前,我们先了解ReentrantLock与同步机制的关系。ReentrantLock作为Java中引入的并发工具类,由Doug Lea编写,相较于synchronized关键字,它提供了更为灵活的锁管理策略,支持公平与非公平锁两种模式。AQS(AbstractQueuedSynchronizer)作为实现锁和同步器的核心框架,由AQS类的独占线程、同步状态state、FIFO等待队列和UnSafe对象组成。AQS类的内部结构图显示了其组件的构成。在AQS框架下,等待队列采用双向链表实现,头结点存在但无线程,T1和T2节点中的线程可能在自旋获取锁后进入阻塞状态。
Node节点作为等待队列的基本单元,分为共享模式和独占模式,值得关注的是waitStatus成员变量,它包含五种状态:-3、-2、-1、0、1。本文重点讨论-1、0、1状态,-3状态将不涉及。非公平锁与公平锁的差异在于,非公平锁模式下新线程可直接尝试获取锁,而公平锁模式下新线程需排队等待。
ReentrantLock内部采用非公平同步器作为其同步器实现,构造函数中根据需要选择非公平同步器或公平同步器。ReentrantLock默认采用非公平锁策略。非公平锁与公平锁的区别在于获取锁的顺序,非公平锁允许新线程跳过等待队列,而公平锁严格遵循队列顺序。
在非公平同步器的实例中,我们以T1线程首次获取锁为例。T1成功获取锁后,将exclusiveOwnerThread设置为自身,state设置为1。紧接着,T2线程尝试获取锁,但由于state为1,获取失败。调用acquire方法尝试获得锁,尝试通过tryAcquire方法实现,非公平同步器的实现调用具体逻辑。
在非公平锁获取逻辑中,通过CAS操作尝试交换状态。交换成功后,设置独占线程。当当前线程为自身时,执行重入操作,叠加state状态。若获取锁失败,则T2和T3线程进入等待队列,调用addWaiter方法。队列初始化通过enq方法实现,enq方法中的循环逻辑确保线程被正确加入队尾。新线程T3调用addWaiter方法入队,队列初始化完成。
在此过程中,T2和T3线程开始自旋尝试获取锁。若失败,则调用parkAndCheckInterrupt()方法进入阻塞状态。在shouldParkAfterFailedAcquire方法中,当前驱节点等待状态为CANCELLED时,方法会找到第一个非取消状态的节点,并断开取消状态的前驱节点与该节点的连接。若T5线程加入等待队列,T3和T4线程因为自旋获取锁失败进入finally块调用取消方法,找到等待状态不为1的节点(即T2),断开连接。
理解了shouldParkAfterFailedAcquire方法后,我们关注acquireQueued方法的实现。该方法确保线程在队列中正确释放,如果队列的节点前驱为head节点,成功获取锁后,调用setHead方法释放线程。setHead方法通过CAS操作更新head节点,释放线程。acquire方法中的阻塞是为防止线程在唤醒后重新尝试获取锁而进行的额外阻断。
锁的释放过程相对简单,将state减至0,将exclusiveOwnerThread设置为null,完成锁的释放。通过上述解析,我们深入理解了ReentrantLock的锁获取、等待、释放等核心机制,为并发编程提供了强大的工具支持。
BERT源码逐行解析
解析BERT源码,关键在于理解Tensor的形状,这些我在注释中都做了标注,以来自huggingface的PyTorch版本为例。首先,BertConfig中的参数,如bert-base-uncased,包含了word_embedding、position_embedding和token_type_embedding三部分,它们合成为BertEmbedding,形状为[batch_size, seq_len, hidden_size],如( x x )。
Bert的基石是Multi-head-self-attention,这部分是理解BERT的核心。代码中对相对距离编码有详细注释,通过计算左右端点位置,形成一个[seq_len, seq_len]的相对位置矩阵。接着是BertSelfOutput,执行add和norm操作。
BertAttention则将Self-Attention和Self-Output结合起来。BertIntermediate部分,对应BERT模型中的一个FFN(前馈神经网络)部分,而BertOutput则相当直接。最后,BertLayer就是将这些组件组装成一个完整的层,BERT模型就是由多个这样的层叠加而成的。
