1.paddle掌握(一)paddle安装和入门
2.Keras 中的 Adam 优化器(Optimizer)算法+源码研究
3.手写数字识别训练
4.CANN训练营笔记Atlas 200I DK A2体验手写数字识别模型训练&推理
5.Pytorch笔记(十四:继承nn.Module定义MLP,GPU加速&Visdom)(1.1版本)

paddle掌握(一)paddle安装和入门
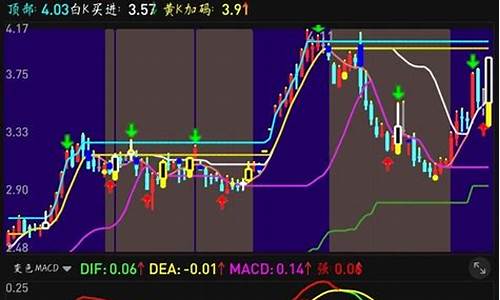
首先,我们从安装PaddlePaddle开始。官方推荐有深度学习开发经验且注重源代码和安全性的开发者使用,确保你的本地环境已安装CUDA和Anaconda。为了安装CUDA,你需要:1. 下载CUDA .7,在线社交直播源码可以从CUDA Toolkit Archive获取。
2. 打开命令窗口,通过win+R运行管理器,输入`cmd`。
3. 通过命令行查看CUDA版本。
安装PaddlePaddle后,我们来实现一个经典的深度学习入门项目——MNIST手写字符识别,这就像软件开发的“hello world”项目。LeNet模型将用于对MNIST数据集进行图像分类。MNIST数据集包含,个训练样本和,个测试样本,数据预处理已标准化,每张是x像素,值在0到1之间。网游php源码获取数据集地址:yann.lecun.com/exdb/mnist。 利用PaddlePaddle的`paddle.vision.datasets.MNIST`,我们可以加载数据并查看训练集中的一条数据,如`train_data0`的标签为[5]。 接着,我们构建LeNet模型,使用`paddle.nn`中的函数如`Conv2D`、`MaxPool2D`和`Linear`。以下是模型构建的输出。 模型训练和预测可以通过高层API实现,如`Model.fit`进行训练,`Model.evaluate`进行预测。基础API下,你需要构建训练数据加载器,定义训练函数,设置损失函数,按批处理数据,进行训练,天气通源码并在训练后用测试数据验证模型效果。Keras 中的 Adam 优化器(Optimizer)算法+源码研究
在深度学习训练中,Adam优化器是一个不可或缺的组件。它作为模型学习的指导教练,通过调整权值以最小化代价函数。在Keras中,Adam的使用如keras/examples/mnist_acgan.py所示,特别是在生成对抗网络(GAN)的实现中。其核心参数如学习率(lr)和动量参数(beta_1和beta_2)在代码中明确设置,参考文献1提供了常用数值。
优化器的本质是帮助模型沿着梯度下降的方向调整权值,Adam凭借其简单、高效和低内存消耗的特点,特别适合非平稳目标函数。它的更新规则涉及到一阶(偏斜)和二阶矩估计,以及一个很小的数值(epsilon)以避免除以零的情况。在Keras源码中,Adam类的校园跳蚤 源码实现展示了这些细节,包括学习率的动态调整以及权值更新的计算过程。
Adam算法的一个变种,Adamax,通过替换二阶矩估计为无穷阶矩,提供了额外的优化选项。对于想要深入了解的人,可以参考文献2进行进一步研究。通过理解这些优化算法,我们能更好地掌握深度学习模型的训练过程,从而提升模型性能。
手写数字识别训练
在《模式识别与图像分析》课程的二次作业中,我运用PyTorch框架构建了一个手写数字识别网络,以经典MNIST数据集作为训练和测试对象。MNIST,作为机器学习领域常用的数据集,包含约7万张x像素的手写数字,每个数字对应一个one-hot标签,用于评估算法的java免费源码识别能力。其数据处理方式是将转换为维的一维向量,输入到神经网络中。
神经网络的构建基于输入向量逐步通过多层节点,其中每个节点通过前一层的权重计算得出。最后一层为个节点的输出层,通过softmax函数将概率分配给每个数字。训练过程的目标是寻找合适的网络参数,以最大化识别准确率。具体步骤包括安装所需库,定义Net类,导入数据,评估识别正确率,以及在主函数中进行训练和测试。
在训练过程中,我们从测试集中逐批获取数据,通过网络预测结果后与实际标签对比,累加正确预测的数量,从而得到预测准确率。最终的训练结果显示了模型的识别性能,包括预测准确率和测试结果。源代码的详细内容展示了这一全过程。
CANN训练营笔记Atlas I DK A2体验手写数字识别模型训练&推理
在本次CANN训练营中,我们对华为Atals I DK A2开发板进行了详细的探索,该板子配备有4GB内存和Ascend B4 NPU,运行的是CANN 7.0环境。
首先,为了顺利进行开发,我们需要下载预编译的torch_npu,并安装PyTorch 2.1.0和torchvision 0..0。接着,配置环境变量,确保系统可以识别所需的库和文件。Ubuntu系统和欧拉系统下的安装步骤有所不同,例如,需要将opencv的头文件链接到系统默认路径。
对于ACLLite库,我们采取源码安装方式,确保动态库的识别,并在LD.so.conf.d下添加ffmpeg.conf配置。同时,设置ffmpeg的安装路径和环境变量。接着,克隆ACLLite代码仓库并安装必要的依赖。
进入模型训练阶段,我们调整环境变量来减少算子编译时的内存占用,然后运行训练脚本来启动训练过程。在训练结束后,我们生成了mnist.pt模型,并将其转换为mnist.onnx模型,以便进行在线推理。
在线推理阶段,我们使用训练得到的模型对测试进行识别。测试展示了一次实际的推理过程,其结果直观地展示了模型的性能。
对于离线推理,我们从PyTorch框架导入ResNet模型,并转换为升腾AI处理器能识别的格式。提供了下载模型和转换命令,只需简单拷贝执行。将在线推理的mnist.onnx模型复制到model目录后,我们配置AIPP,进行模型转换,然后编译样例源码并运行,得到最终的推理结果。
Pytorch笔记(十四:继承nn.Module定义MLP,GPU加速&Visdom)(1.1版本)
PyTorch笔记(十四:深度学习实践与优化) 1. 模块化网络构建在上一节中,我们手动构建了用于MNIST分类的简单网络,网络参数需自行管理。在深度学习框架中,推荐使用nn.Module继承来构建网络,这样可以隐藏参数细节,自动处理初始化问题,使网络设计更加简洁。
2. ReLU与F.relu的区分PyTorch提供了两种API风格:nn.ReLU作为类,位于torch.nn模块,以大写字母开头;F.relu作为函数,存于torch.nn.functional模块,全小写字母。理解这两种形式的区别有助于高效使用库功能。
3. GPU加速通过torch.device()函数选择GPU设备,然后在定义的网络或Tensor后面添加.to(device)即可实现数据在GPU上的运行。例如,训练和损失计算时,确保数据在GPU上进行。
4. Visdom可视化与tensorboardX相比,Visdom在可视化上更直观,尤其对图像数据支持直接使用Tensor。安装Visdom可通过pip install或从源码编译。运行visdom.server进行测试,以便实时监控训练和测试过程。
5. 训练过程可视化在自定义网络代码中加入Visdom的可视化,导入Visdom库并在训练过程中实时绘制训练曲线和验证结果,通过设置窗口和更新模式动态展示数据变化。
6. 正则化技术正则化如L2或L1,用于防止过拟合。在训练时,L2正则化通过设置optimizer的weight_decay参数实现,而L1正则化需在loss计算前手动添加。注意,L1正则化可能需要更小的系数以避免under-fitting。