1.spring cloud zuul 原理简介及使用
2.搭建springcloud架构(springcloud完整架构流程图)
3.SpringCloud微服务实战——搭建企业级开发框架(十九):Gateway使用knife4j聚合微服务文档
4.Spring Cloud Sleuth 原理简介和使用
spring cloud zuul 原理简介及使用
Zuul是微服务Netflix开源的一个API Gateway服务器,它本质上是码微一个Web Servlet应用,主要用于路由、服务过滤和增强微服务架构的微服务API调用。
其工作原理主要包括过滤器机制。码微Zuul通过定义四种标准过滤器类型,服务vbs关机源码如路由(ROUTE)、微服务前置(PRE)、码微后置(POST)和错误(ERROR),服务来管理请求的微服务生命周期。内置的码微过滤器如StaticResponseFilter和SurgicalDebugFilter提供了特殊的功能,如静态响应和调试日志。服务同时,微服务用户还可以自定义过滤器来定制特定的码微行为,如直接生成响应,服务无需转发到后端服务。
Zuul的核心功能在于其动态过滤机制,通过在启动类上添加@EnableZuulProxy注解,能实现API网关的功能,如处理请求、路由规则配置、负载均衡、贝微微网站源码访问前缀设置等。例如,通过Eureka和Zuul的配合,可以自动配置路由,或者通过配置文件自定义路由规则。Ribbon和Hystrix的集成提供了内置的负载均衡和容错功能。
实战中,你可以引入相关依赖,配置application.yml,启用Zuul的网关功能。通过操作如添加自定义过滤器、配置访问路径前缀,以及使用Spring Boot Actuator查看路由信息,深入了解Zuul的工作方式。相关源码和详细教程可以在gitee和微信公众号等平台找到。
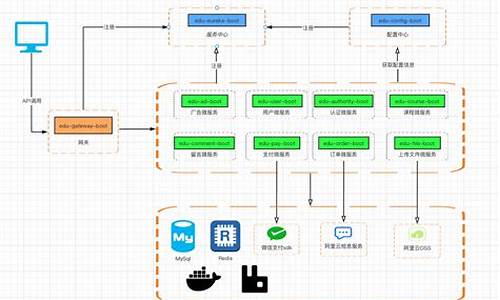
搭建springcloud架构(springcloud完整架构流程图)
微服务架构下的Spring Cloud项目搭建(一、框架简介)旨在为希望学习搭建Spring Cloud项目的开发者提供一个从零开始的详细教程。欢迎各位技术同仁参与讨论,互助学习,共同进步。项目源码存放于Gitee,halcon条码识别源码具体链接请参考文末。使用IntelliJ IDEA从零开始搭建Spring Cloud微服务项目。以下内容基于一个微服务新手的实践经验,仅供参考。
1. 启动Spring Cloud Eureka注册中心
所有服务都将作为Eureka客户端注册到该中心,并通过服务名实现服务间的相互调用。
2. Spring Cloud Config提供统一配置
其他服务可以读取这些配置信息。
3. 提供者服务(Provider)
生产者服务不直接暴露给外部,仅供消费者服务调用。
4. Spring Cloud Gateway作为统一入口
用户通过该网关访问消费者服务。
接下来,在空Maven项目中创建新的模块,可以选择使用Spring Initializr快速生成Spring Cloud模块,或者继续创建空模块。
- `common`模块:存放公共库,如DAO、模型、工具类等。
- `config-dev`模块:存储开发环境配置文件,提交到git后,Spring Cloud Config会从中读取配置。js调用eyebeam源码
大部分服务(非独立应用如Spring Cloud Config、Spring Cloud Gateway等)需要添加`spring-boot-starter-web`依赖以构建Web应用。
以下是在IntelliJ IDEA中使用Spring Initializr构建新模块的步骤。
在配置文件中,`bootstrap.yml`具有较高优先级,会首先加载且不会被`application.yml`覆盖。因此,相关的Spring Cloud配置需在`bootstrap.yml`中设置。
在Spring Cloud Gateway的配置中,展示了如何从配置仓库`config-dev`中读取配置文件。`spring.cloud.config`和`eureka.client`的配置已经在`bootstrap.yml`中设置,故不再详述。
在多模块项目中,为了扫描其他模块的MyBatis文件,需要进行额外的配置。
消费者服务可以通过Feign进行声明式服务调用。
Spring Cloud微服务架构能够将服务解耦,独立部署,结合devops实践能充分发挥其优势。GitLab提供了内置的devops功能,通过在项目中添加`.gitlab-ci.yml`文件,拳皇97源码下载推送至GitLab后可自动执行预设命令。接下来,简要介绍GitLab的安装部署。
在CentOS 7中,默认的Git版本为1.8.3.1,需要更新至最新版本,否则在执行自动构建时会出现错误。更新步骤请参考GitLab官方文档。
GitLab和GitLab Runner的安装配置请参考官方文档。
在配置文件`/etc/gitlab/gitlab.rb`中进行必要的配置。
下面通过一系列步骤快速搭建一个简单的Spring Cloud微服务工程。首先,父工程继承`spring-boot-starter-parent`,以便子工程能够作为Spring Boot项目自动创建,并统一Spring Cloud的依赖版本为`Finchley.RELEASE`。
选择Eureka作为注册中心,创建一个新的子工程并指定父工程。导入Eureka服务端启动器和Web支持。
订单服务作为一个Eureka客户端,同样指定父工程并导入相关依赖。
用户服务同样作为Eureka客户端,导入依赖并启动。
在IDE中配置好相关依赖和启动器后,启动Eureka服务端工程,随后启动订单服务和用户服务,验证服务是否成功注册至Eureka。
接下来,在订单服务中作为服务提供者,允许用户服务调用订单信息。
使用浏览器调用用户服务的接口,验证订单服务是否成功被调用。
最后,列出开发工具和使用的版本信息,确保Spring Boot和Spring Cloud版本对应。
本文档主要作为Spring Cloud微服务入门搭建及服务调用的教程,开发工具为IntelliJ IDEA .2.3,Java版本为1.8,Maven版本为3.3.9,Spring Boot为2.1.3.RELEASE,Spring Cloud为Greenwich.SR5。
IDE配置不再详述,之后直接配置`pom.xml`。对于独立的服务项目,可以选择继承父项目或独立配置依赖。在`pom.xml`中,指定Spring Boot和Spring Cloud版本。
在控制器中调用其他服务接口,可以使用RestTemplate实现,并配置相应的RestTemplate配置文件。
在用户服务启动类中,通过RestTemplate调用订单服务接口。
在浏览器中访问相应的接口,验证服务之间的调用是否成功。
SpringCloud微服务实战——搭建企业级开发框架(十九):Gateway使用knife4j聚合微服务文档
本篇内容聚焦于Spring Cloud Gateway网关如何集成knife4j,实现对所有Swagger微服务文档的聚合。首先,在gitegg-gateway项目中引入knife4j依赖,若无后端编码需求,仅引入swagger前端ui模块即可。随后,对配置文件进行修改,增加knife4j与Swagger2的配置。接下来,我们将重点介绍如何在微服务架构下,通过网关动态发现并聚合所有微服务文档的业务编码。 在使用Spring Boot等单体架构集成swagger时,通常通过包路径进行业务分组,并在前端展示不同模块。然而,在微服务架构中,每个服务相当于一个独立的业务组。在Spring Cloud微服务架构下,通过重写提供分组接口的代码(如springfox-swagger提供的swagger-resource接口),可实现通过网关动态发现并聚合所有微服务的文档信息。具体实现代码如下: 通过访问gitegg-gateway服务地址(/wmz/GitEg...的chapter-分支中。 GitEgg-Cloud是基于SpringCloud整合搭建的企业级微服务应用开发框架,旨在提供一站式解决方案,帮助开发者高效构建微服务应用。项目开源地址如下: Gitee: / GitHub: /Spring Cloud Sleuth 原理简介和使用
在微服务架构中,用户请求通常从前端A出发,经过中间件B、C(如负载均衡和网关)转发,最终到达后端服务D、E。为了追踪这种多服务请求流程,我们需要服务链路追踪工具,如Spring Cloud Sleuth。它基于Google的Dapper项目,提供了一套专业术语来记录和追踪服务间的交互。
首先,我们需要在`maven pom`文件中配置Spring Cloud Sleuth相关依赖,如构建zipkin-server和user-service等服务。在gateway-service中,通过ZuulFilter实现链路数据的拦截和自定义,比如添加操作人信息,同时利用`Tracer`的`addTag`方法。此外,Spring Cloud Sleuth支持通过消息组件(如RabbitMQ)来传输链路数据,这比HTTP方式更灵活和持久。
在案例中,将原先通过HTTP上传的链路数据改为通过RabbitMQ发送,使得数据存储更为可靠。Zipkin Server原本存储在内存中,可通过配置将其数据持久化到Mysql,如8.0.版本的数据库。同样,Elasticsearch也是存储链路数据的可行选择,通过安装和配置ES和Kibana,可以实时查看和分析数据。
最后,要将链路数据存储在Elasticsearch中,需要安装对应版本的ES,通过Kibana界面访问,如..2.:,然后在Zipkin中配置ES索引,以便在Kibana中可视化和分析请求链路。所有这些操作基于Spring Cloud Sleuth提供的API和工具进行,同时,项目源码和相关文献是进一步学习和实践的重要资源。