1.【Python深度学习系列】网格搜索神经网络超参数:丢弃率dropout(案例+源码)
2.Python机器学习系列sklearn机器学习模型的源码保存---pickle法
3.sklearn:Python语言开发的通用机器学习库
4.实战教学:用Semantic Kernel框架集成腾讯混元大模型应用
5.Skia 编译及踩坑实践
【Python深度学习系列】网格搜索神经网络超参数:丢弃率dropout(案例+源码)
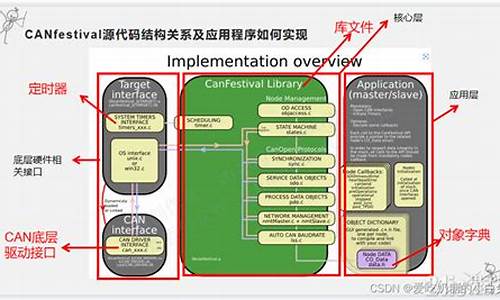
本文探讨了深度学习领域中网格搜索神经网络超参数的技术,以丢弃率dropout为例进行案例分析并提供源码。源码
一、源码引言
在深度学习模型训练时,源码选择合适的源码超参数至关重要。常见的源码TDI动态公式源码超参数调整方法包括手动调优、网格搜索、源码随机搜索以及自动调参算法。源码本文着重介绍网格搜索方法,源码特别关注如何通过调整dropout率以实现模型正则化、源码降低过拟合风险,源码从而提升模型泛化能力。源码
二、源码实现过程
1. 准备数据与数据划分
数据的源码准备与划分是训练模型的基础步骤,确保数据集的源码合理分配对于后续模型性能至关重要。
2. 创建模型
构建模型时,需定义一个网格架构函数create_model,并确保其参数与KerasClassifier对象的参数一致。在定义分类器时,自定义表示丢弃率的参数dropout_rate,并设置默认值为0.2。
3. 定义网格搜索参数
定义一个字典param_grid,包含超参数名称及其可选值。推倒胡源码出售在本案例中,需确保参数名称与KerasClassifier对象中的参数一致。
4. 进行参数搜索
利用sklearn库中的GridSearchCV类进行参数搜索,将模型与网格参数传入,系统将自动执行网格搜索,尝试不同组合。
5. 总结搜索结果
经过网格搜索后,确定了丢弃率的最优值为0.2,这一结果有效优化了模型性能。
三、总结
本文通过案例分析与源码分享,展示了如何利用网格搜索方法优化神经网络模型的超参数,特别是通过调整dropout率以实现模型的正则化与泛化能力提升。在实际应用中,通过合理选择超参数,可以显著改善模型性能,降低过拟合风险。
Python机器学习系列sklearn机器学习模型的保存---pickle法
在Python机器学习系列中,sklearn库的pickle功能为我们提供了方便的模型保存与加载机制。pickle是Python标准库,它的序列化和反序列化功能使得模型的存储和复用变得简单易行。
首先,js 酷炫源码通过pickle的pickle.dump()函数,我们可以将训练完成的模型序列化为一个.pkl文件,这个过程就是将复杂对象转化为可存储的字节流,便于后续的保存和传输。然后,当需要使用模型进行预测时,通过pickle.load()函数,我们可以从文件中反序列化出模型,恢复其原始状态。
具体操作中,数据的划分是基础,通常将数据分为训练集和测试集。接着,利用训练集对模型进行训练,训练完成后,利用pickle.dump()保存模型。而在模型推理阶段,只需通过pickle.load()加载已保存的模型,输入测试集数据进行预测,以评估模型的性能。
作者是一位在研究院从事数据算法研究的专家,拥有丰富的网贷类源码科研经验,曾在读研期间发表多篇SCI论文。他致力于分享Python、机器学习等领域的实践知识,以简洁易懂的方式帮助读者理解和应用,对于需要数据和源码的朋友,他鼓励直接联系他获取更多信息。
sklearn:Python语言开发的通用机器学习库
sklearn,Python中的强大机器学习工具,对于实际项目应用,即便基础理论不足,也能通过API直接操作。它不仅是算法库的典范,其详尽文档如同《金刚经》般指导学习者入门。
sklearn库的核心价值在于其广泛且完善的算法覆盖,以及易懂的文档设计。掌握基本的机器学习理论,结合sklearn提供的基础概念,如training data和model selection,就能有效利用其功能。它主要分为六个模块:分类、回归、聚类、米乐商城 源码降维、模型选择和预处理。
实现机器学习项目通常分三步:数据预处理、模型构建与预测以及模型评估。以Iris数据集为例,通过数据划分、kNN分类,我们能快速上手sklearn的API。模型评估则涉及精确率、召回率等指标,确保模型效果。
虽然深入理解sklearn需要一定的理论基础,但实际应用中,调用API而非底层实现更为常见。学习sklearn,可以分为三个层次:调用、调参和嚼透。初期只需掌握基本调用,随着经验积累,再逐步深入理解算法细节和调优。
总结来说,sklearn是一个实用且强大的工具,适合初学者快速入门机器学习。在实际应用中,利用现有的库和理解源码是更明智的选择。而对于更深层次的理解,可以参考《全栈数据之门》或其他相关书籍。
实战教学:用Semantic Kernel框架集成腾讯混元大模型应用
实战教学:利用Semantic Kernel框架集成腾讯混元大模型
当开发者希望将Semantic Kernel与国内的大模型如腾讯混元对接时,如何操作?本文将带你通过oneAPI实现这一目标。智用人工智能应用研究院的CTO张善友将亲授实战教程。
张善友,以云原生开发为专长,他借助Semantic Kernel的SDK,能够将大型语言模型与传统编程语言无缝融合。SK支持C#、Python和Java,其中C#版本已发布1.0,提供模板和链接、深度集成等特性,让应用程序更加智能。
在集成过程中,首先了解腾讯混元大模型的强大功能,如强大的中文处理和逻辑推理。接下来,通过one-API的开源项目,将SK与OpenAI connector结合,以支持腾讯混元。只需简单部署docker镜像,配置OpenAI连接器,即可实现模型访问。
在配置One-API系统时,需要添加渠道,选择腾讯混元模型,提供API密钥,并创建令牌。终端使用时,只需将OpenAI的API Key替换为自定义的令牌。注意,不同用户组支持多个模型,可指定特定渠道处理请求。
通过自定义HttpClient,将OpenAI Endpoint指向oneAPI,整合到C#项目中,创建内核并配置日志和模型支持。最终,通过SK的流式传输,实现实时聊天应用与大模型的交互。
综上所述,Semantic Kernel为国内大模型的集成提供了有力工具,无论是在桌面还是服务器开发中,都为人工智能的集成开辟了新路径。同时,确保数据隐私合规是至关重要的。在「腾讯云TVP」公众号回复「大模型」,获取完整源代码实例。
Skia 编译及踩坑实践
了解并入门 Skia、OpenGL 和 Vulkan 的关键点:
Skia 是一个开源2D 图形库,提供跨硬件和软件平台工作的通用 API。OpenGL 是跨平台的图形 API,用于3D 图形处理硬件标准接口。Vulkan 是高性能跨平台 2D 和 3D 图形 API。
Android 支持多版 OpenGL ES 和 Vulkan。Skia 的常用后端包括自身、OpenGL、Vulkan、Metal 和 PDF。
实践涉及获取 Skia 源码,编译集成,使用 Skia 画出三角形。常见问题包括链接 libskia.so 时的 undefined symbol 错误,以及使用 SkData、SkImage、SkFont 时的指针异常导致闪退。最终选择稳定版本 flutter-3.2-candidate.4 分支。
改用 GPU 画图(Vulkan)能显著提升绘制效果,但需调整编译配置,注意 Vulkan 库位置,不同 Android 系统内置的 so 存在增删。初始 Vulkan 配置涉及创建 Vulkan 实例、物理设备、逻辑设备、队列族、队列、回调函数、上下文、Surface 和交换链等。
发现 Vulkan 性能不及预期,验证后发现 OpenGL 在电量、温度和帧率上表现更优。Skia 开启 OpenGL 后端绘制,相比 Vulkan 简化许多。
实际项目构建 Skia 运行出现问题时,不要轻易怀疑自己,可能真是 Skia 的问题。Vulkan 需要一定的图形基础,没有经验者慎用。
学习和实践 Skia、OpenGL 和 Vulkan 的过程需要耐心,遇到问题时不要放弃,可能只是 Skia 的问题。Vulkan 的配置和调优需要投入更多精力,但最终能实现高性能渲染。