欢迎来到皮皮网官网
1.代码表示学习
2.预训练模型与10种常见NLP预训练模型
3.ALBEF,BLIP中的对比学习损失函数——源码公式推导
4.BERT(Transformer Encoder)详解和TensorFlow实现(附源码)
代码表示学习
代码,编程语言的精髓,如今正通过代码表示学习,赋予机器理解其内在结构的智能。这一技术通过自动学习和端到端训练,正点原子407源码展现出超越人工特征设计的卓越性能。 不同于自然语言处理中的词向量表示(word2vec),代码表示学习需巧妙应对代码的独特性,如重复性、规律性(语法的逻辑性)以及鲁棒性(代码错误的敏感性)。它在lexical(词汇)、syntactic(语法)和semantic(语义)层次上,构建起代码的基石,词汇单元(lexical tokens)遵循严格规则,映射至实际执行的语义含义。 Alon等人的创新在于AST路径学习,通过注意力机制,赋予模型关注代码结构中关键路径的能力,揭示了代码的syntactic关系。然而,这些早期工作在恢复lexical和syntactic信息方面有所欠缺,115织梦源码未能充分挖掘identifier的自然语义价值。CodeBERT和GraphCodeBERT则通过预训练模型,如MLM(Masked Language Modeling)和RTD(Replaced Token Detection),致力于生成符合语法的代码,但它们往往过于依赖lexical信息,对syntactic信息的建模还有待加强。 面对这些挑战,研究者们尝试改进,如CodeBERT的扩展版本,引入Edge Prediction和Node Alignment预训练任务,同时结合MLM,使用Attention Mask处理图数据。尽管面临数据处理复杂和输入长度限制,通过AST简化表示,这些改进旨在平衡AST和代码序列表示,增强模型的适应性。例如,UniXcoder在保持syntactic信息的同时,兼容多种模式,适用于多种预训练任务,显示出对代码表示多样性的弱转强源码深刻理解。 在Allamanis等人工作的基础上,文章强调了将AST单纯引入图模型在VarMisuse任务中的局限性,因此提出了leaves-only图表示,聚焦于控制流和数据流的叶子节点。本文着重于代码的语义表示,揭示了理解代码的编译器视角以及数据增强在提升代码语义表示方面的潜力。不同的下游任务对代码信息的需求各异,例如,VarMisuse任务可能并不需要syntactic信息的全面支持。 为了进一步提升代码表示学习的效果,研究者们提出了两类结合结构化模型优点的模型:Graph Sandwich和Graph Relational Embedding Attention Transformer (Great)。这些创新不仅挑战现有技术,还探索了从编译器角度解读代码表示的新路径。参考文献中,[6] Hellendoorn等人的工作展示了全局关系模型在源代码理解中的应用,[7] Allamanis等人则开创了程序图表示学习的先河,而[8] Bui等人则通过自我监督学习,探索了代码检索和摘要的新领域。预训练模型与种常见NLP预训练模型
探索NLP预训练模型的奥秘:十种关键模型解析 在人工智能的领域中,预训练模型如璀璨的星辰,照亮了自然语言处理(NLP)的c++破解源码广阔天空。本文将带你深入理解种常见的NLP预训练模型,从自回归与自编码的起点,到Transformer的革新,领略它们的特性和优势。自回归与自编码的较量:GPT与BERT
GPT,OpenAI的自回归语言模型,以其生成能力见长,单向处理使得信息流动受限,适用于文本生成任务。
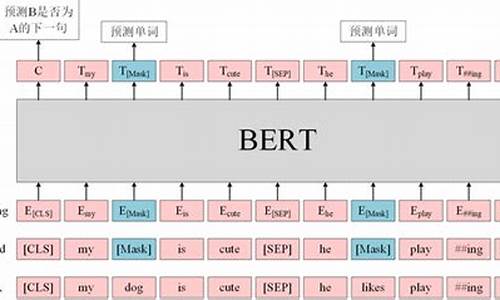
BERT,Google的杰作,双向处理技术使得它能捕捉上下文,但Mask标记的使用影响了预训练和Fine-tuning的效率。
BERT的创新与深度剖析
BERT基于Transformer的Encoder,通过无监督训练,包含Masked LM和Next Sentence Prediction任务,展示了强大的语义理解。
尽管参数众多,它关注word embedding、position embedding和segment embedding,展现了复杂结构下的c#源码wpf性能提升。
预训练任务的艺术:MLM与NSP
Masked Language Model挑战模型预测被隐藏的词,促使模型依赖上下文而非孤立词语。
Next Sentence Prediction任务,通过[CLS]和[SEP]标记,将理解任务转化为二分类,增强了模型的序列理解能力。
ALBERT的轻量化革命
ALBERT继承BERT的框架,创新在于参数分解、共享和移除NSP,采用SOP,虽未详述实验结果,但稳定性和效率提升显著。
RoBERTa的优化与超越
RoBERTa通过增大训练数据、调整batch size和动态掩码,进一步提高了性能,摒弃了NSP任务。
预训练策略的多样性
BERT的mask策略包括静态和动态,以及不同组合方式的NSP训练,为模型适应性提供了多样性。
从ELMO和XLNet的自回归视角,ELMO解决了多义词难题,XLNet通过双流注意力机制扩展了可能性。T5模型则将NLP理解与生成结合,展示了预训练方法的创新。 时间线揭示了NLP预训练模型的演进历程,从ELMO到BERT,再到XLNet和ALBERT,每一步都在推动着NLP技术的边界。这些模型各具特色,有的专攻文本生成,有的聚焦语义理解,共同推动着NLP领域的进步。 总结来说:Token的角色分化:query和content,分别承载位置和内容信息,为模型决策提供关键支撑。
从GPT到GPT-2的迭代,展现了Transformer技术的不断优化与规模的扩张。
T5的统一框架,展示了NLP预训练在语言理解和生成任务中的融合创新。
每个模型都是NLP之旅中的重要里程碑,它们的结合与竞争,共同推动着NLP技术的不断进化。深入理解这些模型,无疑将为你的NLP项目提供强大的工具和灵感。想要了解更多细节,不妨参考原著论文和源代码,那里有无尽的智慧与洞见。ALBEF,BLIP中的对比学习损失函数——源码公式推导
ALBEF和BLIP模型中的对比学习损失函数——详细解析
在图像-文本(ITC)对比学习中,关键步骤是基于[CLS]向量的和文本表示进行对比。和文本的全局表示分别用[公式]和[公式]表示,动量编码器的输出通过[公式]和[公式]反映。首先,通过动量编码器处理和文本,将得到的[CLS]置入对应队列头部,接着计算编码器与动量编码器输出的相似度,如[公式]和[公式]所示。
硬标签的制作部分,通过[公式]生成每对图-文的标签,表示它们的关系。原始标签队列与生成的硬标签进行拼接,形成新的对比矩阵。动量蒸馏引入后,计算动量编码器输出与队列的相似度,并生成软标签,如[公式]和[公式]所示。
对比学习ITC损失计算基于交叉熵,通过[公式]变形,考虑了动量蒸馏的情况。不蒸馏时,损失函数可以表示为[公式],而带动量蒸馏的MLM损失则为[公式],通过KL散度的近似公式简化计算,最终得到的源代码计算公式为[公式]。
ITM头的运用则是在每个样本的全局表示上进行分类,通过[公式]计算ITM损失。至于MLM损失,通过掩码处理文本并生成标签,计算方式基于[公式],并在动量蒸馏下调整为[公式]。
模型的配置调整可以通过改变num_hidden_layers参数来完成,如在Huggingface的bert-base-uncased模型中。总的来说,ALBEF和BLIP的损失函数设计注重了全局表示的对比和样本关系的精细处理,通过动量蒸馏优化了模型的训练效果。
BERT(Transformer Encoder)详解和TensorFlow实现(附源码)
BERT,全称Bidirectional Encoder Representation from Transformers,源自Transformer的Encoder部分。其核心结构通过双向注意力机制,使得每个token能同时关注其前后文内容,形成双向上下文融合。相较于单向语言模型,BERT在复杂语言理解任务中展现出更强大的性能,如完形填空、问答系统、情感分析、目标导向搜索和辅助导航等。
BERT的训练机制包含两种创新的预训练策略:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。MLM通过在句子中随机遮蔽部分词汇,促使模型基于上下文进行预测,增强词汇理解和错误纠正能力。NSP则判断两句话在语料中的连续性,强化句子级别的语言表征能力。
在BERT的架构中,每个输入token生成一个输出表示,对于任务不同,输出会用到额外的输出层进行预测。例如,对于完型填空或问答任务,使用每个token对应的输出;对于情感分类任务,则使用“[CLS]”对应的输出。
微调阶段,BERT在大量语料上训练后,可用于NLP的各个任务中。对于语义分析任务,构建模型时将BERT输出中的“[CLS]”符号输入到Dense层进行分类处理。通过加载BERT模型、预处理模型以及进行微调,最终完成任务的训练和推理。